







kafka运行依赖于 jdk、zookeeper,kafka可视化工具选择kafka-eagle。所以要装的组件有:jdk、zookeeper、kafka、kafka-eagle
一、安装jdk
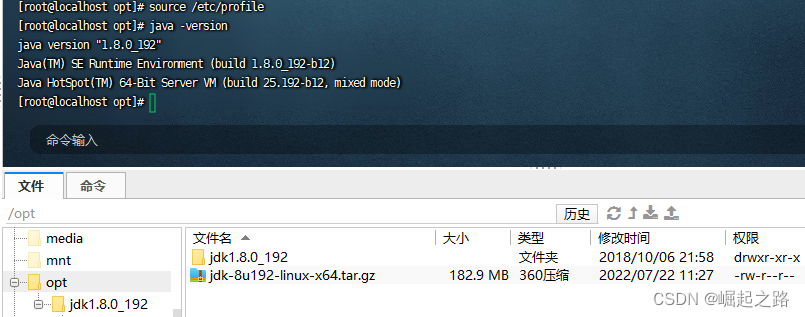
下载linux版本的jdk包,比如:jdk-8u192-linux-x64.tar.gz。
将其复制到 /opt 目录下并解压:tar -zxvf jdk-8u192-linux-x64.tar.gz

添加环境变量:vi /etc/profile 然后在末尾插入以下内容
export JAVA_HOME=/opt/jdk1.8.0_192
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$JAVA_HOME/bin:$PATH
再运行 source /etc/profile 重新加载环境变量即可,可用java -version测试jdk是否安装成功
二、安装运行zookeeper
1、下载zookeeper,下载地址:Apache ZooKeeper
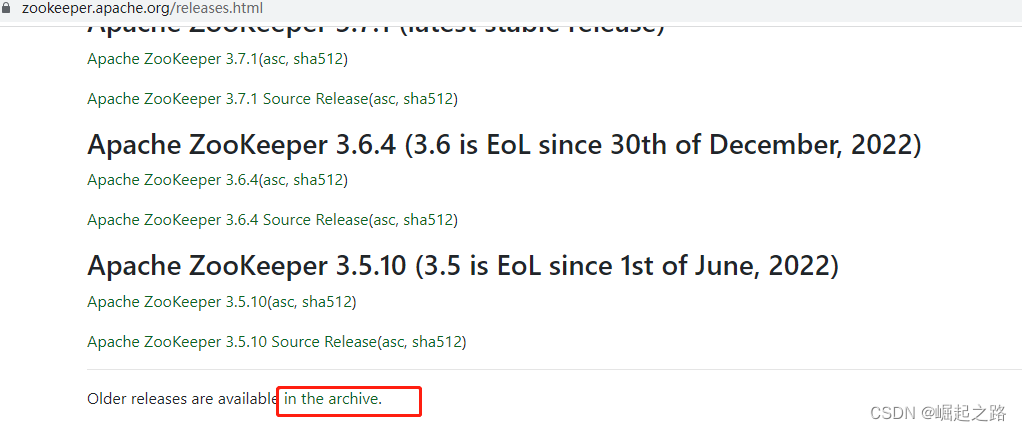

这里为了测试对接方的kafka,直接选择下载旧版本的apache-zookeeper-3.5.8-bin.tar.gz,并将之复制到/opt/zookeeper目录下。
2、在/opt/zookeeper目录下运行以下命令启动zookeeper:
tar -zxvf apache-zookeeper-3.5.8-bin.tar.gz
cd apache-zookeeper-3.5.8-bin
cp conf/zoo_sample.cfg conf/zoo.cfg
sh /opt/zookeeper/apache-zookeeper-3.5.8-bin/bin/zkServer.sh start3、检查是否启动,使用 jps -l 可以看到zookeeper启动

4、若启动失败则可以看 /opt/zookeeper/apache-zookeeper-3.5.8-bin/logs下的日志

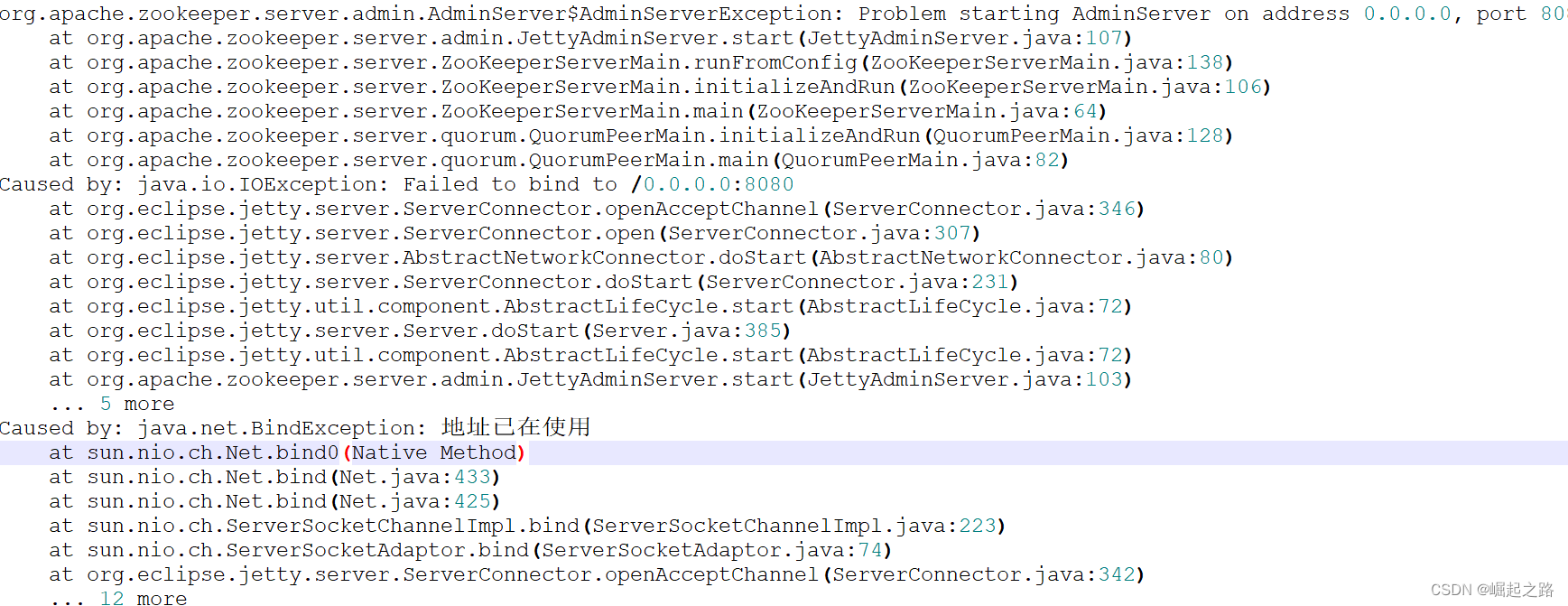
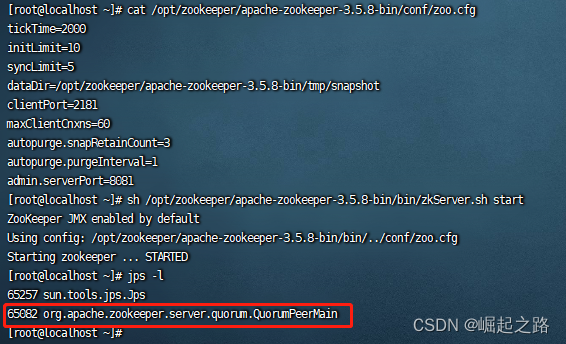
这里报8080端口被占用,就改下配置,配置文件为/opt/zookeeper/apache-zookeeper-3.5.8-bin/conf/zoo.cfg,再里面添加一行:admin.serverPort=8081,如下图所示:
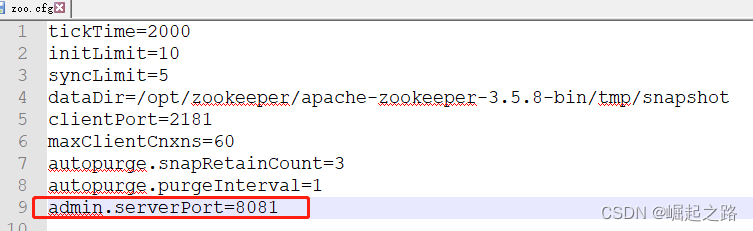
再次启动:sh /opt/zookeeper/apache-zookeeper-3.5.8-bin/bin/zkServer.sh start,用jsp -l可以看到启动成功。
若需要关闭zookeeper,运行命令:sh /opt/zookeeper/apache-zookeeper-3.5.8-bin/bin/zkServer.sh stop
三、安装运行kafka
1、下载kafka,地址:Apache Kafka

将该文件复制到 /opt/kafka 文件夹中
2、修改配置文件,在/opt/kafka目录下运行以下命令:
tar -vxzf kafka_2.11-2.4.0.tgz
vi /opt/kafka/kafka_2.11-2.4.0/config/server.properties修改server.properties如下属性:
broker.id=0
listeners=PLAINTEXT://192.168.189.128:9092
zookeeper.connect=192.168.189.128:2181
log.dirs=/opt/kafka/kafka_2.11-2.4.0/tmp/kafka-logs3、启动kafka,具体命令如下:
启动:sh /opt/kafka/kafka_2.11-2.4.0/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.11-2.4.0/config/server.properties
查看日志:cat /opt/kafka/kafka_2.11-2.4.0/logs/server.log
停止:sh /opt/kafka/kafka_2.11-2.4.0/bin/kafka-server-stop.sh
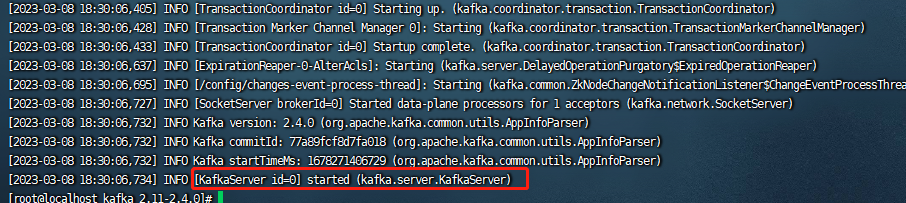
可以看到kafka启动成功
4、在当前机器/opt/kafka目录类似上述操作,再复制或解压出两个kafka包,修改配置,然后启动即可。相关命令如下:
sh /opt/kafka/kafka_2.11-2.4.0/bin/kafka-server-stop.sh
rm -fr /opt/kafka/kafka_2.11-2.4.0/logs
rm -fr /opt/kafka/kafka_2.11-2.4.0/tmp
cp -rfp /opt/kafka/kafka_2.11-2.4.0 /opt/kafka/kafka_2.11-2.4.0_1
vi /opt/kafka/kafka_2.11-2.4.0_1/config/server.properties
sh /opt/kafka/kafka_2.11-2.4.0_1/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.11-2.4.0_1/config/server.properties
cp -rfp /opt/kafka/kafka_2.11-2.4.0 /opt/kafka/kafka_2.11-2.4.0_2
vi /opt/kafka/kafka_2.11-2.4.0_2/config/server.properties
sh /opt/kafka/kafka_2.11-2.4.0_2/bin/kafka-server-start.sh -daemon /opt/kafka/kafka_2.11-2.4.0_2/config/server.properties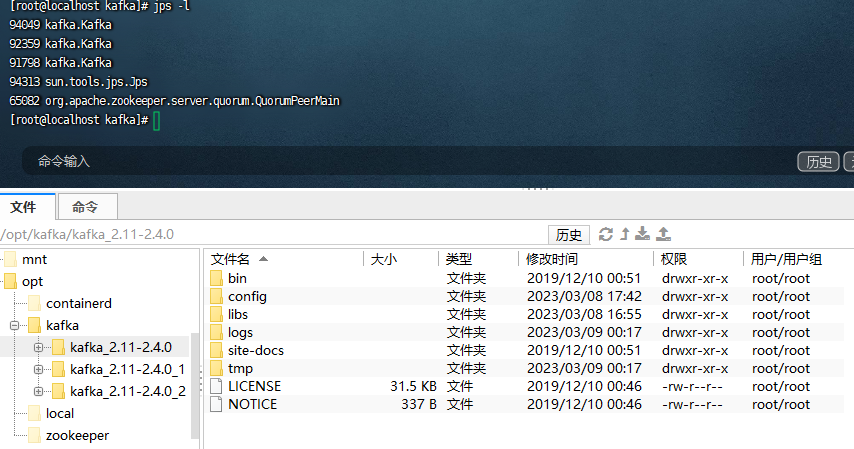
可以看到 zookeeper和3个kafka都启动了。
另外,可用zookeeper客户端查看kafka节点:
sh /opt/zookeeper/apache-zookeeper-3.5.8-bin/bin/zkCli.sh
ls /brokers/ids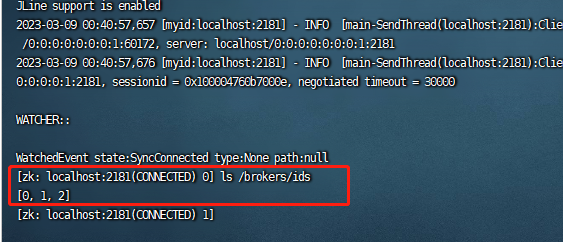
注意,关闭kafka集群,只要运行其中一个kafka的bin目录下的kafka-server-stop.sh即可,但启动,需要将这些kafka的bin目录下的kafka-server-start.sh都运行。
以上这些步骤可以说kafka已经安装完毕了,就可以用各语言的API去连接kafka了。以下步骤安装kafka可视化工具:kafka-eagle。
四、安装运行kafka-eagle
下载kafka-eagle,下载地址:https://www.kafka-eagle.org/
将下载的文件(kafka-eagle-bin-2.1.0.tar.gz)放到 /opt/kafka-eagle目录下,并解压
tar -vxzf /opt/kafka-eagle/kafka-eagle-bin-2.1.0.tar.gz -C /opt/kafka-eagle
tar -vxzf /opt/kafka-eagle/kafka-eagle-bin-2.1.0/efak-web-2.1.0-bin.tar.gz -C /opt/kafka-eagle/kafka-eagle-bin-2.1.0
vi /opt/kafka-eagle/kafka-eagle-bin-2.1.0/efak-web-2.1.0/conf/system-config.properties编辑内容如下:
efak.zk.cluster.alias=cluster1
cluster1.zk.list=192.168.189.128:2181
efak.driver=com.mysql.cj.jdbc.Driver
efak.url=jdbc:mysql://127.0.0.1:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
efak.username=root
efak.password=root可以看到需要连接mysql,我这里是直接用docker安装运行mysql的,具体命令如下:
docker run -itd --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=root mysql:5.7
2、设置环境变量:
vi /etc/profile
文件里添加如下变量:
export KE_HOME=/opt/kafka-eagle/kafka-eagle-bin-2.1.0/efak-web-2.1.0
KE_PATH=$PATH:$KE_HOME/bin
export KE_PATH
更新环境变量:
source /etc/profile
3、启动kafka-eagle:
sh /opt/kafka-eagle/kafka-eagle-bin-2.1.0/efak-web-2.1.0/bin/ke.sh start

启动成功,再访问网址:192.168.189.128:8048,账号:admin,密码:123456
可以看到页面能成功访问
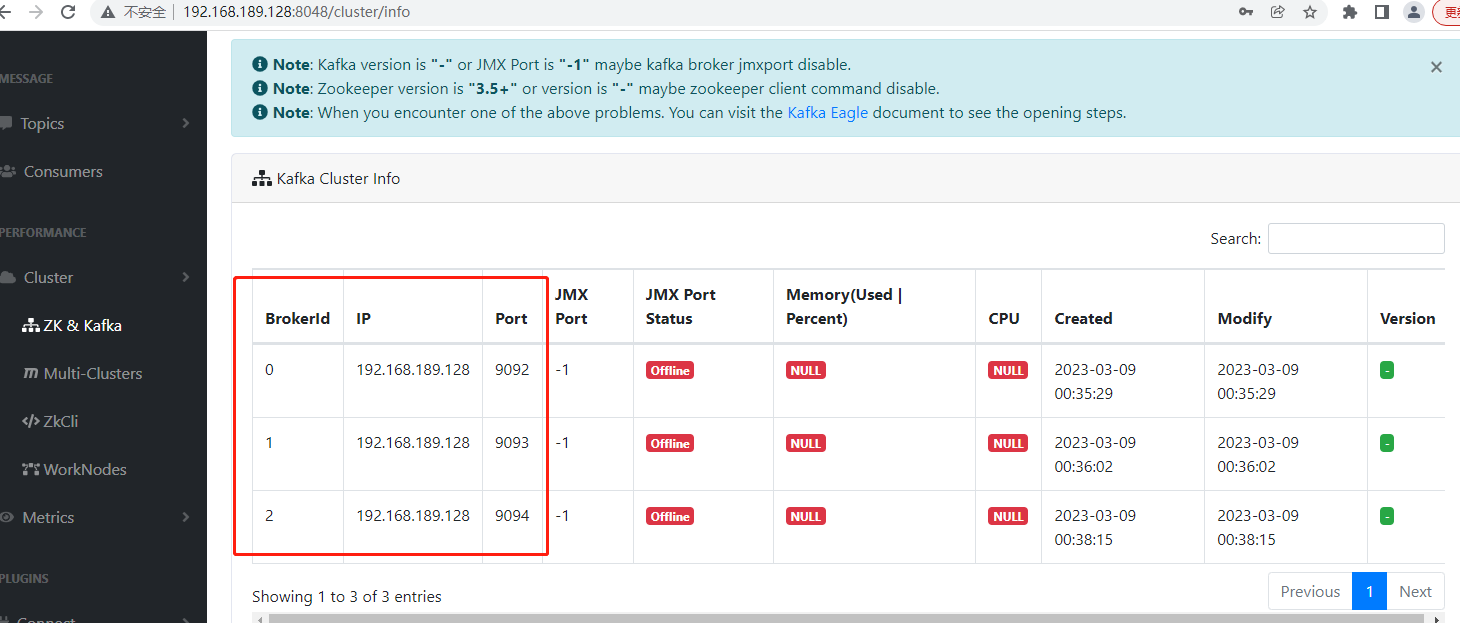
kafka集群各节点的brokerid、ip和port都可以看到。
若要关闭efak,则运行命令:sh/opt/kafka-eagle/kafka-eagle-bin-2.1.0/efak-web-2.1.0/bin/ke.sh stop

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











