







目录
1、磁盘处理时间

题解:可以画下磁盘图,具体如下:
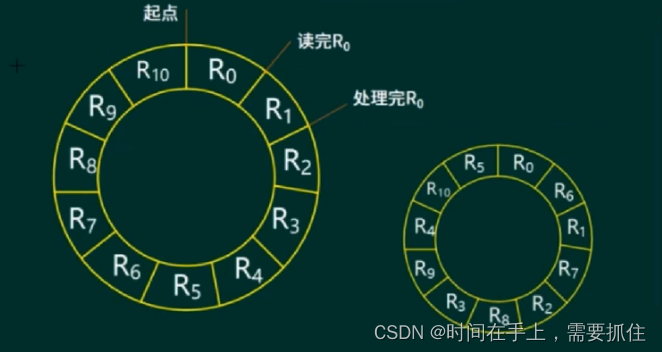
最长时间:第一个从R0开始读取,读取3ms,处理3ms,由于是单缓冲区,处理的同时无法进行读取,磁盘又会一直转动,不会等待,所以R0处理完后,磁盘到了R2的起始区,由于是按顺序处理记录,所以磁盘要转10个物理块才能到R1的起始点,处理完R1后,又到了R3起始区了,又要转10个物理块处理R2...。所以处理时间为:R0读取处理时间+(10个物理块转动时间+读取块时间+处理块时间)*10 = 3+3+(10*3+3+3)*10=6+36*10=366ms。
最短时间:最短时间就是R0处理完后刚好读取R1,依此类推。由于是单缓存区,读取和处理无法同时进行,所以最短时间需要(3+3)*11=66ms。
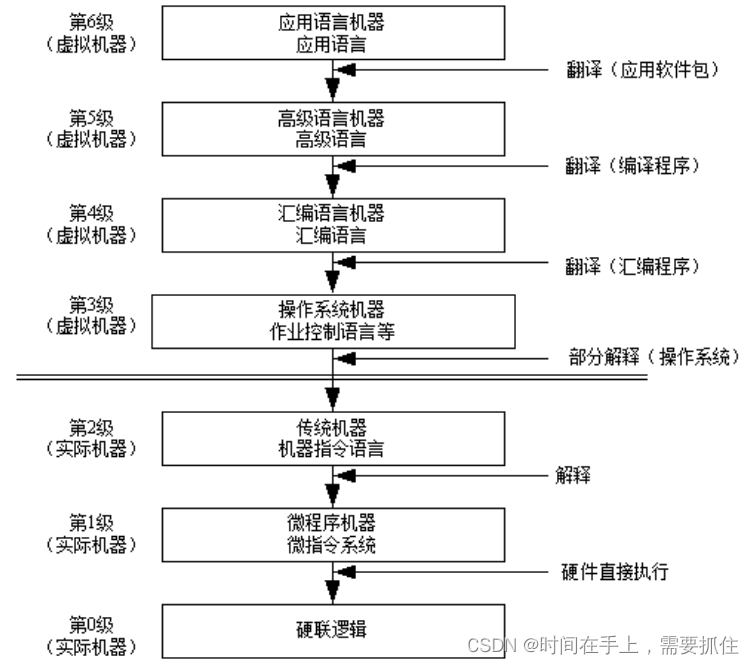
2、存储系统分级理论基础和三级存储体系

题解:第一空选B,即程序访问的局部性,即程序的循环运行数据访问会导致相同指令大量执行(Cache和主存)以及数据小范围修改(Cache和主存)。第二空选C,三级的话需要把寄存器去掉,只留下Cache、主存、外存。
3、Cache地址转化

题解:选A,硬件。主存到Cache的地址转化不需要程序或软件干预。
4、Cache地址映像冲突

题解:选B,直接>组相>全相。
5、I/O与CPU交换数据的方式叙述

题解:这里的DMA完胜中断方式,更适合快速I/O。注意优先级,CPU优先响应DMA,毕竟处理DMA更快,仅需要发送开始结束等指令即可,而中断需要保存现场再进行大量处理。
6、磁盘调度管理
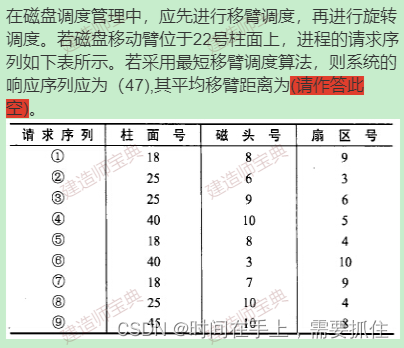
题解:这里可以看出这个磁盘有多个磁面和磁头,每个磁面(盘面)对应一个磁头,所以磁头号可以看做是盘面号。所以移臂会把所有磁头移到相同柱面上,再旋转相应磁片,让磁头能读取到磁面(盘面)上的扇区,从而让磁头读取到数据。这里采用最短移臂调度算法,即最短时间优先算法选取柱面。
最短寻找时间优先:会寻找当前柱面最近的柱面访问,直到访问完所有柱面为止,因此,磁头在柱面移动顺序为:22->25->18->40->45。因此可得出移臂距离为|22-25|+25-18|+|18-40|+|40-45|=37,共处理9个请求,平均移臂距离为:14/9=4.11。
旋转顺序:由于没有各磁头的离各扇区的初始距离或相对位置,因此没法整理旋转顺序,这里答案访问顺序是根据同柱面磁头先读最近的扇区来确定各扇区的访问顺序。
若是选择题,筛选访问顺序可以根据各柱面的顺序排序,比如:(2,3,8)先于(1,5,7)先于(4,6)先于(9),这样排下序基本可以筛选出正确答案了。
7、RAM和ROM自检

一般来将,RAM可以进行写入,所以RAM类存储器是通过写入0xAA之类的数据自检,而ROM一般不可写入,通过对其内容进行累加和校验(查看容量以及类似MD5校验)进行自检。
8、DMA数据通路

题解:CPU与外设不能直接通数据,因为太慢了,DMA是控制IO,即主存和外设,DMA接手IO控制后,CPU会让出总线控制权。
9、多处理机系统代码并行性

题解:多处理机系统是有CPU工作,一般是MIMD(多指令集多数据流)结构,在多处理机系统中,提高程序并行性的关联是把任务分解成可同时操作的进程(作业)。就好比大数据分析,一个任务多个进程处理。所以选C,作业级和任务级。
10、总线特性

题解:总线的特性有:物理特性、功能特性、电气特性、时间特性。
物理特性:总线的物理连接方式(根数、插头、插座形状,引脚排列方式)。
功能特性:每根线的功能。
电气特性:每根线上信号的传递方向及有效电平范围。
时间特性:规定了每根总线在什么时间有效。
11、总线速率

题解:总线时钟频率10MHz,即每秒运行10M个时钟周期,一个总线周期需要2个时钟周期,因此每秒运行5M个总线周期,而一个总线周期传输4b信息,所以带宽为20Mbps。注意,若是每个周期传输4Byte信息,则需要乘以8,即160Mbps。题目有些问题,应该是4b(bit)而不是4B(Byte)。
12、Cache命中率

题解:直接相连结构简单,但冲突最高,Cache命中率很容易降低,特别读取主存较多,两个主存数据公用一个Cache块时,命中率会极速下降。
13、单指令多数据流系统并行性
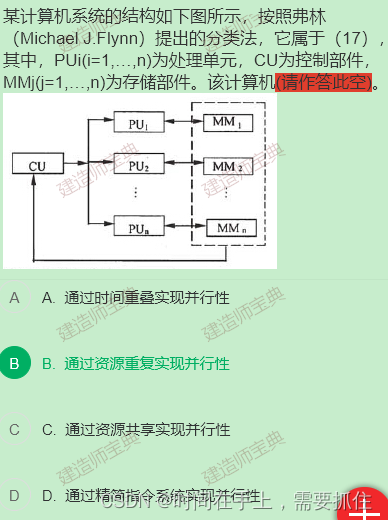
题解:这个一个控制部件多个数据处理部件,为单指令多数据流,每个数据处理部件有自己的数据需要处理,不是共享数据处理,也没有体现时间重叠,因此这里是资源重复。
14、浮点数数据范围

题解:计算机表示浮点数:N=F*2^E,其中F是尾数,1<F<10,E是指数(阶数)。这题有个表达式,我这里不想记基本靠猜和推测得出结论。补码由于没有-0,因此负数绝对值比正数最大值大一位,9位尾数用移码表示。而9位二进制补码最小值是-2^8,最大值是2^8-1。所以尾数与2^8或2^-8有关且负数绝对值大于正数绝对值。
-2^63 = -1*2^63,|-1|>|1-2^-8|,所以C排除,尾数有个极限值1,因此D排除,需要有2^8相关,因此B排除,剩下A。
15、Cache淘汰算法计数

题解:FIFO,先进先出,只需对比数据进入Cache的时间即可,无需计数。LFU:留下频繁使用的数据,即淘汰访问次数的数据,需要统计次数,计数器要很多。FRU:留下最近使用的数据,即淘汰长时间不用的数据,只需对比最后的使用时间即可,无需计数。RAND:随机淘汰,不用对比时间和计数。所以选B,LFU。
16、串行和并行总线

题解:串行总线将数据一位一位传输,数据线只需一根,支持双向需要两根。并行总线一般将多位数据同时传输(4位、8位甚至64位、128位),这样并行总线传输速度快(是串行的4倍到128倍),但由于并行需要很多线路,所以长距离情况下成本高,串行远距离传输成本低。所以近距离用并行,速度快,而远距离用串行,成本低,光纤也是串行的,即A和B错误。而半双工总线虽然同一时刻只能在单方向传递,但可以在两个方向交替传递信息的,所以D错误。一般不同设备有不同的专用总线来保证高性能,若需要通用总线适配不同设备,则复杂性升高,速度降低。
17、Cache 命中率和指令平均读取时间

题解:运行5条指令,需要额外运行一个存取数,即平均时间为:(5条指令读写时间+1条数据读写时间)/5=(5*(10*0.98+100*0.02)+1*(10*0.95+100*0.05))/5=14.7。这里注意是除以5不是除以6,若存取数不是额外操作则是除以6,这里是额外存取数所以除以5,选B。
18、指令存储运行特征

题解:程序中的代码是顺序的,因此同一个程序执行,指令也是顺序存储和执行的,正是因为指令和数据都是小范围取指令和取数,因此才有局部性原理,命中率高。
19、虚拟存储

题解:这里的透明是指:实际上存在,但看不到,即:对存储体系无感知。Cache存储体系由于是硬件自动完成,操作系统和应用程序对此无感知,因此Cache存储体系对系统和应用程序员都是透明的。由于虚拟存储体系是操作系统基于硬件的内存系统进行映射实现的,即虚拟存储就是系统程序员开发的,所以虚拟存储对系统程序员不透明。由于虚拟存储属于系统内核程序,对应用程序员不可见,因此对应用程序员透明。选A。
20、大规模并行处理系统MPP

题解:大规模并行处理(MPP)系统一般是由专用网络下的多个节点组成,每个节点是一个单独的计算机,这些计算机的CPU一般都是标准的处理器,比如英特尔等。因此A正确。MPP是一种异步的分布式存储器结构的MIMD系统,它的程序有多个进程,分布在各微处理上,各进程有自己的存储空间,可以运行各自的任务以及进行消息传递。MPP由于节点多,所以需要特殊的硬件和软件来监控系统、检测错误并从错误中平滑地恢复。所以C和D正确。B应该是使用高性能的定制的高速互连网络以及网络接口。标准的商用以太网满足不了MPP,是需要定制,因此B错误。
21、总线仲裁

题解:菊花链式查询:会按设备连接的先后顺序决定了其优先级。计数器定时查询(轮询):轮询显然是几率相同。独立请求:各设备各自请求,相当于抢占时间片,几率相等。所以选B。
21、芯片工作温度范围

题解:无,最低温分别是0,-40,-55。
22、多核处理器

题解:多核处理器相对于多个单核处理器,是降低了功耗和体积。C和D也没啥问题,B则错误,多核处理器运行的三种模式有:
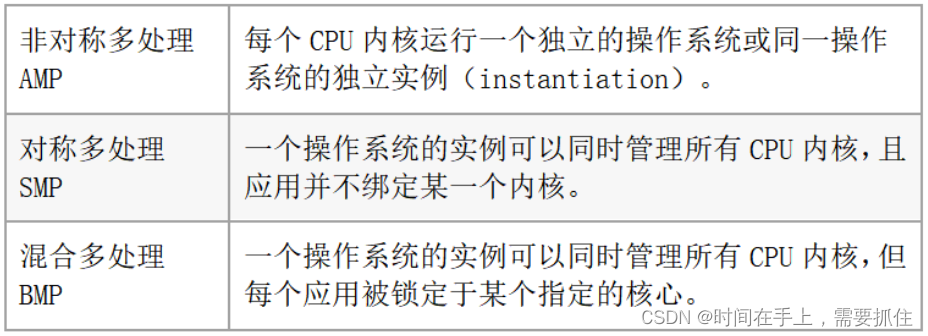
采用运行结构和应用场景有关,但也和硬件差异有关,比如硬件不支持绑定应用等去空谈运行模式也是枉然。
23、DSP芯片的哈佛(HarVard)结构

题解:一个指令分为多个基本操作:比如:存储器读、存储器写、相加等,每一项称为一个基础操做,每个基础操作所需要的时间称为机器周期。因此B错误,因为一个机器周期只能进行一个基本操作,无法多次访问程序或数据。所以B错误,选B。
哈佛(HarVard)体系结构是一种将程序指令和数据存储分开的存储器结构。中央处理器先到程序指令存储器中读取程序指令内容,解码后得到数据地址,再到数据存储器里读取数据,接着才是执行。由于有多个处理单元,指令和数据存储分开,因此可以同时进行指令和数据的读取写入操作,且可以使指令和数据有不同的数据宽度,适应不同的环境和任务。
23、AD芯片的分辨率

题解:分辨率=电压范围/(2^位数),即10V/(2^16)=0.1526mV。
24、微程序的执行

题解:微程序由硬件直接执行。
24、存储方式以及存储器

题解:这里考察存储方式,具体如下:
顺序存取:存数据以记录的方式存储,访问数据按线性顺序进行。采用此方式的有:磁带存储器。
直接存取:用一个共享的读写装置对所有数据进行访问,每个数据块都有唯一地址标识,读写装置可以直接移动到目的数据块进行读写。存取时间会随着距离和移动方式变化而变化。采用此方式的有:磁盘存储器。
随机存取:存储器的每个寻址单元都有唯一的地址和读写装置,系统可以在相同时间内对任意一个存储单元进行访问。采用此方式的有:主存储器(内存条)。
相联存取:一种特殊的随机存取,每个单元都有独立的读写装置,但选择某一单元进行读写是取决于其内容而不是地址。读写时间和随机存取一样是个常数。采用此方式的有:Cache。
25、GPU的结构

题解:GPU不控制其它设备但要对图像和视频等进行大量计算,因此控制单元比CPU少很多,计算单元比CPU多,D正确。CPU由于控制单元多,所以更适合处理不同数据、不同分支以及中断等场合,A正确。由于局部性原理,CPU采用高主频、高速缓存、预测相连数据等来执行指令,D正确。GPU由于要处理大量数据,控制少,因此是单指令多数据流(SIMD)架构,C错误。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











