







改进:加入了多线程下载,提高了照片匹配的准确度,好友相册能够完整下载
一、Cookie获得
chrome 浏览器 Mac Command + Alt + I windows 好像是F12 打开开发者工具进行抓包
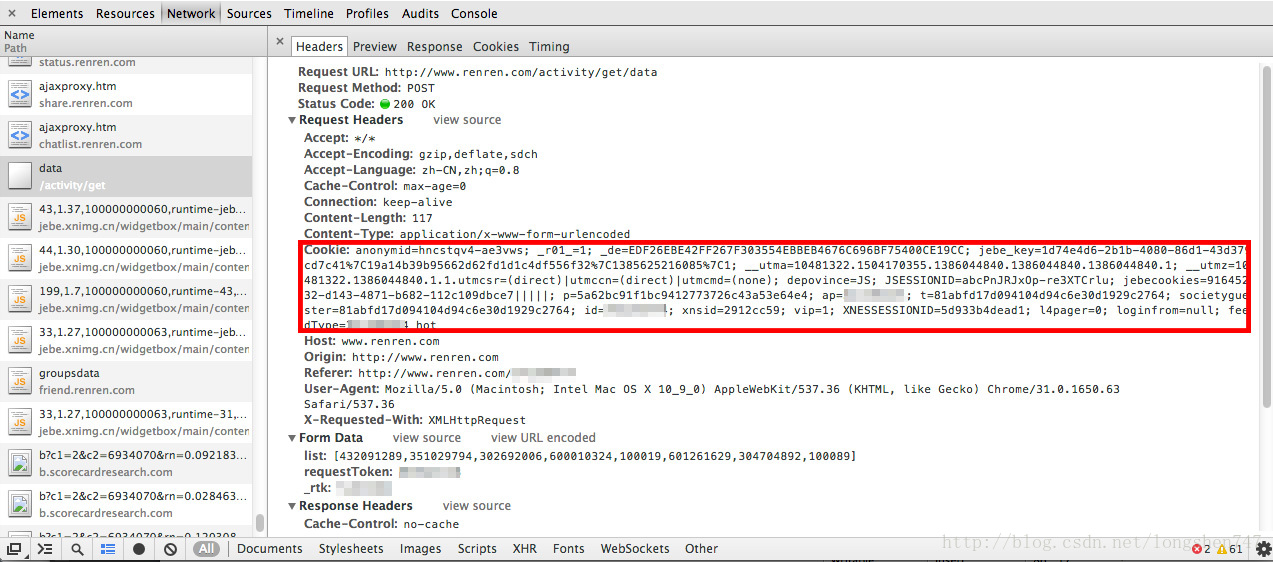
二、抓取图片
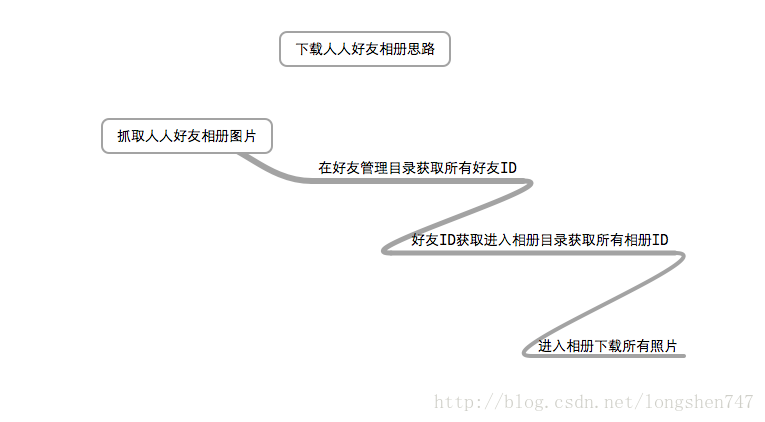
http://friend.renren.com/groupsdata 从次页面用正则表达式获取全部好友的ID
http://photo.renren.com/photo/' + 好友ID + '/album/relatives/profile 从此页面可获得好友相册的ID
http://photo.renren.com/photo/好友ID/album-相册ID?frommyphoto 从相册页面获取照片ID
三、多线程下载
Download类继承了threading.Thread,重写了run()方法,传入了一个存放照片URL的set(),遍历集合进行下载
在实际抓取照片中,每一个相册将会开启一个线程进行下载
代码需附上你自己的人人Cookie
# coding=utf8
import os
import re
import threading
import urllib2
COOKIE = '你自己人人的Cookie'
HEADERS = {'cookie': COOKIE}
# find title
def find_title(mypage):
myMatch = re.search(r'<title>(.+?)</title>', mypage, re.S)
title = u'undefined'
if myMatch:
title = myMatch.group(1)
else:
print u'find no title'
# 文件名不能包含以下字符: \ / : * ? " < > |
title = title.replace('\\', '').replace('/', '').replace(':', '').replace('*', '').replace('?', '').replace('"',
'').replace(
'>', '').replace('<', '').replace('|', '')
return title
def login_renren(url):
try:
req = urllib2.Request(url, headers=HEADERS)
page = urllib2.urlopen(req).read()
page = page.decode('utf-8')
title = find_title(page)
print title
return page
except:
page = ur''
return page
def find_friendlist():
url_friend = 'http://friend.renren.com/groupsdata' #friend list
req = urllib2.Request(url_friend, headers=HEADERS)
try:
page = urllib2.urlopen(req).read()
page = page.decode('utf-8')
except:
print 'cookie is error'
page = ''
pattern = re.compile(r'"fid":\d*?,')
if pattern.findall(page):
list = pattern.findall(page)
friend_file = open('id.txt', 'w')
for i in list:
id = i[6:-1]
friend_file.write(id)
friend_file.write(os.linesep)
friend_file.close()
else:
print 'find no friendID'
# http://photo.renren.com/photo/XXXXXXXXX/album/relatives/profile
# http://photo.renren.com/photo/XXXXXXXXX/album-535947620?frommyphoto
def find_ablumUrl():
list = ur''
file = open('id.txt')
ablum = open('albumlist.txt', 'w')
while 1:
line = file.readline()
if line:
line = line[:-1]
photo_url = 'http://photo.renren.com/photo/' + str(line) + '/album/relatives/profile'
print photo_url
data = login_renren(photo_url)
pattern = re.compile(r'http://photo.renren.com/photo/(.+?)frommyphoto')
if pattern.findall(data):
list = pattern.findall(data)
else:
print 'find no album id'
#remove duplicate album id
albumid_set = set()
for i in list:
albumid_set.add(i)
for i in albumid_set:
album_list = 'http://photo.renren.com/photo/' + str(i) + 'frommyphoto'
print album_list
ablum.write(album_list)
ablum.write(os.linesep)
else:
break
def download_album():
file = open('albumlist.txt')
while 1:
line = file.readline()
if not line:
break
else:
list = ''
data = login_renren(line)
pattern = re.compile(r'large:.*?\.jpg', re.I) #large xlarge
if pattern.findall(data):
list = pattern.findall(data)
else:
print 'found no image'
photo_url = set()
for i in list:
i = i[7:]
photo_url.add(i)
print i # test
try:
d = Download(photo_url)
print d.name
d.start()
except:
print u'download error ' + line
file.close()
#download by thread
class Download(threading.Thread):
def __init__(self, que):
threading.Thread.__init__(self)
self.que = que
def run(self):
for i in self.que:
data = urllib2.urlopen(i).read()
path = str(i[-15:-5]) + '.jpg'
f = open(path, 'wb') # 存储下载的图片
f.write(data)
f.close()
return
#start
def start_photo_grap():
login_renren(URL)
find_friendlist()
find_ablumUrl()
download_album()
URL = r'http://www.renren.com'
if __name__ == '__main__':
start_photo_grap()
print 'success '














 4919
4919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









