







Beautiful Soup是一个Python库
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.
如果想使用当然需要先安装Beautiful Soup
命令:pip install beautifulsoup4
我用的是4.x的版本
其他的慢慢补充
本次的内容是实现抓取小说网页上的文字
小说:巨鼠翻天
下面是小说的内容

查看网页的源代码

文章内容主要是在 p 标签内,所以直接提取 p 标签中的内容
from bs4 import BeautifulSoup
from urllib import request
# 小说网址
# https://read.qidian.com/chapter/xFIXBnhuHptH9vdK3C5yvw2/wNLKJlQpTaK2uJcMpdsVgA2
if __name__ == "__main__":
response = request.urlopen("https://read.qidian.com/chapter/xFIXBnhuHptH9vdK3C5yvw2/wNLKJlQpTaK2uJcMpdsVgA2")
html = response.read()
html = html.decode("utf-8")
html_doc2 = html.encode('utf-8')
soup = BeautifulSoup(html_doc2, 'html.parser')
for link in soup.find_all('p'):
print(link.get_text())
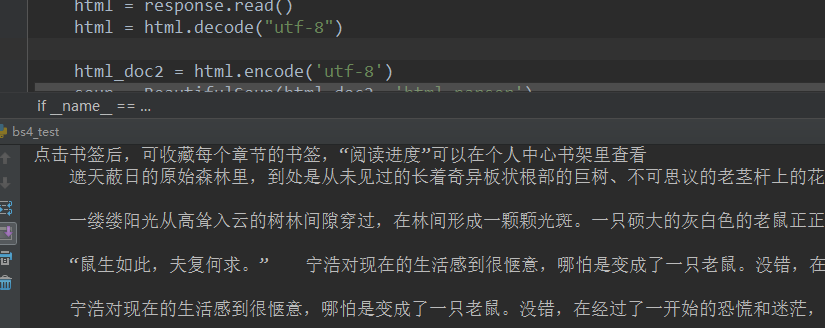
ok,提取成功。















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









