






RDMA已经是分布式训练绕不过去的话题,那么云原生场景下如何用上RDMA呢?又有哪些难点?
下面主要以RoCE举例说明,阐述云原生下使用RDMA设计技术原理和方案。
前提
环境
本章阐述的前提是,服务器集群已经搭建了K8S集群,并且已经配置好了RoCE硬件环境。
名称解释
文章中可能会涉及以下名词:
- 云原生:以容器、微服务、DevOps等技术为基础建立的一套云技术产品体系。
- RDMA(Remote Direct Memory Access):远程直接数据存取,就是为了解决网络传输中服务器端数据处理的延迟而产生的,实现方式有很多种包括IB、RoCE、iWRAP等;
- RoCE(RDMA over Converged Ethernet ):通过以太网网络实现的RDMA 网络协议;
- **HCA(Host Channel Adapter):**在Infiniband/RoCE规范中,将RDMA网卡称为HCA,实现RoCE需要专用的网卡,比较有名的是NVDIA Mellanox提供的ConnectX-*系列;(题外话:Mellanox是一家网络设备公司,已经被NVIDIA收购)
- HCA Driver:RDMA网卡安装之后,需要安装对应的RDMA网卡驱动;
RoCE->云原生RoCE
裸金属上的RoCE
RoCE是为了通过RDMA协议,实现应用间数据的直接通信,下面是一个简单的示意图展示使用RoCE通信时的工作原理。
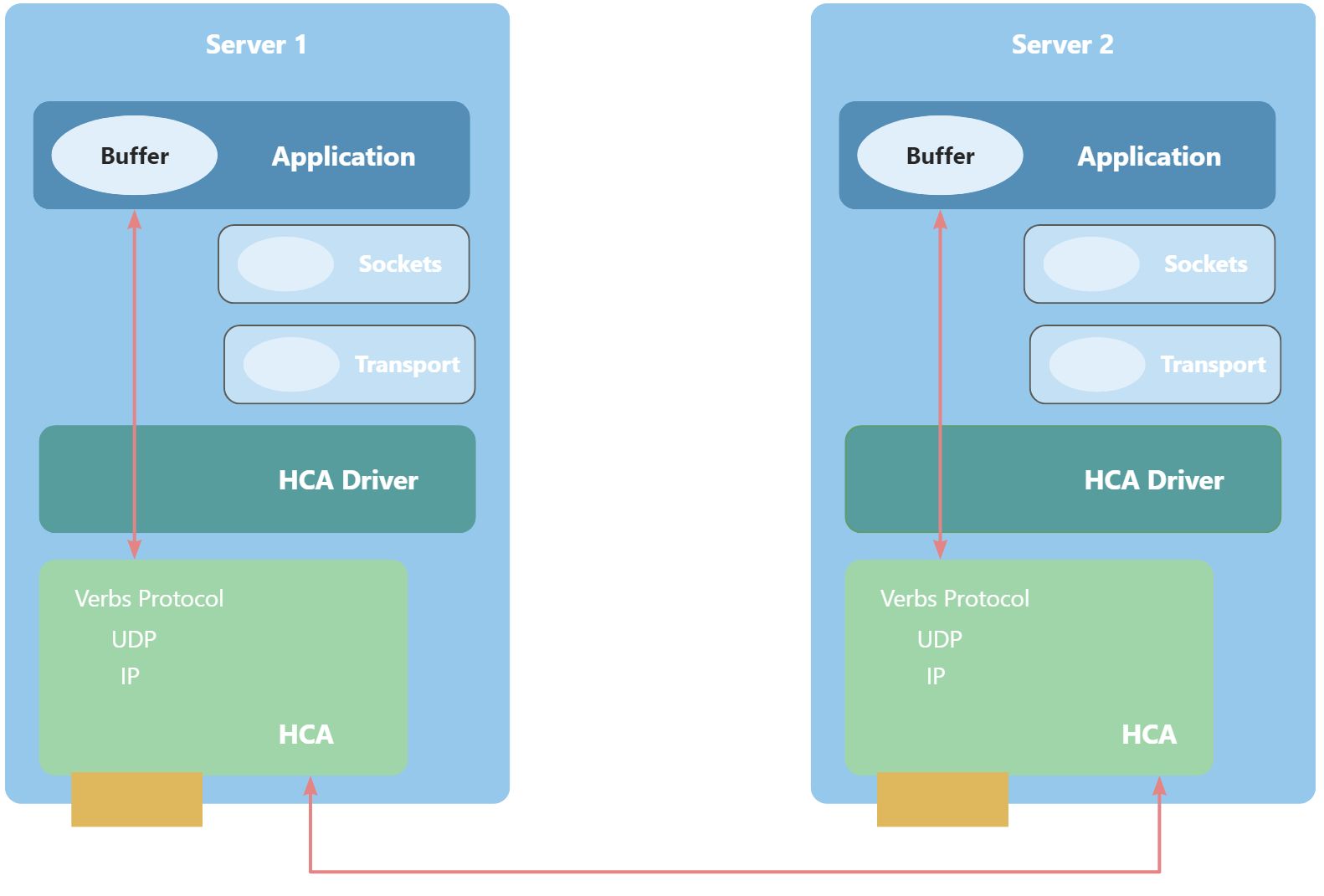
- HCA:绿色+黄色部分,RoCE网卡;
- HCA Driver:深绿色部分,为RoCE网卡对应的驱动,需要使用RoCE需要先安装驱动;
- Application:蓝色部分,通信的应用程序,在分布式训练场景下,一般是指训练进程。
可以看到红线部分是应用程序间通信的线路,不会经过本地的sockets和transport层,可以大大提通信效率,降低CPU负载。
云原生上的RoCE
云原生上的RoCE其实就是将通信Application放到Pod里去运行,正如下图所示。
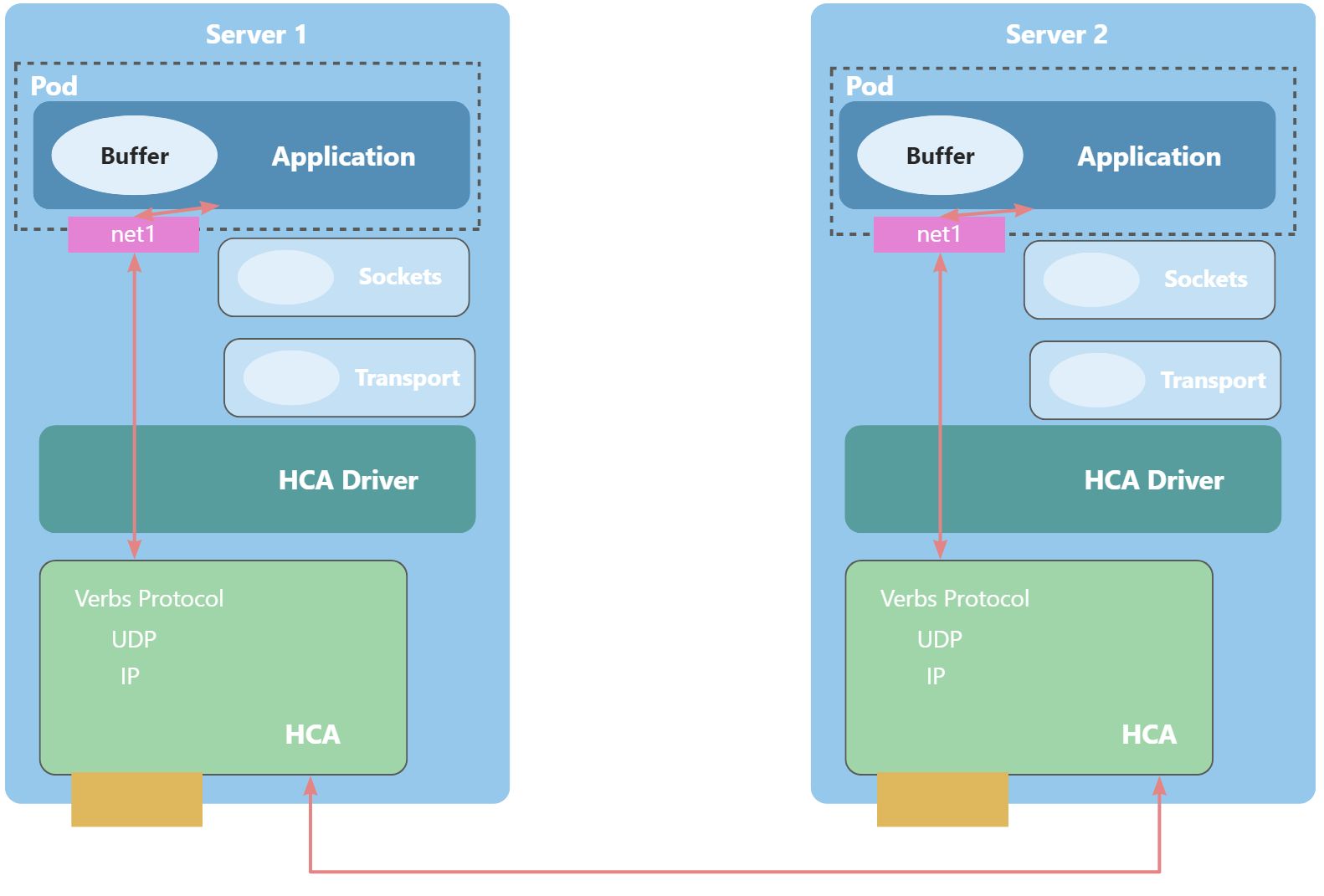
由于Pod内部的容器逻辑上是与宿主机服务器环境隔离的,会存在以下问题需要解决:
- Pod无法直接访问HCA硬件设备:HCA硬件相关文件需要被挂载到Pod内,就像挂载GPU等设备一样,具体可见云原生分布式训练技术综述文章的NVIDIA Container Toolkit章节;
- Pod缺少关联HCA的网络接口:由于k8s默认只会为Pod内容器提供eth0和lo两个网络接口,不会默认提供HCA的网络接口;
因此,云原生的RoCE需要做两个事情:
- 挂载HCA相关硬件设备文件到容器内;
- 增加一个网络接口关联HCA,正如上图中的
net1网络接口(粉色部分)。
下面将阐述云原生如何完成上述两个事情。
容器接口CDI和CNI
为什么要需要先介绍容器接口中的CDI和CNI呢?需要先看下k8s和容器之间的关系,正如下图所示。
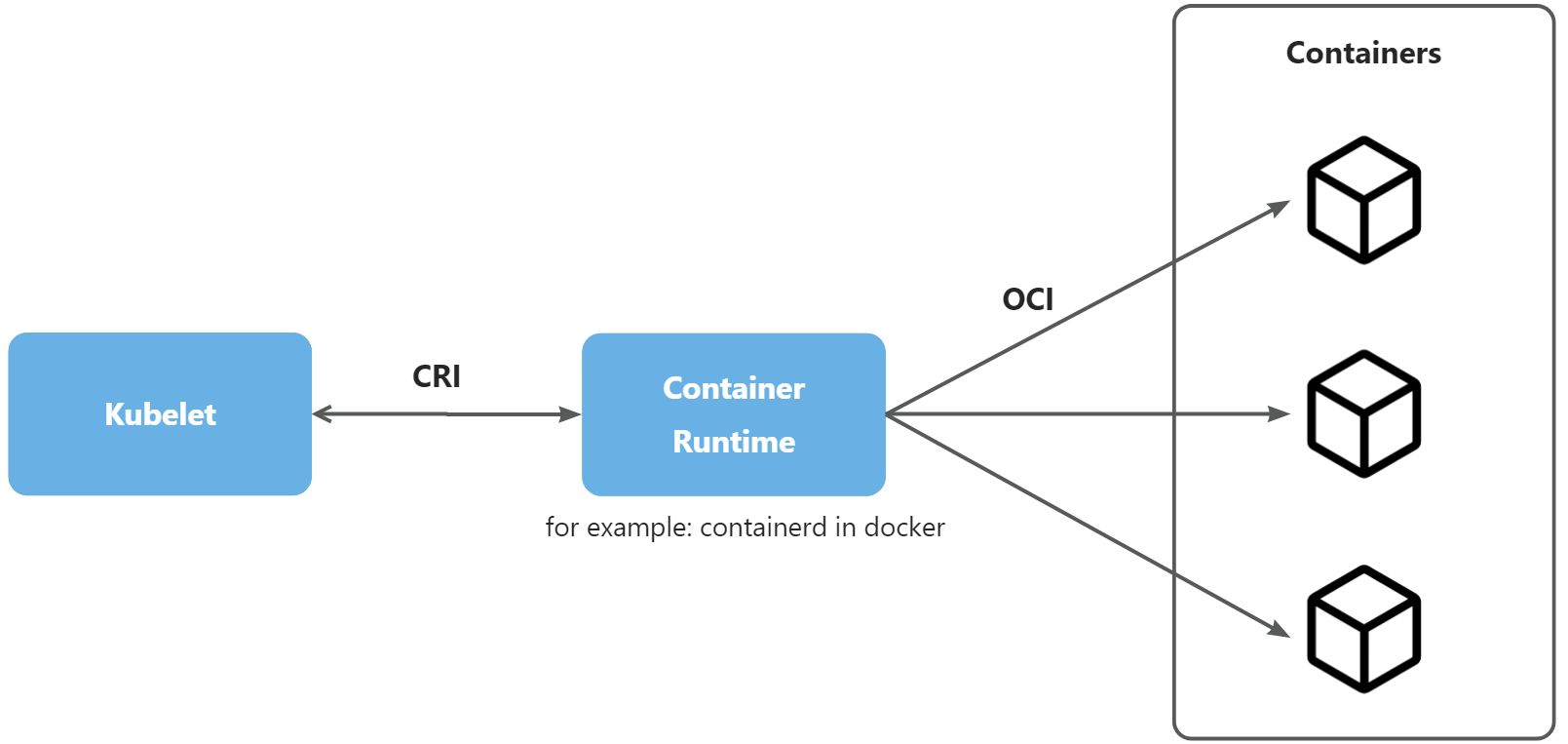
- Kubelet:运行在 node 上的服务,确保 pod 与 container 启动并运行 (需要关闭 swap),每个 node 都需要安装并启动;
- Container Runtime:容器运行时,是一种技术方案,它负责拉取镜像、提取镜像到文件系统和为容器准备挂载点等工作,最常用的实现方案便是
docker的containerd。 - CRI(Container Runtime Interface):kubernetes定义的与其他Container Runtime的接口规范,只要实现了该规范的Container Runtime便可以被kubernetes使用;
- OCI(Open Container Initiative):定义了镜像和容器运行规范并定义了相关接口,Container Runtime的实现方案都需要遵守OCI。
正如上图所示,k8s最终会通过kubelet下发创建容器的接口,如果想要做到上述提到的挂载HCA硬件设备和增加网络接口两件事情,需要Container Runtime先支持才行。
CDI和CNI便是Container Runtime提供的两个相关接口,下面逐一介绍。
(题外话:container runtime是管理容器的一类软件组件,例如Docker使用的container runtime就是containerd,具体可查看文章揭秘容器(二):容器运行时 - 潘忠显)
容器设备接口(Container Device Interface, CDI)
CDI(Container Device Interface)是Container Runtime支持挂载第三方设备(比如:GPU、FPGA等)的机制,允许硬件通过CDI进行自定义挂载。
分布式训练场景下的GPU和网卡设备都可以通过CDI进行挂载。
(题外话:如果想要更深度的了解CDI可以查看文章Container Runtime CDI与NRI介绍-阿里云开发者社区,当然也可以先阅读下面的文章进行初步了解)
为什么需要CDI
下面会展示不用CDI和使用CDI挂载硬件设备的区别。
without CDI
docker run -d --name test --device xxx:xxx -v xxx:xxx -v xxx:xxx -v xxx:xxx centos:7 sleep 1d
那NVIDIA GPU举例,需要挂载的设备文件、库文件和可执行文件会有几十个,因此上述命令会变的很冗长,对用户很不友好,很容易缺漏。
with CDI
docker run --device vendor.com/device=myDevice centos:7 sleep 1d
如果用了CDI,就可以通过指定设备名称来挂载,具体挂载工作container runtime会通过配置进行自动挂载。
拿NVIDIA GPU举例,命令只需要为--device nvidia.com/gpu=all即可,container runtime会去根据/etc/cdi/nvidia.json文件进行操作。
配置样例
下面是CDI Spec提供的一个配置样例。
{
"cdiVersion": "0.5.0",
"kind": "vendor.com/device",
"devices": [
{
"name": "myDevice",
"containerEdits": {
"deviceNodes": [
{"hostPath": "/vendor/dev/card1": "path": "/dev/card1", "type": "c", "major": 25, "minor": 25, "fileMode": 384, "permissions": "rw", "uid": 1000, "gid": 1000},
{"path": "/dev/card-render1", "type": "c", "major": 25, "minor": 25, "fileMode": 384, "permissions": "rwm", "uid": 1000, "gid": 1000}
]
}
}
],
"containerEdits": {
"env": [
"FOO=VALID_SPEC",
"BAR=BARVALUE1"
],
"deviceNodes": [
{"path": "/dev/vendorctl", "type": "b", "major": 25, "minor": 25, "fileMode": 384, "permissions": "rw", "uid": 1000, "gid": 1000}
],
"mounts": [
{"hostPath": "/bin/vendorBin", "containerPath": "/bin/vendorBin"},
{"hostPath": "/usr/lib/libVendor.so.0", "containerPath": "/usr/lib/libVendor.so.0"},
{"hostPath": "tmpfs", "containerPath": "/tmp/data", "type": "tmpfs", "options": ["nosuid","strictatime","mode=755","size=65536k"]}
],
"hooks": [
{"createContainer": {"path": "/bin/vendor-hook"} },
{"startContainer": {"path": "/usr/bin/ldconfig"} }
]
}
}
对于这个例子,有如下的说明:
- kind字段的值的格式为
VendorID/Class,这里为vendor.com/device。 - 在devices字段中,只定义了一个设备,设备名称为myDevice。containerEdits定义了该设备有哪些行为:
- deviceNodes表示要将宿主机上哪些设备挂载到容器中。
- env表示要为该容器自动添加哪些环境变量。
- mounts表示要将哪些文件挂载到宿主机中。
- hooks表示需要为容器添加哪些hooks。
- 最外层的containerEdits(与devices字段在同一级别)为所有设备的公共行为,也就是myDevice的最终的containerEdits是两个containerEdits的并集。
NVIDIA Container Runtime中的CDI使用
nvidia-container-toolkit从1.12开始实现对CDI支持,下面是生成的CDI设备配置文件,由于文件内容过多,省略了mounts部分挂载众多的库文件。
---
cdiVersion: 0.5.0
containerEdits:
deviceNodes:
- path: /dev/nvidia-uvm-tools
- path: /dev/nvidia-uvm
- path: /dev/nvidiactl
- path: /dev/nvidia-modeset
hooks:
- args:
- nvidia-ctk
- hook
- update-ldcache
- --folder
- /lib
- --folder
- /lib64
- --folder
- /lib/vdpau
- --folder
- /lib64/vdpau
hookName: createContainer
path: /usr/bin/nvidia-ctk
- args:
- nvidia-ctk
- hook
- chmod
- --mode
- "755"
- --path
- /dev/dri
hookName: createContainer
path: /usr/bin/nvidia-ctk
mounts:
- containerPath: /usr/bin/nvidia-smi
hostPath: /usr/bin/nvidia-smi
options:
- ro
- nosuid
- nodev
- bind
...... # 省略其他挂载的库文件
devices:
- containerEdits:
deviceNodes:
- path: /dev/nvidia0
- path: /dev/dri/card1
- path: /dev/dri/renderD128
name: "0"
- containerEdits:
deviceNodes:
- path: /dev/nvidia0
- path: /dev/dri/card1
- path: /dev/dri/renderD128
name: all
kind: nvidia.com/gpu
从生成的CDI设备中可以看到,节点上只有一个GPU,并且CDI定义了两个设备:0和all,0代表是挂载0号GPU卡,而all代表是挂载节点上的所有GPU设备,这里0和all是一样的。
小结
CDI提供了第三方给容器配置设备的接口,这样就可以给容器挂载不同的设备了,只需要生成上述的配置文件,放到/etc/cdi/下即可。
容器网络接口(Container Network Interface, CNI)
CNI(Container Network Interface)(是一个用于容器网络的规范和接口,它定义了一组标准的API和插件,用于在Container Runtime创建、配置和管理网络。
在分布式训练场景下,可以根据CNI规范实现高性能容器网络,当然也可以根据业务需求,实现自己的网络环境搭建方案。
CNI的作用及组成
CNI的作用主要如下:
- 为容器分配IP地址;
- 配置网络路由;
- 实现网络隔离和安全策略;
CNI的组成很简单,主要由以下三部分组成:
- CNI插件二进制文件:CNI插件二进制文件是实际的网络插件,用于管理容器网络,一般在
/opt/cni/bin文件下; - CNI配置文件:CNI配置文件是用于配置CNI插件的JSON文件,它包括网络参数、IP地址、路由和端口映射等信息,一般存放在
/etc/cni/net.d/文件下; - CNI运行时:CNI运行时是容器运行时调用CNI插件的框架,它根据CNI配置文件中的信息调用对应的CNI插件,并将结果返回给容器运行时。
CNI的分类
官方提供的插件目前分成三类:Main、Meta和IPAM。main 是主要的实现了某种特定网络功能的插件;meta 本身并不会提供具体的网络功能,它会调用其他插件,或者单纯是为了测试;ipam 是分配 IP 地址的插件。
CNI主要分类以下几类:
- Main(负责接口(网桥或网卡)创建)
bridge: 和 docker 默认的网络模型很像,把所有的容器连接到虚拟交换机上;loopback: 负责生成 lo 网卡,并配置上 127.0.0.1/8 地址;macvlan: 使用 macvlan 技术,从某个物理网卡虚拟出多个虚拟网卡,它们有独立的 ip 和 mac 地址;ipvlan:和 macvlan 类似,区别是虚拟网卡有着相同的 mac 地址;ptp: 通过 veth pair 在容器和主机之间建立通道;SR-IOV:第三方插件,创建基于 SR-IOV 的额外网络可让 Pod 附加到主机系统上支持 SR-IOV 的硬件的虚拟功能 (VF) 接口。
- IPAM(IP地址分配和管理)
dhcp: 从已经运行的 DHCP 服务器中获取 ip 地址;host-local: 基于本地文件的 ip 分配和管理,把分配的 IP 地址保存在文件中;calico-ipam: 第三方插件,是 clalico cni 自己的 ip 地址分配插件,是一种集中式 ip 分配插件;whereabouts: 第三方插件,也是一个集中式 ip 分配插件,用的比较少,使用了 sriov 设备才用到的,这个是 k8snetworkplumbingwg 社区开源的。
- Meta(其他用处,有的用于与第三方插件适配,有的用于配置内核参数等)
portmap: 基于iptables 的portmapping 插件,将端口从主机的地址空间映射到容器;calico: 第三方插件,是专门为 Calico 项目提供的 CNI 插件;flannel: 第三方插件这就是专门为 Flannel 项目提供的 CNI 插件。
除了上述分类依据,CNI还分为官方插件和第三方插件,上述的multus、calico、flannel都是第三方插件,官方插件可以查看官方项目plugins。
官方CNI安装
官方的CNI安装其实很简单,只需要去官方项目plugins下载最新的包,解压到/opt/cni/bin目录下即可。
[root@localhost ~]# mkdir -p /opt/cni/bin
[root@localhost ~]# wget https://github.com/containernetworking/plugins/releases/download/v1.5.1/cni-plugins-linux-amd64-v1.1.1.tgz
[root@localhost ~]# tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.5.1.tgz
[root@localhost ~]# ls /opt/cni/bin
bandwidth bridge dhcp firewall host-device host-local ipvlan loopback macvlan portmap ptp sbr static tuning vlan vrf
可以看到/opt/cni/bin目录下已经有了官方提供的二进制文件,只需要在/etc/cni/net.d目录下进行配置使用的CNI既可。
小结
CNI为不同的网络方案提供了集成的接口,官方也提供不同的网络方案,二进制启动文件放置在/opt/cni/bin目录下,配置文件放置在/etc/cni/net.d目录下即可。
K8S+RoCE
既然容器层提供了CDI和CNI两个工具**,那么K8S层如何利用这两个接口进行去实现RoCE的通信呢**?
下图主要展示了K8S+RoCE的整体架构图。
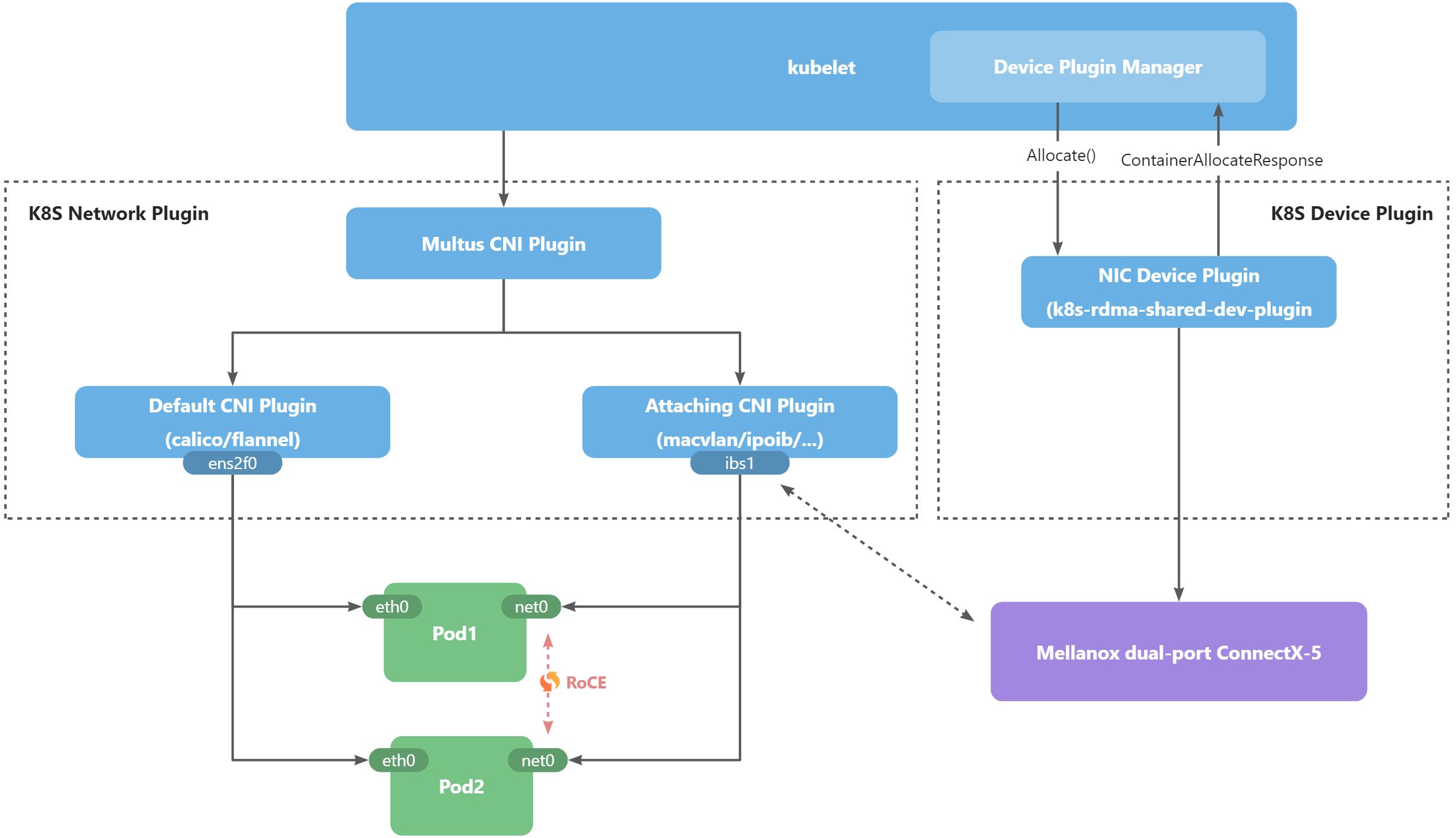
可以发现主要k8s+RoCE主要由三部分协作完成,主要为:
- kubelet:运行在 node 上的服务,确保 pod 与 container 启动并运行 (需要关闭 swap),每个 node 都需要安装并启动;
- Network Plugin: kubernetes1.24开始,移除了CNI的管理工作,由用户自定义,因此可以看到图中的Network Plugin部分直接使用CNI插件,未作二次加工;
- Multus CNI Plugin:提供了容器多网络接口的方案;
- Default CNI Plugin:提供了k8s运行的默认网络管理方案,可采用calico/flnnel;
- Attaching CNI Plugin:提供了第三方附加的网络方案用于提供关联HCA的容器网络接口,可采用macvlan/ipoib;
- Device Plugin:设备插件,K8S提供了设备插件的接口规范,NVIDIA基于规范提供了NVIDIA Device Plugin用来支持GPU设备接入K8S,Mellanox也基于规范提供了用于管理ConnectX-5 RoCE网卡的k8s-rdma-shared-dev-plugin。
其实Network Plugin和Device Plugin主要对应的便是容器接口中的CNI和CDI。
下面主要阐述Network Plugin和Device Plugin在K8S+RoCE中做了什么以及怎么做。
K8S Device Plugin
K8S Device Plugin其实呼应了容器的CDI部分,但是由于该特性上线比较晚,很多device plugin对CDI的支持都是可选的,但是训练场景下常用的NVIDIA Device Plugin和RDMA Share Device Plugin都已支持CDI。
(题外话:关于k8s device plugin机制的更详细信息请参考官方文档:device plugin)
K8S Device Plugin怎么工作
下图展示了Device Plugin的工作原理。
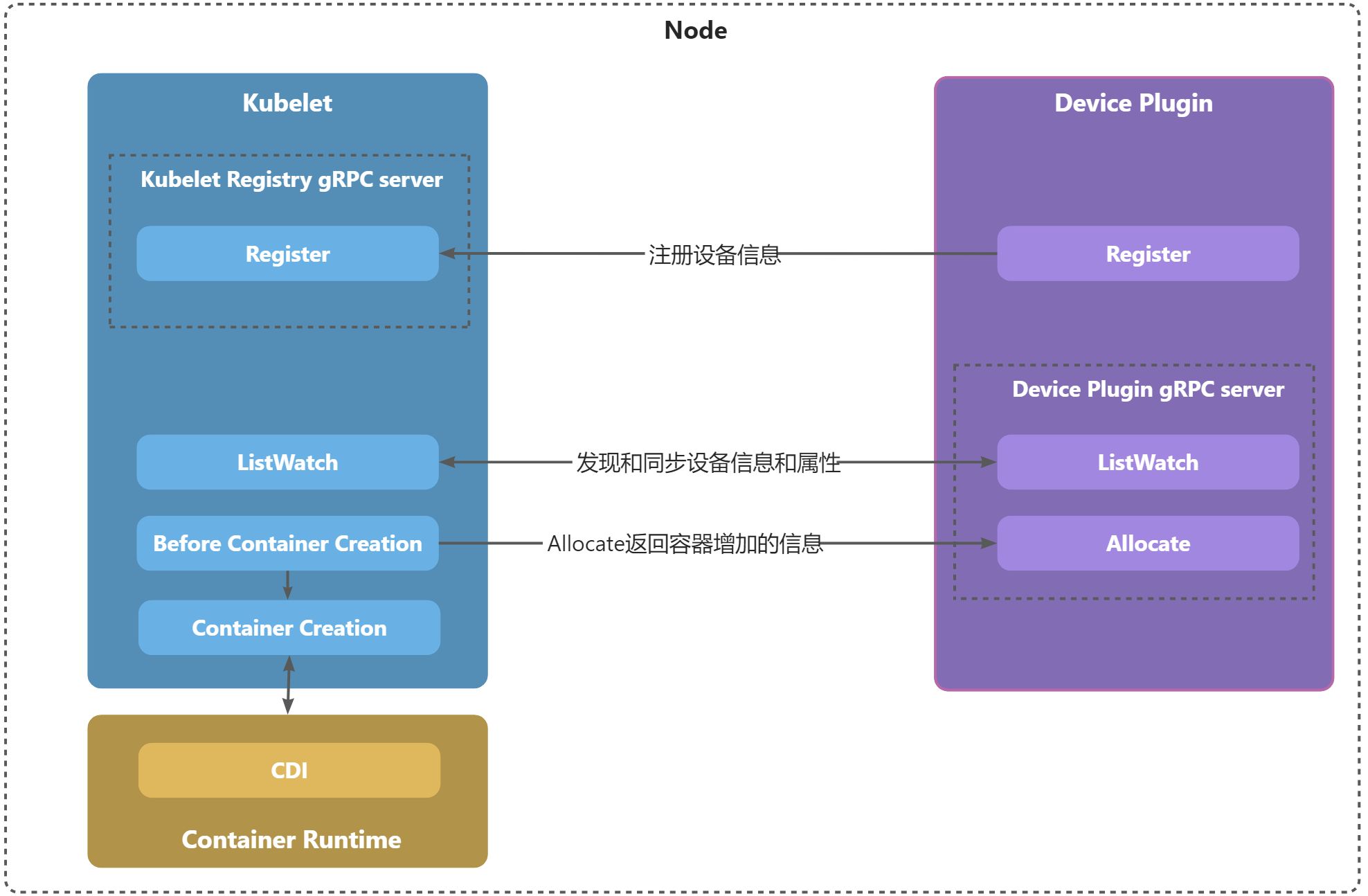
正如上图所示,Device Plugin的工作原理分为以下几部分:
- 向kubelet注册设备信息,如果成功后,便可以通过
kubectl describe node查看设备的可用量等信息,通过register()完成; - 注册完后,还会进行设备信息和属性的同步,包括占用量、可用量等信息,通过ListAndWatch() 完成;
- 在有pod需要使用设备时,kubelet会在创建容器前,调用Devcie Plugin的
Allocate()接口,来获取需要给容器增加的信息; - 如果需要对接CDI,那么
Allocate()接口只需要给容器增加Annotation即可,在下发给Container Runtime后,Container Runtime会根据Annotation去调用配置文件进行设备挂载。
Allocate函数说明
由上述说明可以发现,Allocate函数是K8S Device Plugin的核心函数,决定了为容器增加的信息,下面是它的一些说明:
- Device Plugin启动时会向Kubelet注册一些设备ID,这些设备ID有可能是真的设备ID,也有可能是一些无实际意义的ID;
- Pod申请设备资源时,申请的值为device plugin向kubelet注册的设备ID集合的子集;
- kubelet为每个容器分配某种设备资源(比如GPU)以后,会通过GRPC协议调用该资源对应的device plugin的Allocate函数,kubelet需要传入分配的设备ID作为Allocate参数;
- device plugin需要根据kubelet传入的设备ID,向kubelet返回需要给容器添加的配置,例如:如果kubelet为某个容器分配设备ID为TestID1,那么需要给容器配置如下的配置(具体配置根据设备而定):
- 一个环境变量xxx=xxx;
- 一个Annotation xxx=xxx;
- 挂载宿主机上某个设备文件/dev/xxx到容器中;
- 挂载宿主机上某个二进制文件/usr/bin/xxx到容器中;
- 设备ID与容器配置信息之间的对应关系就是Device plugin的Allocate函数需要完成的逻辑;
- 如果使用CDI只需要为容器加入一个Annotaion即可,上述的挂载目录操作可交给container runtime去做。
Allocate函数代码示例
下面是RDMA Share Device PluginAllocate函数的部分代码,呼应上述解释部分。
// Allocate which return list of devices.
func (rs *resourceServer) Allocate(ctx context.Context, r *pluginapi.AllocateRequest) (
*pluginapi.AllocateResponse, error) {
log.Println("allocate request:", r)
rs.mutex.RLock()
defer rs.mutex.RUnlock()
ress := make([]*pluginapi.ContainerAllocateResponse, len(r.GetContainerRequests()))
for i := range r.GetContainerRequests() {
ress[i] = &pluginapi.ContainerAllocateResponse{}
// 使用CDI
if rs.useCdi {
var err error
// 加入Annotation
ress[i].Annotations, err = rs.cdi.CreateContainerAnnotations(
rs.pciDevices, cdiResourcePrefix, cdiResourceKind)
if err != nil {
return nil, fmt.Errorf("cant create container annotation: %s", err)
}
// 不适用CDI, 直接加入挂载的设备目录
} else {
ress[i].Devices = rs.deviceSpec
}
}
response := pluginapi.AllocateResponse{
ContainerResponses: ress,
}
log.Println("allocate response: ", response)
return &response, nil
}
安装k8s-rdma-shared-dev-plugin
k8s-rdma-shared-dev-plugin作为k8s+RoCE绕不过去的Device Dlugin,它负责处理HCA硬件设备挂载相关的工作。下面将主要阐述如何安装该插件,如果不感兴趣可以跳过盖章。
1 生成ConfigMap
** 查看RDMA网卡的厂商ID和设备ID**
[root@localhost ~]# lspci | grep Mellanox
39:00.0 Infiniband controller: Mellanox Technologies MT27800 Family [ConnectX-5]
39:00.1 Infiniband controller: Mellanox Technologies MT27800 Family [ConnectX-5]
ca:00.0 Infiniband controller: Mellanox Technologies MT27800 Family [ConnectX-5]
39:00.0、39:00.1和ca:00.0便是PCI号。
[root@localhost ~]# lspci -n | grep 39:00.0
39:00.0 0207: 15b3:1017
厂商ID是15b3,设备ID是1017。
创建configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: rdma-devices
namespace: kube-system
data:
config.json: |
{
"periodicUpdateInterval": 300,
"configList": [{
"resourceName": ""hpc_shared_devices_ens13f1np1",
"rdmaHcaMax": 1000,
"selectors": {
"vendors": ["15b3"],//第1张RDMA网卡对应的厂商ID
"deviceIDs": ["1017"],//第1张RDMA网卡对应的设备ID,通过上述步骤可查询
"ifNames": ["ens13f1np1"]//填写第1张物理网卡名称
}
},
{
"resourceName": "hpc_shared_devices_ens17f1np1",
"rdmaHcaMax": 1000,
"selectors": {
"vendors": ["15b3"],
"deviceIDs": ["1017"],
"ifNames": ["ens17f1np1"]
}
}
]
}
创建ConfigMap
[root@localhost ~]# kubectl create -f rdma-devices-config-map.yaml
configmap/rdma-devices created
2 创建k8s-rdma-shared-dev-plugin daemonset
[root@localhost ~]# kubectl create -f https://raw.githubusercontent.com/Mellanox/k8s-rdma-shared-dev-plugin/master/images/k8s-rdma-shared-dev-plugin-ds.yaml
daemonset.apps/rdma-shared-dp-ds created
3 查看设备注册信息
[root@localhost ~]# kubectl describe node
...
Allocatable:
hpc_shared_devices_ens13f1np1 1k
hpc_shared_devices_ens17f1np1: 500
...
小结
K8S Device Plugin提供了第三方设备接入K8S的规范,在分布式训练场景下,NVIDIA Device Plugin和RDMA Share Device Plugin作为最常用的Device Plugin用来管理GPU和HCA。本节主要展示了K8S Device Plugin的工作原理以及RDMA Share Device Plugin的安装过程。
K8S Network Plugin
K8S Network Plugin其实呼应了容器的CNI,但是不同于K8S Device Plugin的是,K8S在1.24版本之后移除了CNI的相关工作,CNI 的管理不再是 kubelet 的工作。
CNI的工作原理其实无需多言,flannel和calico两个插件是K8S集群部署绕不过的CNI插件,占据了大约90%的市场份额。但是它一般作为K8S需要的默认网络管理,如果需要新增网络接口来做特殊业务处理便需要做别的工作。
因此,在K8S+RoCE的方案中需要引入Muluts CNI插件,用于解决原生K8S集群不支持多网络接口的问题。
Multus CNI
这是英特尔开发的Multus的CNI插件,本身不提供网络配置功能,它是通过用其他满足 CNI 规范的插件进行容器的网络配置。
Multus工作原理
原本容器里应仅存在 eth0 接口(loopback 忽略不计),是由主要网络插件产生创建并配置的;而当集群环境存在 Multus CNI 插件,并添加额外配置后,将会发现此容器内不再仅有 eth0 接口,你可以利用这些新增的接口去契合实际业务需求。
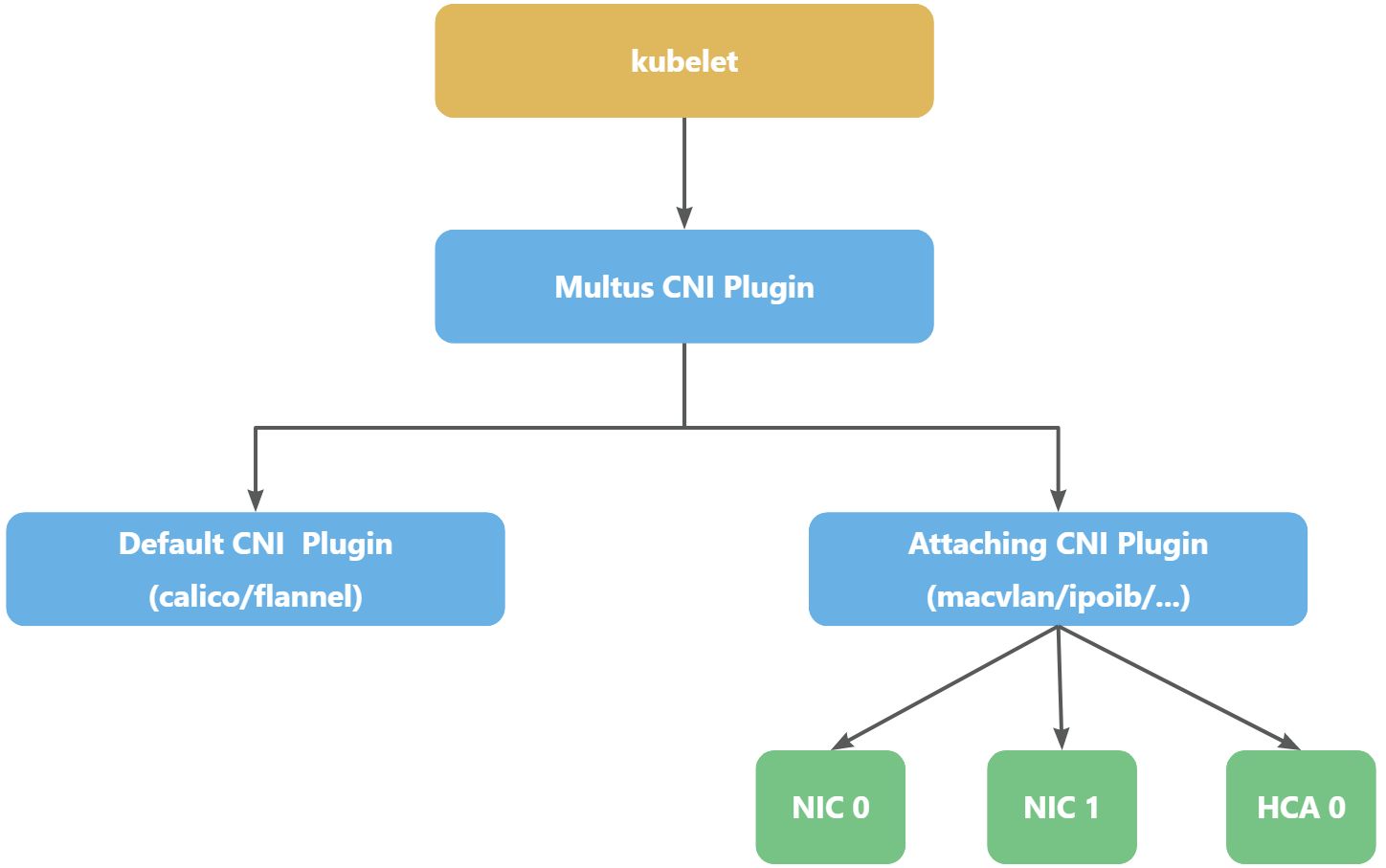
正如上图所示,Multus CNI Plugin用于管理不同的CNI接口:
- Default CNI Plugin:是指主插件,用于配置容器内的eth0接口;
- Attaching CNI Plugin是指附加插件,通过Multus CNI提供的NetworkAttachmentDefinition CRD来进行配置,可以针对不同的网卡进行配置,当然也支持HCA。
Multus CNI工作流
在 Kubernetes 中,处理容器网络相关的逻辑并不会在 kubelet 主干代码里执行,而是会在具体的 CRI(Container Runtime Interface,容器运行时接口)实现里完成,正如下图所示:
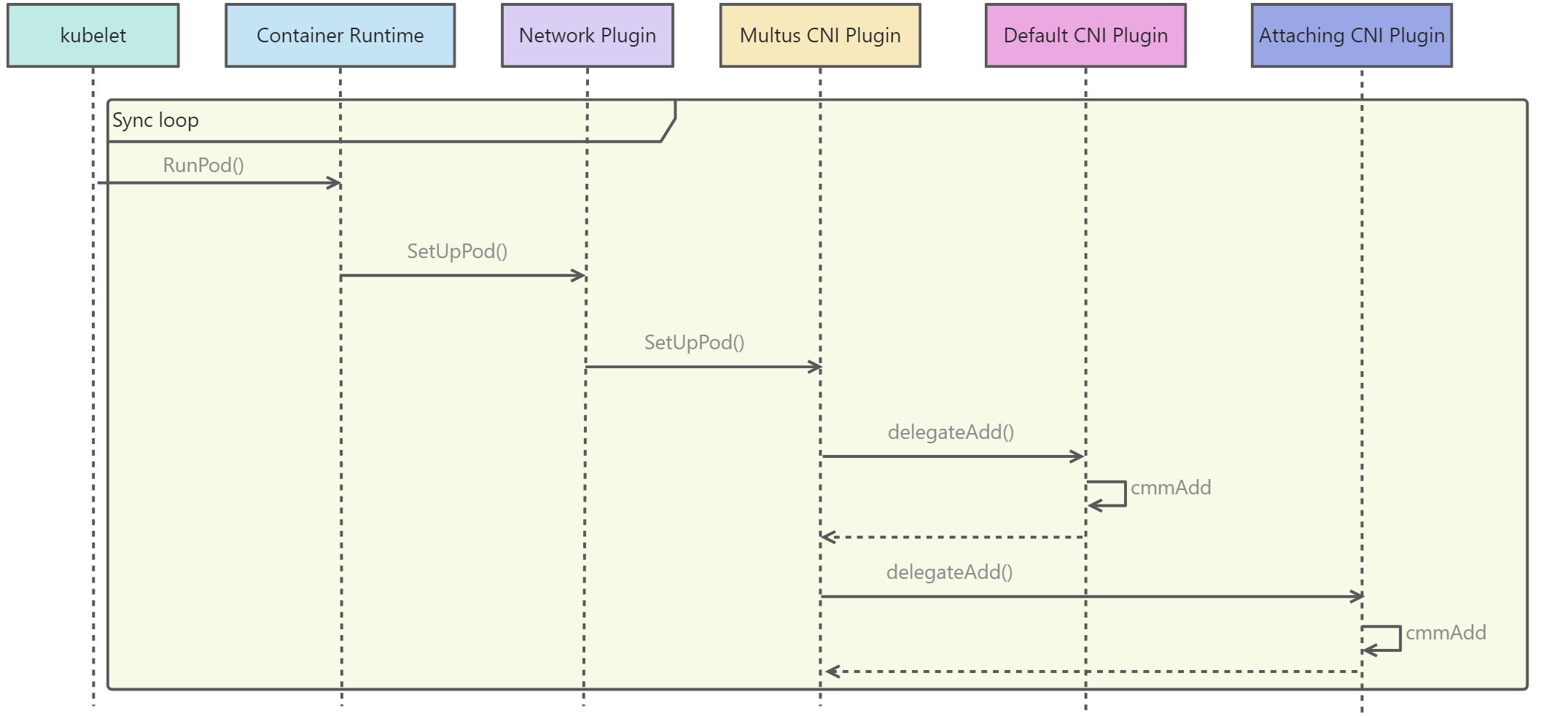
由上图可知:
- kubelet只是通过CRI将网络配置文件以 JSON 格式通过 STDIN 方式传递给 Multus CNI 插件可执行文件,可执行便是CNI的启动入口,比如上述讲到的由官方CNI Plugins安装在
/opt/cni/bin目录下的文件; - Default CNI Plugin的配置文件一般放在
/etc/cni/net.d文件下,Multus 只会加载按字典顺序排在第一位的配置文件,转换成自己的默认网络配置文件,因此一般会将默认的网络配置文件取名为00-network.conf; - 默认网络配置文件,正如下节中的
70-multus.conf所示,delegates字段会指定需要启动的CNI插件; - Attaching CNI Plugin的配置一般通过Multus提供的
NetworkAttachmentDefinition CRD进行自由增加,其中也会指定使用网卡、网络配置以及CNI插件的可执行文件,具体可见下节。
安装Multus
了解上述原理后,通过实际安装来了解其中的配置过程。
安装Daemonset
git clone https://github.com/k8snetworkplumbingwg/multus-cni.git && cd multus-cni
cat ./deployments/multus-daemonset-thick-plugin.yml | kubectl apply -f -
配置默认网络
在/etc/cni/net.d目录下新建一个70-multus.conf用于配置Default CNI,配置文件可以如下所示:
{
"capabilities": {
"bandwidth": true,
"portMappings": true
},
"cniVersion": "0.3.1",
"delegates": [
{
"cniVersion": "0.3.1",
"name": "k8s-pod-network",
"plugins": [
{
"datastore_type": "kubernetes",
"ipam": {
// type字段定义CNI的可执行文件,需要在/opt/cni/bin目录下有同名的可执行文件
"type": "calico-ipam"
},
"kubernetes": {
"kubeconfig": "/etc/cni/net.d/calico-kubeconfig"
},
"log_file_path": "/var/log/calico/cni/cni.log",
"log_level": "info",
"mtu": 1440,
"nodename": "master",
"policy": {
"type": "k8s"
},
"type": "calico"
},
{
"capabilities": {
"portMappings": true
},
"snat": true,
"type": "portmap"
},
{
"capabilities": {
"bandwidth": true
},
"type": "bandwidth"
}
]
}
],
"logLevel": "verbose",
"logToStderr": true,
"kubeconfig": "/etc/cni/net.d/multus.d/multus.kubeconfig",
"name": "multus-cni-network",
"type": "multus"
}
type字段定义CNI的可执行文件,需要在/opt/cni/bin目录下有同名的可执行文件
配置附加网络(IPoIB)
需要基于Multus提供的NetworkAttachmentDefinition CRD进行创建,下面是一个示例:
apiVersion: "k8s.cni.cncf.io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: ipoib-conf
spec:
config: '{
"cniVersion": "0.3.1",
"type": "ipoib",
"master": "ibs1",
"ipam": {
"type": "whereabouts",
"range": "10.0.0.0/24"
}
}'
上述示例中,需要注意以下几点:
- 默认已经安装了第三方CNI插件IPoIB;
master使用的是ibs1,应与集群中主机上的网络接口名称匹配,在RoCE场景下,需要是已经配置好RoCE网卡;main网络用的是ipoib,当然这部分也可以是macvlan,下面会是演示配置macvlan;ipam是选用wehereabouts作为管理ip的插件;
配置附加网络(Macvlan)
生成使用macvlan CNI的配置文件,如下所示:
apiVersion: "k8s.cni.cncf. io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: macvlan-conf-ens2f1
spec:
config: '{
"cniVersion": "0.3.1",
"type": "macvlan",
"master": "ens2f1",
"ipam": {
"type": "host-local",
"subnet": "10.56.217.0/24"
"rangeStart": "10.56.217.71"
"rangeEnd": "10.56.217.81",
"routes": [
{ "dst": "0.0.0.0/0" }
],
"gateway": "10.56.217.1"
}
}'
---
apiVersion: "k8s.cni.cncf. io/v1"
kind: NetworkAttachmentDefinition
metadata:
name: macvlan-conf-ens140f1
spec:
config: '{
"cniVersion": "0.3.1",
"type": "macvlan",
"master": "ens140f1",
"ipam": {
"type": "host-local",
"subnet": "10.56.217.0/24"
"rangeStart": "10.56.217.91"
"rangeEnd": "10.56.217.101",
"routes": [
{ "dst": "0.0.0.0/0" }
],
"gateway": "10.56.217.1"
}
}'
上述示例中,需要注意以下几点:
- 官方的CNI插件安装已经安装了Macvlan,因此不需要格外安装;
- 定义了两个NAD,
master使用的分别是ens2f1和ens140f1,这因为有可能相同作用的HCA,在各自服务器内的网络接口不同,因此需要分别配置;应与集群中主机上的网络接口名称匹配,在RoCE场景下,需要是已经配置好RoCE网卡; main网络用的是macvlan;ipam是选用host-local作为管理ip的插件;
使用附加网络
apiVersion: v1
kind: Pod
metadata:
name: samplepod
# 配置附加网络接口
annotations:
k8s.v1.cni.cncf.io/networks: default/ipoib-conf,default/macvlan-conf-ens2f1
spec:
containers:
- name: samplepod
command: ["/bin/ash", "-c", "trap : TERM INT; sleep infinity & wait"]
image: alpine
k8s.v1.cni.cncf.io/networks: default/ipoib-conf,default/macvlan-conf-ens2f1中的k8s.v1.cni.cncf.io/networks是固定的key值;default是命名空间,ipoib-conf和macvlan-conf-ens2f1是NAD的名字。
查看pod内网络情况
在pod中使用ifconfig命令查看网络信息,如下图所示:
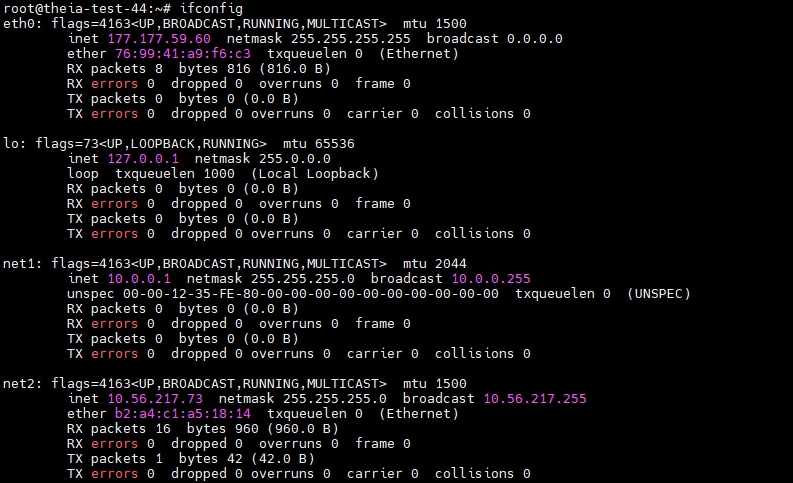
net1便是新增的附加网络接口,使用的网段为10.0.0.0/24;net2为也是新增的附加网络接口,网段是10.56.217.0/24。
IPoIB CNI
在Kubernetes(K8S)集群中使用IPolB(IP over InfiniBand)可以提供更高的网络性能和可靠性。IPolB将IP协议封装在InfiniBand物理网络上,使得在K8S集群中的Pod之间的通信更高效。
安装IPoIB CNI
只需要在配备好ib设备和驱动程序的环境上,并通过下面的yaml文件创建daemonset即可。
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: kube-ipoib-cni-ds
namespace: kube-system
labels:
tier: node
app: ipoib-cni
spec:
selector:
matchLabels:
name: ipoib-cni
template:
metadata:
labels:
tier: node
app: ipoib-cni
name: ipoib-cni
spec:
hostNetwork: true
tolerations:
- key: node-role.kubernetes.io/master
operator: Exists
effect: NoSchedule
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
containers:
- name: kube-ipoib-cni
image: ghcr.io/Mellanox/ipoib-cni:latest
imagePullPolicy: IfNotPresent
securityContext:
privileged: true
resources:
requests:
cpu: "100m"
memory: "50Mi"
limits:
cpu: "100m"
memory: "50Mi"
volumeMounts:
- name: cnibin
mountPath: /host/opt/cni/bin
volumes:
- name: cnibin
hostPath:
path: /opt/cni/bi
注意:如果要使用Macvlan只需要使用官方CNI安装步骤即可。
K8S+RoCE训练案例
可以使用以下案例进行测试RoCE网络,只需要在原有的程序上加入以下步骤:
- 添加annotation:申明使用的NetworkAttachmentDefinition(NAD),对应上述的K8S Network Plugin;
- 添加resource:申明使用的RDMAdevice,该设备需要是由k8s-rdma-shared-dev-plugin完成注册的,对应K8S Device Plugin。
apiVersion: v1
kind: Pod
metadata:
name: test-pod1
annotations:
k8s.v1.cni.cncf.io/networks: default/ipoib-conf,default/macvlan-conf-ens2f1 # 添加annotation
spec:
restartPolicy: OnFailure
containers:
- image: mellanox/rping-test
name: mofed-test-ctr
securityContext:
capabilities:
add: [ "IPC_LOCK" ]
resources:
limits:
rdma/hpc_shared_devices_ens13f1np1: 1 # 申请硬件资源
requests:
rdma/hpc_shared_devices_ens13f1np1: 1
command:
- sh
- -c
- |
ls -l /dev/infiniband /sys/class/infiniband /sys/class/net
sleep 1000000
---
apiVersion: v1
kind: Pod
metadata:
name: test-pod2
annotations:
k8s.v1.cni.cncf.io/networks: ipoib-conf
spec:
restartPolicy: OnFailure
containers:
- image: mellanox/rping-test
name: mofed-test-ctr
securityContext:
capabilities:
add: [ "IPC_LOCK" ]
resources:
limits:
rdma/hpc_shared_devices_ens13f1np1: 1 # 申请硬件资源
requests:
rdma/hpc_shared_devices_ens13f1np1: 1
command:
- sh
- -c
- |
ls -l /dev/infiniband /sys/class/infiniband /sys/class/net
sleep 1000000
参考
k8s RoCE 部署: k8s-rdma-shared-dev-plugin + macvlan cni_rdma shared dev plugin-CSDN博客
Container Runtime CDI与NRI介绍-阿里云开发者社区
【网络技术】什么是CNI-阿里云开发者社区
kubernetes多网卡方案之Multus_CNI部署和基本使用_Kubernetes_琦彦_InfoQ写作社区
利用multus-cni和macvlan实现pod多网卡















 3302
3302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









