







目录
简介
zookeeper使用单一主进程Leader用于处理客户端所有事务请求,即写请求。当服务器数据发生变更后,集群采用ZAB原子广播协议,以事务提交proposal的形式广播到所有的副本进程,每一个事务分配 一个全局的递增的事务编号xid。
若客户端提交的请求为读请求时,则接受请求的节点直接根据自己保存的数据响应。若是写请求,且当 前节点不是leader,那么该节点就会将请求转发给leader,leader会以提案的方式广播此写请求,如果 超过半数的节点同意写请求,则该写请求就会提交。leader会通知所有的订阅者同步数据。
zookeeper的三种角色
为了避免zk的单点问题,zk采用集群方式保证zk高可用
-
leader
leader负责处理集群的写请求,并发起投票,只有超过半数的节点同意后才会提交该写请求
-
follower
处理读请求,响应结果。转发写请求到leader,在选举leader过程中参与投票
-
observer
observer可以理解为没有投票权的follower,主要职责是协助follower处理读请求。那么当整个zk 集群读请求负载很高时,为什么不增加follower节点呢?原因是增加follower节点会让leader在提 出写请求提案时,需要半数以上的follower投票节点同意,这样会增加leader和follower的通信通 信压力,降低写操作效率。
zookeeper两种模式
-
恢复模式
当服务启动或领导崩溃后,zk进入恢复状态,选举leader,leader选出后,将完成leader和其他机 器的数据同步,当大多数server完成和leader的同步后,恢复模式结束
-
广播模式
一旦Leader已经和多数的Follower进行了状态同步后,进入广播模式。进入广播模式后,如果有 新加入的服务器,会自动从leader中同步数据。leader在接收客户端请求后,会生成事务提案广播 给其他机器,有超过半数以上的follower同意该提议后,再提交事务。
注意在ZAB的事务的二阶段提交中,移除了事务中断的逻辑,follower要么ack,要么放弃,leader无需等待所有的follower的ack。
-
zxid
zxid是64位长度的Long类型,其中高32位表示纪元epoch,低32位表示事务标识xid。即zxid由两部分 构成:epoch和xid
每个leader都会具有不同的epoch值,表示一个纪元,每一个新的选举开启时都会生成一个新的 epoch,新的leader产生,会更新所有的zkServer的zxid的epoch,xid是一个依次递增的事务编号。
zookeeper节点类型
- PERSISTENT:永久节点。创建永久节点后,只有当节点被删除时它才会被删除。
- PERSISTENT_SEQUENTIAL:永久顺序节点。创建永久顺序节点后,节点名称会自动拼接一个递增的数字,形成一个唯一的节点路径。当节点被删除时,节点路径上的数字会被自动更新。
- EPHEMERAL:临时节点。临时节点只有在创建它的客户端与ZooKeeper进行连接时才存在。一旦客户端和ZooKeeper的连接断开,临时节点就会被删除。
- EPHEMERAL_SEQUENTIAL:临时顺序节点。临时顺序节点和临时节点类似,但是在节点名称后面会拼接一个递增的数字,形成一个唯一的节点路径。
leader选举算法
选取原则
-
zookeeper集群中 只有超过半数以上的服务器启动,集群才能正常工作
-
在集群在正常工作之前,myid小的服务器会给myid大的服务器进行投票,持续到集群正常工作,选出leader
-
选择leader之后,之前的服务器状态由looking改变为following,以后得服务器都是follower

启动过程
-
每一个server发出一个投票给集群中其他节点
-
收到各个服务器的投票后,判断该投票有效性,比如是否是本轮投票,是否是 looking状态
-
处理投票,pk别人的投票和自己的投票 比较规则xid>myid “取大原则”
-
统计是否超过半数的接受相同的选票
-
确认leader,改变服务器状态
-
添加新server,leader已经选举出来,只能以follower身份加入集群中
崩溃恢复过程
-
leader挂掉后,集群中其他follower会将状态从following变为looking,重新进入leader选举
-
同上启动过程
消息广播算法
一旦进入广播模式,集群中非leader节点接受到事务请求,首先会将事务请求转发给服务器,leader服 务器为其生成对应的事务提案proposal,并发送给集群中其他节点,如果过半则事务提交;
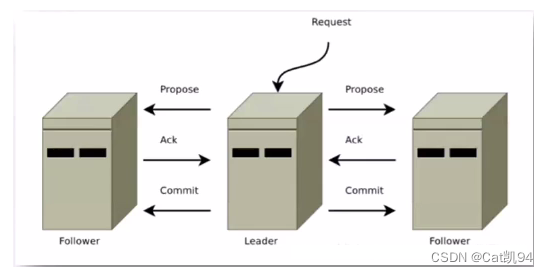
-
leader接受到消息后,消息通过全局唯一的64位自增事务id,zxid标识
-
leader发送给follower的提案是有序的,leader会创建一个FIFO队列,将提案顺序写入队列中发送 给follower
-
follower接受到提案后,会比较提案zxid和本地事务日志最大的zxid,若提案zxid比本地事务id 大,将提案记录到本地日志中,反馈ack给leader,否则拒绝
-
leader接收到过半ack后,leader向所有的follower发送commit,通知每个follower执行本地事务
API使用案例
| API | 功能 |
|---|---|
| ZooKeeper zk = new ZooKeeper(String connectString, int sessionTimeout,Watcher watcher) | 创建zookeeper连接,connectString表示连接的zookeeper服务器的 地址,sessionTimeOut指定会话的的超时时间,Watcher配置监听 |
| String create(String path, byte[] data, List acl,CreateMode createMode) | 创建一个给定的目录节点 path, 并给它设置数据,CreateMode 标识有 四种形式的目录节点,分别是 PERSISTENT:持久化目录节点,这个目 录节点存储的数据不会丢失;PERSISTENT_SEQUENTIAL:顺序自动编 号的目录节点,这种目录节点会根据当前已近存在的节点数自动加 1, 然后返回给客户端已经成功创建的目录节点名;EPHEMERAL:临时目 录节点,一旦创建这个节点的客户端与服务器端口也就是 session 超 时,这种节点会被自动删除;EPHEMERAL_SEQUENTIAL:临时自动编号节点 |
| Stat exists(String path, boolean watch) | 判断某个 path 是否存在,并设置是否监控这个目录节点,这里的 watcher 是在创建 ZooKeeper 实例时指定的 watcher,exists方法还 有一个重载方法,可以指定特定的watcher |
| Stat exists(String path,Watcher watcher) | 重载方法,这里给某个目录节点设置特定的 watcher,Watcher 在 ZooKeeper 是一个核心功能,Watcher 可以监控目录节点的数据变化 以及子目录的变化,一旦这些状态发生变化,服务器就会通知所有设置 在这个目录节点上的 Watcher,从而每个客户端都很快知道它所关注 的目录节点的状态发生变化,而做出相应的反应 |
| void delete(String path, int version) | 删除 path 对应的目录节点,version 为 -1 可以匹配任何版本,也就删 除了这个目录节点所有数据 |
| ListgetChildren(String path, boolean watch) | 获取指定 path 下的所有子目录节点,同样 getChildren方法也有一个 重载方法可以设置特定的 watcher 监控子节点的状态 |
| Stat setData(String path, byte[] data, intversion) | 给 path 设置数据,可以指定这个数据的版本号,如果 version 为 -1 怎可以匹配任何版本 |
| byte[] getData(String path, boolean watch,Stat stat) | 获取这个 path 对应的目录节点存储的数据,数据的版本等信息可以通 过 stat 来指定,同时还可以设置是否监控这个目录节点数据的状态 |
-
引入依赖
<!--zookeeper--> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>3.4.13</version> </dependency> <!--junit4--> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency>
-
测试类
public class zkApiTest {
private static final String connectString = "192.168.193.XXX:2181";//默认端口2181
private static final int sessionTimeout = 2000;
private static ZooKeeper zk = null;
@Before
public void init() throws IOException {
// //创建zookeeper的连接
zk = new ZooKeeper(connectString,sessionTimeout,(e)->{
System.out.println("触发了"+e.getType()+"事件");//Watcher
});
}
@Test
public void testZkApi() throws KeeperException, InterruptedException {
// 创建父节点
String path = zk.create("/testFather", "v1".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("创建父节点:"+path);
//创建子节点
String childrenPath = zk.create("/testFather/children", "v2".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("创建子节点:"+childrenPath);
//判断节点是否存在 如果指定路径的节点存在返回节点的状态,如果节点不存在返回null
Stat exists = zk.exists("/testFather", true);
System.out.println("判断/testFather节点是否存在:"+exists);
//获取指定路径下的所有子节点的名称
List<String> children = zk.getChildren("/testFather", true);
for (int i = 0; i < children.size(); i++) {
String node = children.get(i);
System.out.println(node);
}
//设置节点的数据
Stat stat1 = zk.setData("/testFather/children", "update".getBytes(), -1);
System.out.println("/testFather/children节点数据为:"+stat1);
//获取节点的数据
byte[] data = zk.getData("/testFather/children", true, new Stat());
System.out.println("/testFather/children节点数据为:"+new String(data));
//删除节点
zk.delete("/testFather/children",-1);
//判断节点是否存在 如果指定路径的节点存在返回节点的状态,如果节点不存在返回null
Stat exists1 = zk.exists("/testFather/children", true);
System.out.println("判断/testFather/children节点是否存在:"+exists1);
}
}
-
运行结果
触发了None事件 创建父节点:/testFather 创建子节点:/testFather/children 判断/testFather节点是否存在:4294967365,4294967365,1681723459811,1681723459811,0,1,0,0,2,1,4294967366 children /testFather/children节点数据为:4294967366,4294967367,1681723459828,1681723459872,1,0,0,0,6,0,4294967366 /testFather/children节点数据为:update 触发了NodeDeleted事件 触发了NodeChildrenChanged事件 判断/testFather/children节点是否存在:null
应用场景
配置中心
在平常的业务开发过程中,我们通常需要将系统的一些通用的全局配置,例如机器列表配置,运行时开 关配置,数据库配置信息等统一集中存储,让集群所有机器共享配置信息,系统在启动会首先从配置中 心读取配置信息,进行初始化。传统的实现方式将配置存储在本地文件和内存中,一旦机器规模更大, 配置变更频繁情况下,本地文件和内存方式的配置维护成本较高,使用zookeeper作为分布式的配置中 心就可以解决这个问题。
我们将配置信息存在zk中的一个节点中,同时给该节点注册一个数据节点变更的watcher监听,一旦节点数据发生变更,所有的订阅该节点的客户端都可以获取数据变更通知
负载均衡
建立server节点,并建立监听器监视servers子节点的状态(用于在服务器增添时及时同步当前集群中服务器列表)。在每个服务器启动时,在servers节点下建立具体服务器地址的子节点,并在对应的字节点 下存入服务器的相关信息。这样,我们在zookeeper服务器上可以获取当前集群中的服务器列表及相关 信息,可以自定义一个负载均衡算法,在每个请求过来时从zookeeper服务器中获取当前集群服务器列表,根据算法选出其中一个服务器来处理请求。

命名服务
命名服务是分布式系统中的基本功能之一。被命名的实体通常可以是集群中的机器、提供的服务地址或 者远程对象,这些都可以称作为名字。常见的就是一些分布式服务框架(RPC、RMI)中的服务地址列 表,通过使用名称服务客户端可以获取资源的实体、服务地址和提供者信息。命名服务就是通过一个资 源引用的方式来实现对资源的定位和使用。在分布式环境中,上层应用仅仅需要一个全局唯一名称,就 像数据库中的主键。 在单库单表系统中可以通过自增ID来标识每一条记录,但是随着规模变大分库分表很常见,那么自增ID 有仅能针对单一表生成ID,所以在这种情况下无法依靠这个来标识唯一ID。UUID就是一种全局唯一标识符。但是长度过长不易识别。

-
在Zookeeper中通过创建顺序节点就可以实现,所有客户端都会根据自己的任务类型来创建一个顺 序节点,例如 job-00000001
-
节点创建完毕后,create()接口会返回一个完整的节点名,例如:job-00000002
-
拼接type类型和完整节点名作为全局唯一的ID
-
DNS服务
-
域名配置
在分布式系统应用中,每一个应用都需要分配一个域名,日常开发中,往往使用本地HOST绑定域名解析,开发阶段可以随时修改域名和IP的映射,大大提高开发的调试效率。如果应用的机器规模达到一定程度后,需要频繁更新域名时,需要在规模的集群中变更,无法保证实时性。所有我们在zk上创建一个节点来进行域名配置
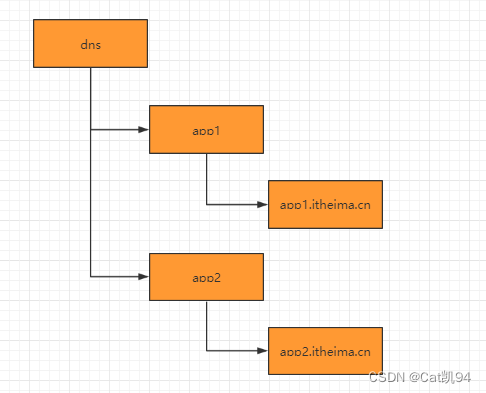
-
域名解析
应用解析时,首先从zk域名节点中获取域名映射的IP和端口。 无需手动映射
-
域名变更
每个应用都会在在对应的域名节点注册一个数据变更的watcher监听,一旦监听的域名节点数据变更,zk会向所有订阅的客户端发送域名变更通知,保证实时性
集群管理
随着分布式系统规模日益扩大,集群中机器的数量越来越多。有效的集群管理越来越重要了, zookeeper集群管理主要利用了watcher机制和创建临时节点来实现。(传统的agent集群弊端:大规模升级困难,编程语言多样性)以机器上下线和机器监控为例:

-
机器上下线
新增机器的时候,将Agent部署到新增的机器上,当Agent部署启动时,会向zookeeper指定的节 点下创建一个临时子节点,当Agent在zk上创建完这个临时节点后,当关注的节点 zookeeper/machines下的子节点新加入新的节点时或删除都会发送通知,这样就对机器的上下线进行监控。

-
机器监控
在机器运行过程中,Agent会定时将主机的的运行状态信息写入到/machines/hostn主机节点,监控中心通过订阅这些节点的数据变化来获取主机的运行信息。
分布式锁
-
数据库实现分布式锁
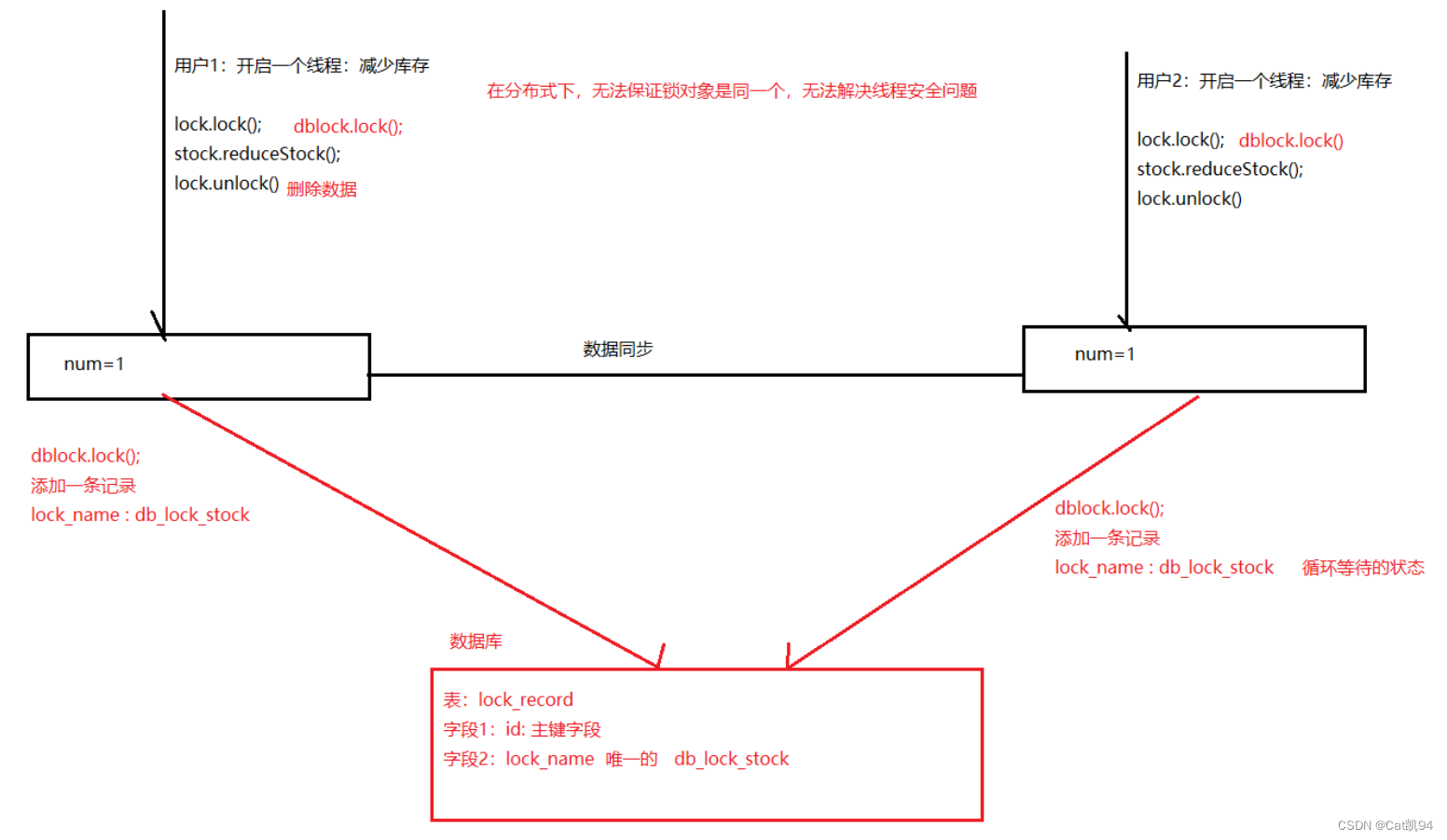
-
redis实现分布式锁
redis实现分布式锁存在的问题,为了解决redis单点问题,我们会部署redis集群,在 Sentinel 集群中, 主节点突然挂掉了。同时主节点中有把锁还没有来得及同步到从节点。这样就会导致系统中同样一把锁 被两个客户端同时持有,不安全性由此产生。redis官方为了解决这个问题,推出了Redlock 算法解决这个问题。但是带来的网络消耗较大。
-
zookeeper实现分布式锁
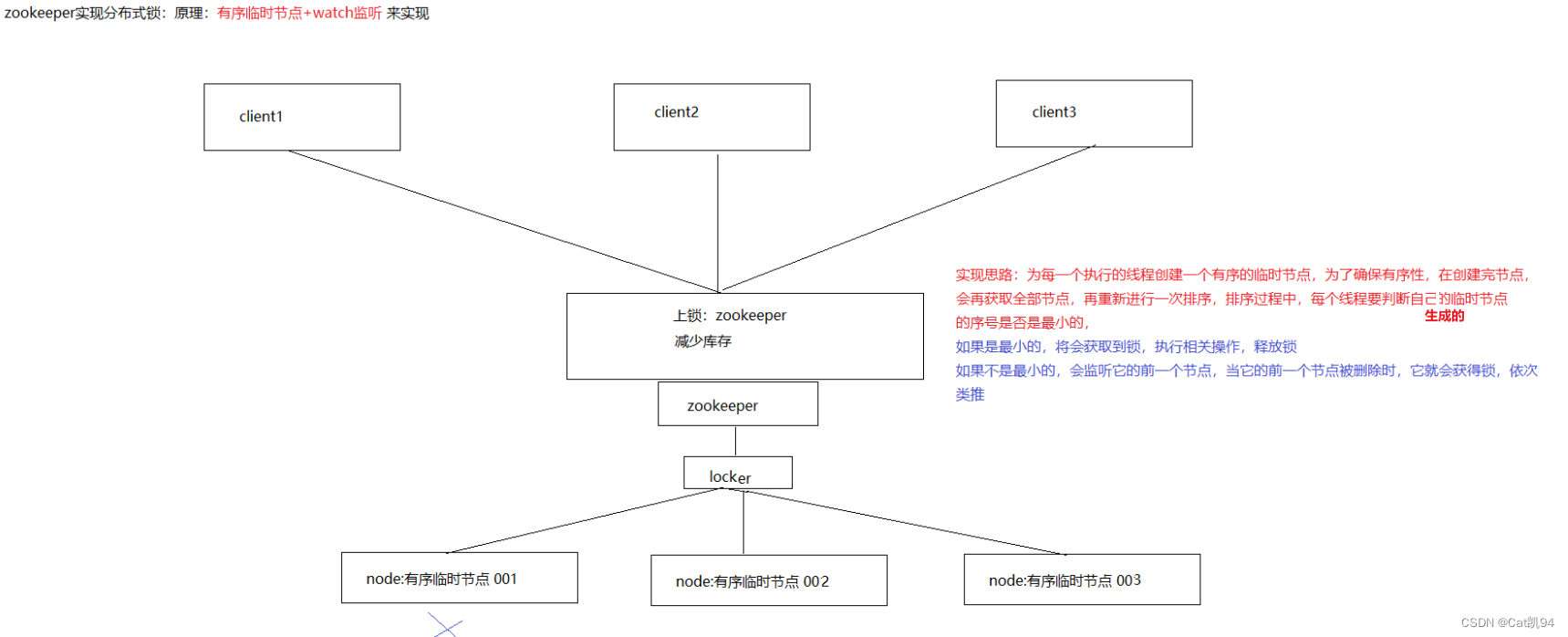
原理:zookeeper通过创建临时序列节点来实现分布式锁,适用于顺序执行的程序,大体思路就是创建 临时序列节点,找出最小的序列节点,获取分布式锁,程序执行完成之后此序列节点消失,通过watch 来监控节点的变化,从剩下的节点的找到最小的序列节点,获取分布式锁,执行相应处理,依次类推…… 原生实现 首先在ZkLock的构造方法中,连接zk,创建lock根节点
基于curator实现分布式锁:
maven依赖
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>4.0.0</version> </dependency>
锁操作
//创建zookeeper的客户端
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
//集群通过,分割
CuratorFramework client =CuratorFrameworkFactory.newClient("127.0.0.1:2181", retryPolicy);
client.start();
//创建分布式锁, 锁空间的根节点路径为/curator/lock
InterProcessMutex mutex = new InterProcessMutex(client, "/curator/lock");
//获得了锁, 进行业务流程 ......
mutex.acquire();
//完成业务流程, 释放锁
mutex.release();
//关闭客户端
client.close();
分布式队列
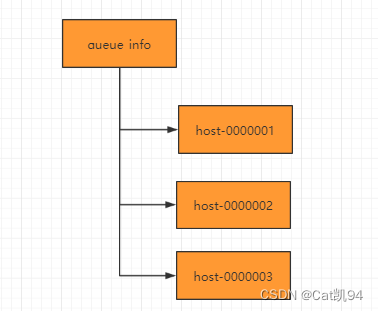
-
在队列节点下创建临时顺序节点 例如/queue_info/192.168.1.1-0000001
-
调用getChildren()接口来获取/queue_info节点下所有子节点,获取队列中所有元素
-
比较自己节点是否是序号最小的节点,如果不是,则等待其他节点出队列,在序号最小的节点注册 watcher
-
获取watcher通知后,重复步骤
















 774
774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









