




深入解析 Linux Cache Line 的原理、价值及 MIPS CPU 处理机制
摘要:本文深度剖析现代处理器(以 MIPS/x86 为例)的 Cache Line 机制。从硬件物理结构、MESI 一致性协议、内存读取全流程到软件层面的性能优化技巧,结合专业图表与实测代码,为开发者提供一份关于缓存优化的权威指南。
1. Cache Line 基础概念
1.1 定义与物理结构
Cache Line(缓存行)是 CPU Cache 与主内存之间进行数据交换的最小单位。
在现代主流处理器中(如 x86_64, ARM Cortex-A, MIPS64),Cache Line 的大小通常为 64 字节(部分旧架构可能为 32 字节)。这意味着,即使 CPU 只需要读取一个字节(char),硬件也会一次性将包含该字节的整个 64 字节块从内存加载到 Cache 中。
物理映射机制
物理内存地址在被 Cache 控制器解析时,会被划分为三个部分:Tag(标记)、Index(索引)和Offset(偏移)。
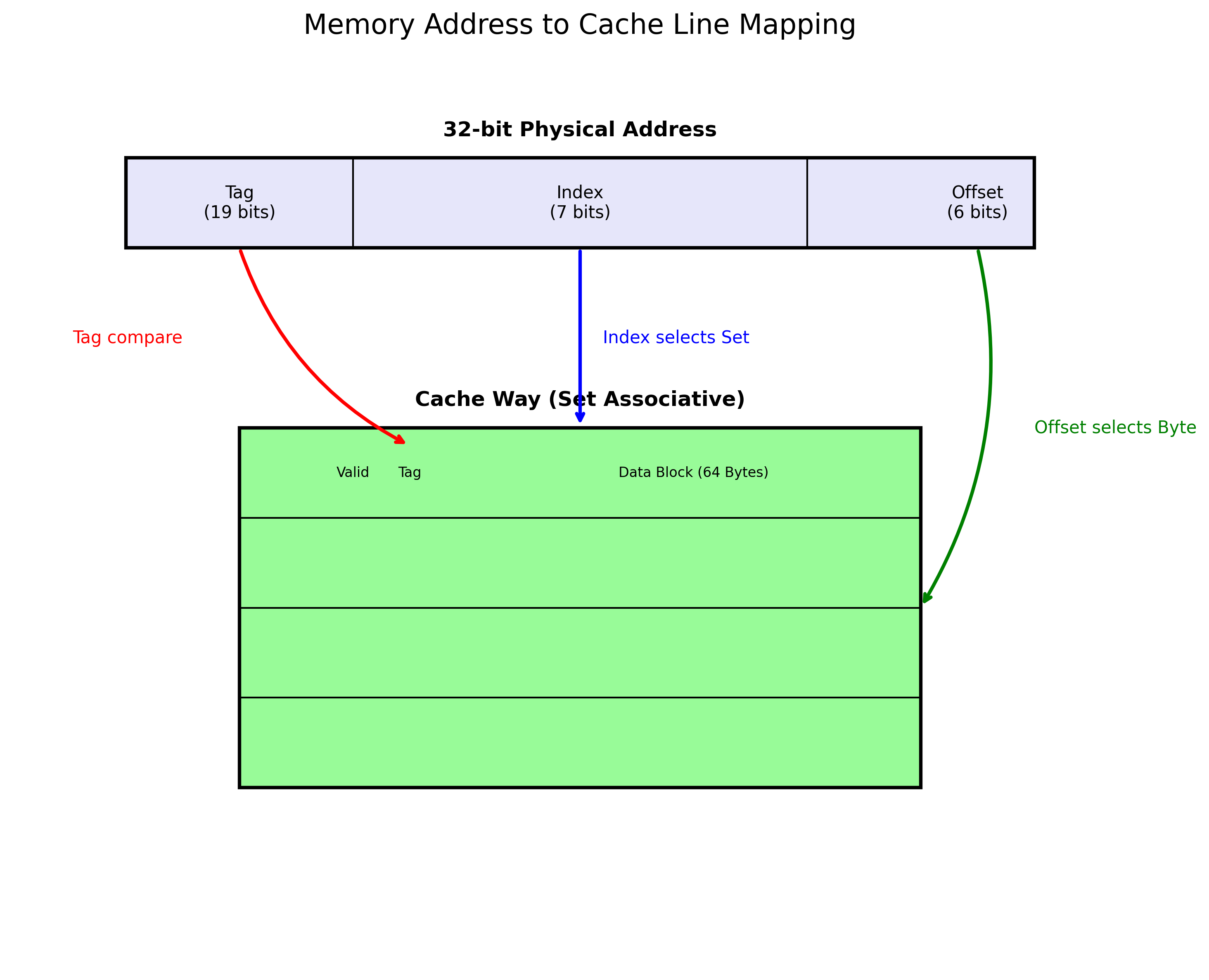
图 1:内存地址到 Cache Line 的映射关系
- Tag (19 bits):用于区分映射到同一 Cache Set 中的不同内存块。
- Index (7 bits):用于定位 Cache 中的 Set(组)。例如 32KB L1 Cache,64B Line,8-Way 组相联,则 Index 需要 log2(32768/64/8)=6\log_2(32768 / 64 / 8) = 6log2(32768/64/8)=6 位(示意图中为简化展示)。
- Offset (6 bits):用于在 64 字节的 Data Block 中定位具体字节。
三级缓存结构
- L1 Cache:通常分为 L1i (Instruction) 和 L1d (Data),每核独享,延迟约 3-4 周期。
- L2 Cache:通常每核独享或共享,容量更大,延迟约 10-20 周期。
- L3 Cache (LLC):多核共享,容量可达数 MB,延迟约 40-60 周期。
1.2 价值体现
时空局部性原理 (Locality)
- 时间局部性:如果一个数据项被访问,它很快可能被再次访问(如循环变量)。
- 空间局部性:如果一个数据项被访问,与其相邻的数据项可能很快被访问(如数组遍历)。Cache Line 的 64 字节设计正是为了利用空间局部性。
关键结论:90% 的程序执行时间消耗在 10% 的代码和数据上。
性能对比数据
| 存储层级 | 大小 | 典型延迟 (时钟周期) | 典型延迟 (纳秒 @ 3GHz) |
|---|---|---|---|
| L1 Cache | 32KB - 64KB | 4 | ~1.3 ns |
| L2 Cache | 256KB - 1MB | 12 | ~4 ns |
| L3 Cache | 8MB - 32MB | 40 | ~13 ns |
| 主内存 (DRAM) | 16GB - 128GB | >200 | ~100 ns |
注:Cache Miss 导致的 DRAM 访问比 L1 命中慢约 100 倍。
2. CPU 读取处理全流程
2.1 读取阶段
当 CPU 核心执行一条 LOAD 指令(如 LW - Load Word)时,硬件将经历以下漫长的查询路径:
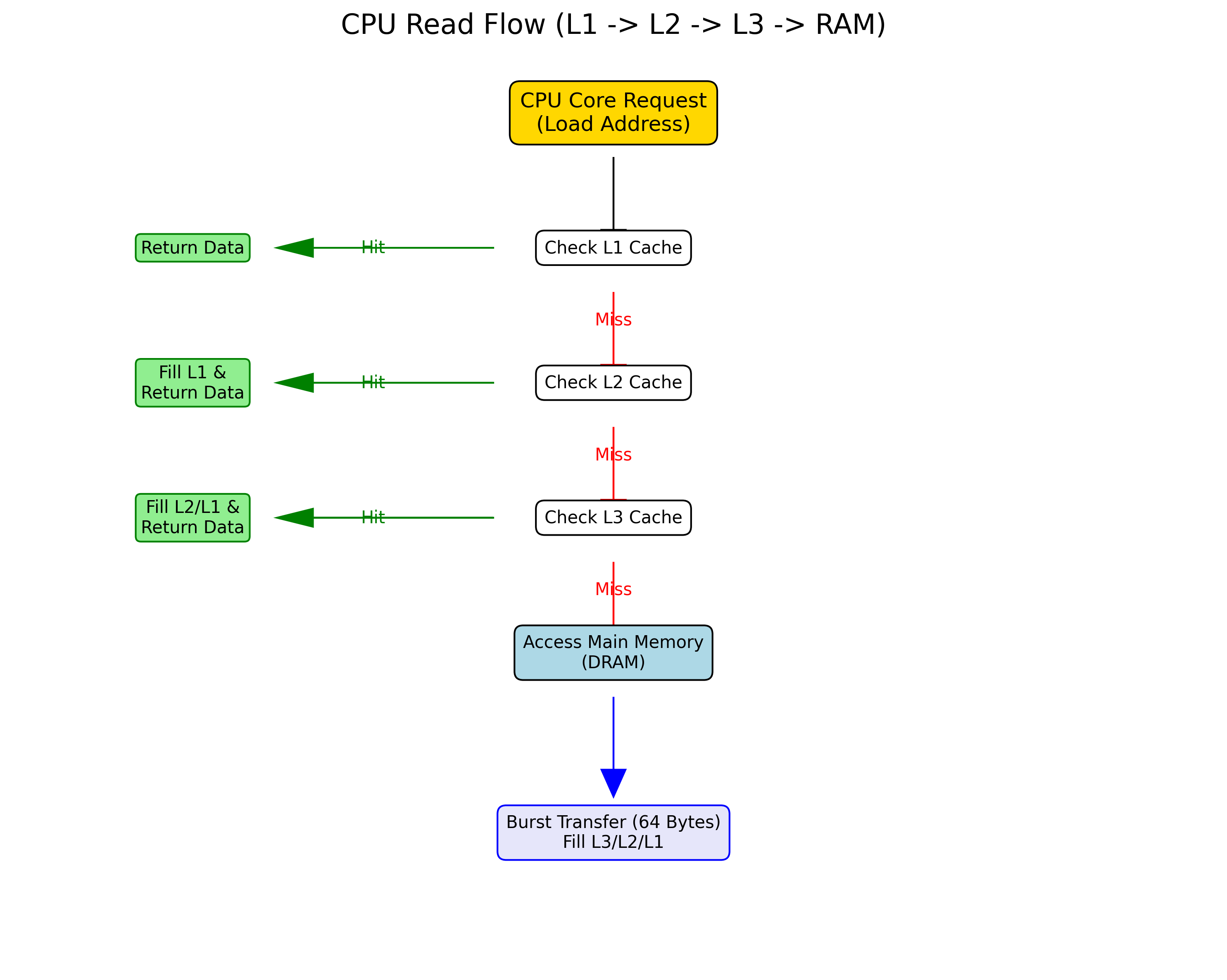
图 2:CPU 核心发起 Load 指令后的查询路径
关键控制寄存器
在 x86 架构中,CR0 寄存器包含控制缓存行为的位:
- CD (Cache Disable):置 1 时禁用缓存。
- NW (Not Write-through):控制写策略。
在 MIPS 架构中,Config寄存器(CP0 Register 16)的 K0 字段控制 kseg0 区域的缓存属性(如 Write-back vs Uncached)。
思考:CPU 读取到一个 Cache Line 的数据后,如何处理?
CPU 内部并没有 64 字节宽的通用寄存器来一次性存储整个 Cache Line。
- 加载到 Cache Bank:整个 64 字节被写入 L1 Cache 的 Data Array。
- 提取目标字:根据地址的 Offset,多路选择器(Mux)从 Cache Line 中选出 CPU 请求的那 4 字节(或 8 字节)。
- 写入寄存器:最终只有这 4 字节被写入通用寄存器(如 MIPS 的
$t0或 x86 的RAX)。
2.2 命中处理 (Cache Hit)
当数据在 L1 Cache 中找到且 Tag 匹配、Valid 位有效时:
- 数据路径:Cache Controller 直接从 SRAM 阵列读取数据,旁路传输给 CPU 流水线。
- MESI 状态更新:根据操作类型(读/写),更新 Cache Line 的状态。
MESI 协议状态机
多核一致性通过 MESI 协议维护,Cache Line 处于以下四种状态之一:
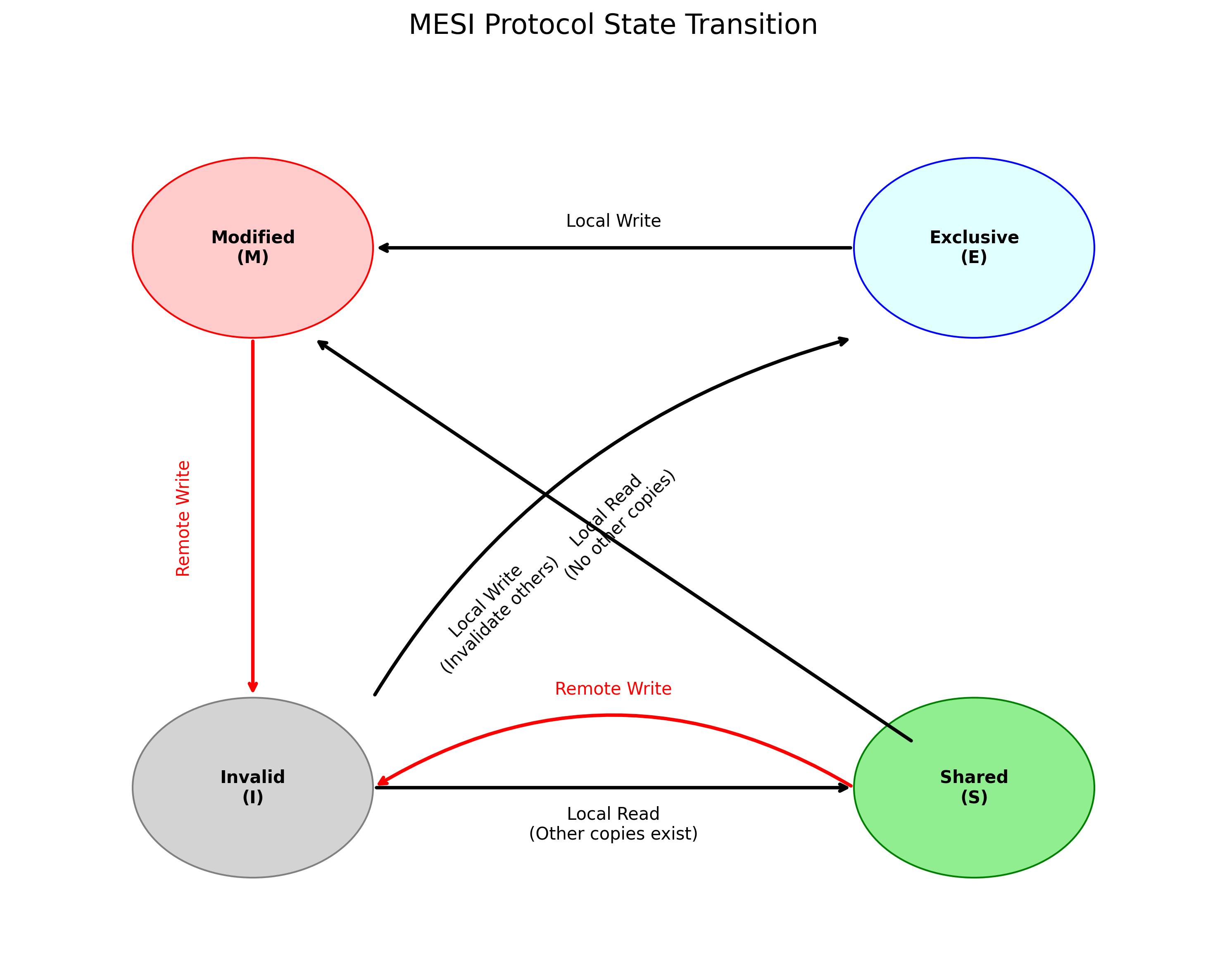
图 3:MESI 协议状态转换示意图
- Modified (M):已修改,与内存不一致(Dirty),当前核独占。
- Exclusive (E):未修改,与内存一致,当前核独占。
- Shared (S):未修改,与内存一致,多个核共享。
- Invalid (I):数据无效。
2.3 未命中处理 (Cache Miss)
缓存行填充 (Line Fill)
当发生 Cache Miss 时,CPU 必须从主内存读取数据。内存控制器使用 Burst Transfer(突发传输) 模式。
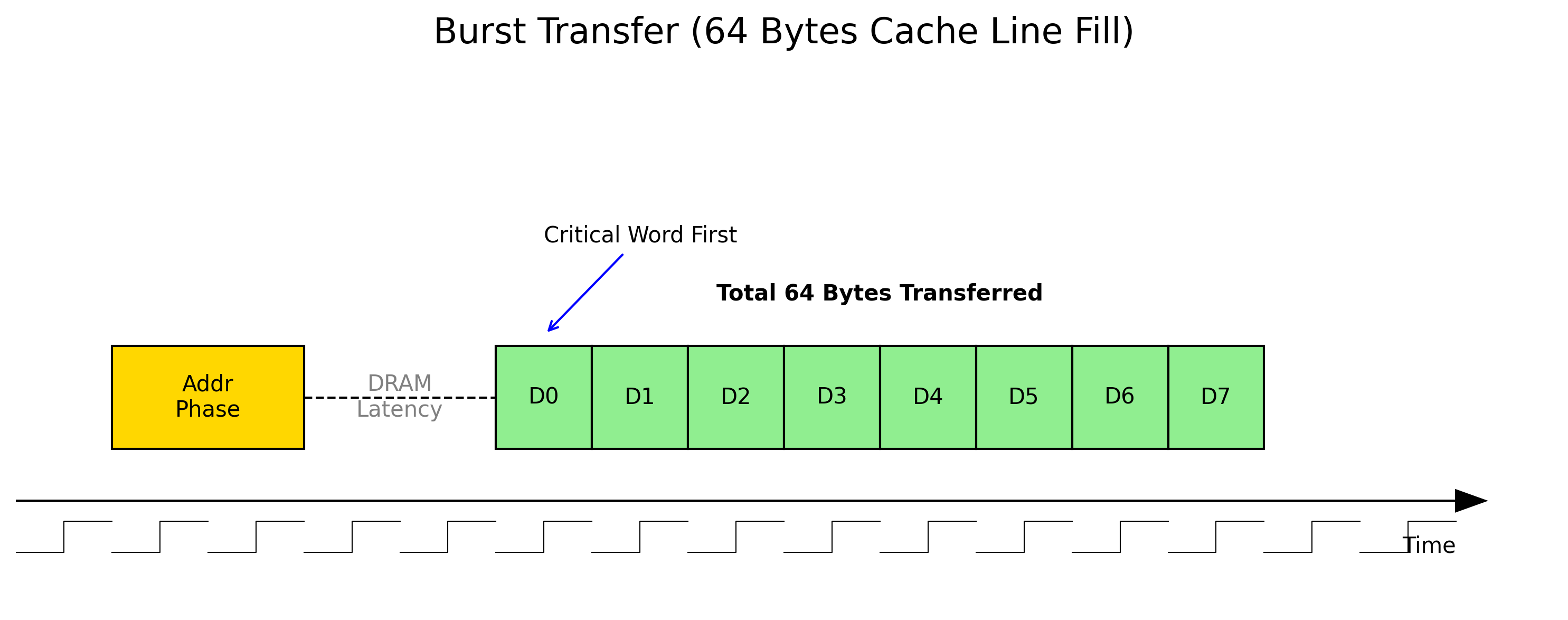
图 4:64 字节 Cache Line 的 Burst 传输过程
- Critical Word First:CPU 请求的那个字(Critical Word)会被最先传输并送给 CPU,以便流水线尽快恢复执行,随后再填充 Cache Line 的其余部分。
替换算法
当 Cache Set 已满时,必须驱逐一行。
- LRU (Least Recently Used):硬件维护访问历史位,驱逐最久未使用的行。
- Pseudo-LRU / NRU:近似算法,减少硬件开销。
3. 数据存储位置详解
3.1 缓存层次结构
数据存放规则
物理地址经过哈希算法(通常利用高位地址异或)分布到不同的 Cache Slice(在多核 Ring Bus 架构中)。
多核一致性与 Home Agent
- Home Agent (HA):负责管理特定内存地址范围的一致性。
- Ring Bus / Mesh:连接所有核心、LLC Slice 和内存控制器的片上网络。
3.2 特殊场景处理
非对齐访问 (Unaligned Access)
如果一个 4 字节整数跨越了两个 Cache Line(例如地址 0x3F,跨越 0x00-0x3F 和 0x40-0x7F):
- 硬件代价:CPU 需要发起两次 Cache 访问(甚至两次内存 Burst),并在内部拼接数据。
- 原子性丧失:跨行的原子操作(
LOCK前缀或LL/SC)可能导致总线锁死或异常。
预取机制 (Prefetching)
- 硬件预取 (Hardware Prefetcher):检测到连续的步幅(Stride)访问模式时,自动加载后续 Cache Line。
- 软件预取:程序员使用
__builtin_prefetch()或汇编指令PREFETCH显式告知 CPU。
4. 性能优化实践
4.1 编程建议
伪共享 (False Sharing)
当两个线程分别修改不同变量,但这两个变量位于同一个 Cache Line 时,会导致核心间频繁发生 MESI 协议的 Invalidation,严重降低性能。
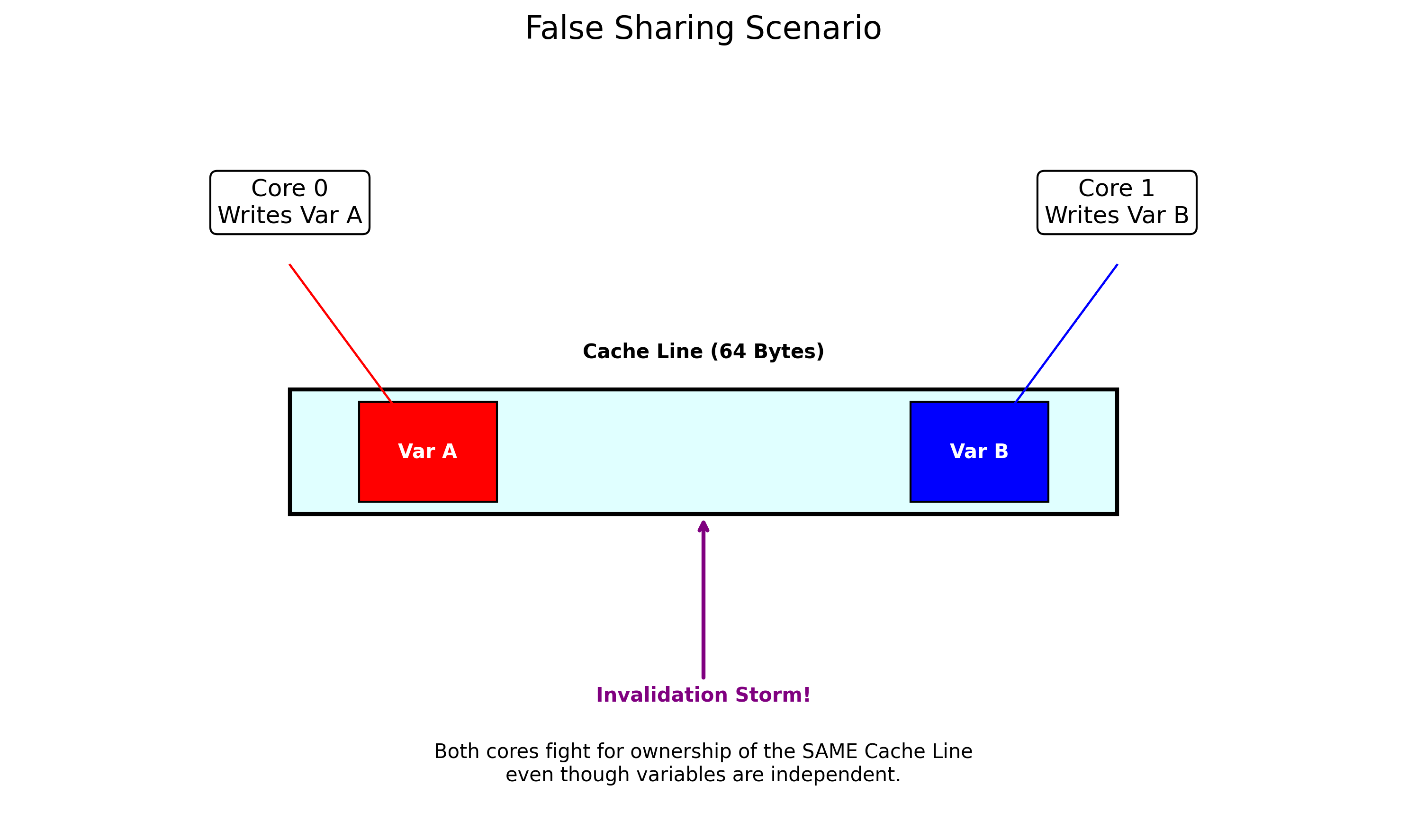
图 5:伪共享导致的性能陷阱
解决方案:Padding
struct Optimized {
long a;
char padding[64]; // 强制隔离到不同 Cache Line
long b;
};
结构体对齐
确保关键数据结构对齐到 Cache Line 边界,避免跨行访问。
// 强制结构体起始地址 64 字节对齐
struct __attribute__((aligned(64))) AlignedData {
int id;
float value;
// ...
};
4.2 监控工具
Linux Perf
使用 perf 工具分析缓存未命中率:
# 监控 L1 数据缓存未命中
perf stat -e L1-dcache-load-misses ./my_program
# 监控最后一级缓存(LLC)未命中
perf stat -e LLC-load-misses ./my_program
Intel VTune / AMD uProf
图形化工具可以精确定位到源代码中导致 Cache Miss 的具体行。
5. 附录
资源下载
- Cache 优化示例代码 (cache_examples.zip)
matrix_align.c: 矩阵行优先 vs 列优先访问性能对比。false_sharing.c: 多线程伪共享演示。struct_align.c: 结构体对齐示例。
参考文献
- Computer Architecture: A Quantitative Approach
- See MIPS Run Linux
- Intel® 64 and IA-32 Architectures Optimization Reference Manual

















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









