 Cache Line与内存对齐引发的Bus Error
Cache Line与内存对齐引发的Bus Error





深入解析Linux缓存行(Cache Line)与内存不对齐引发的Bus Error硬件异常
目录
- 技术背景说明
- 现代CPU缓存架构
- 内存对齐基本原理
- 缓存行与内存不对齐的冲突机制
- 缓存加载过程与Split Access
- 硬件异常触发条件
- Linux下的具体案例分析
- 典型错误场景
- 内核相关处理机制
- 问题诊断与解决方案
- 诊断工具
- 解决方案与最佳实践
- 总结
- 参考文献
1. 技术背景说明
1.1 现代CPU缓存架构
现代处理器为了缓解CPU核心频率与主存访问速度之间的巨大鸿沟,引入了多级缓存(Cache)体系。
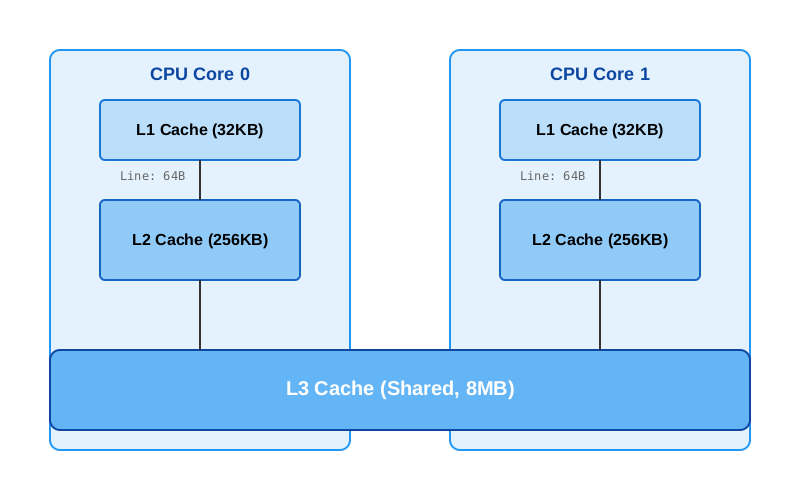
图1:现代多核CPU的三级缓存结构(L1/L2/L3)
- L1 Cache (一级缓存):分为指令缓存(I-Cache)和数据缓存(D-Cache),通常每核独占,大小约32KB-64KB。
- L2 Cache (二级缓存):通常每核独占或共享,大小约256KB-1MB。
- L3 Cache (三级缓存):多核共享,大小可达数MB甚至数十MB。
**缓存行(Cache Line)**是缓存与主存交换数据的最小单位。
- 典型大小:
- x86_64: 64 Bytes
- ARMv7/v8: 32 Bytes 或 64 Bytes
- MIPS: 32 Bytes
内存地址被映射到缓存行中,通常采用**组相联(Set Associative)**映射方式。
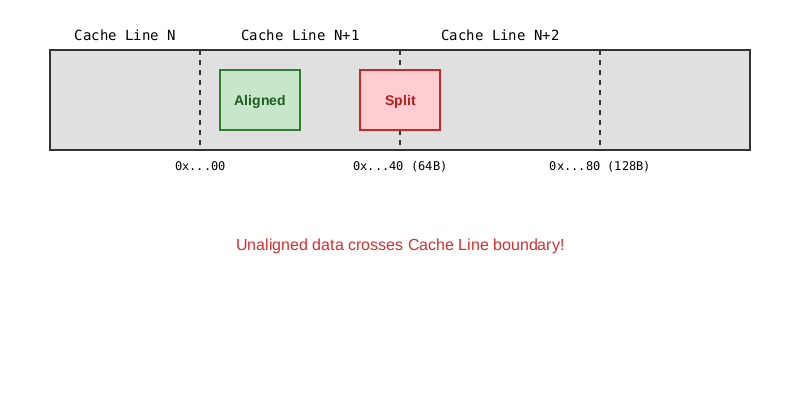
图2:缓存行在内存中的映射关系
1.2 内存对齐基本原理
**内存对齐(Memory Alignment)**是指数据在内存中的起始地址是其数据类型大小的整数倍。
- 自然对齐规则:
uint8_t(1 byte): 任意地址。uint16_t(2 bytes): 地址 % 2 == 0。uint32_t(4 bytes): 地址 % 4 == 0。uint64_t(8 bytes): 地址 % 8 == 0。
结构体填充(Padding):
编译器为了保证成员对齐,会在结构体成员之间插入填充字节。
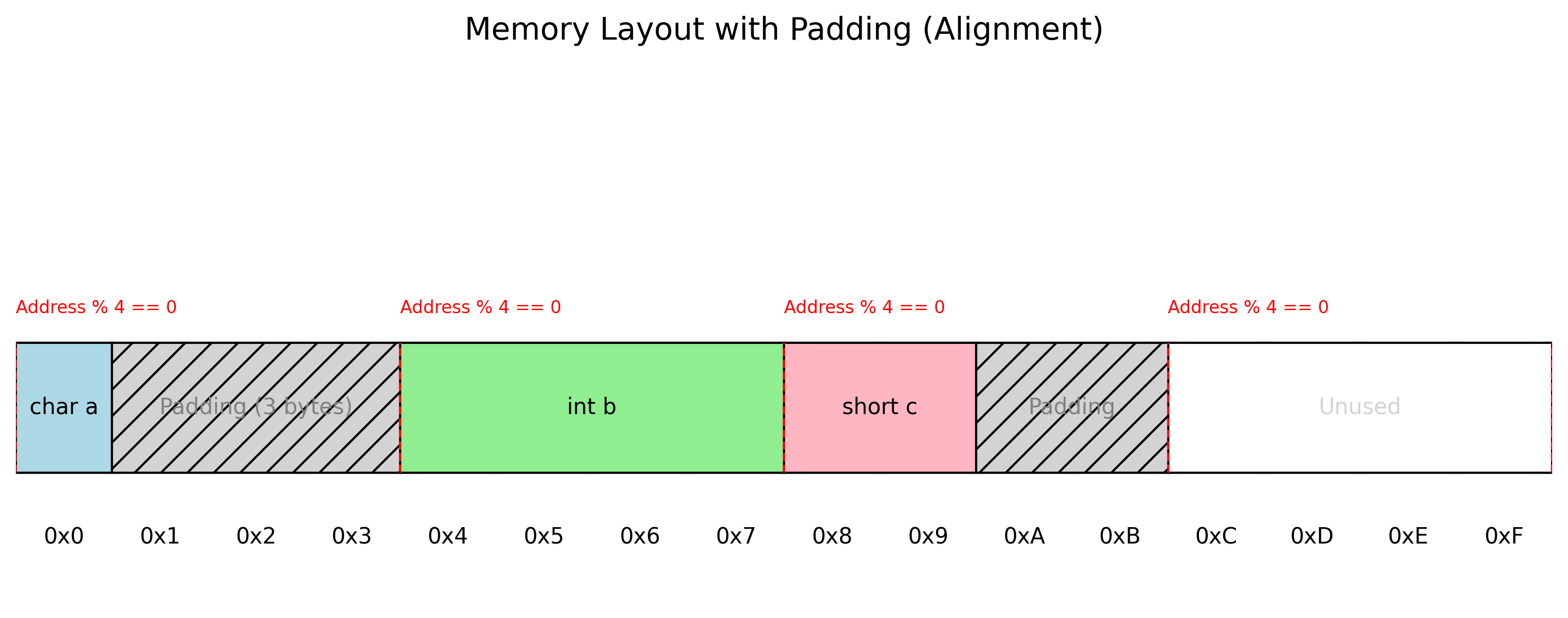
图3:结构体内存布局与填充示意图
2. 缓存行与内存不对齐的冲突机制
2.1 缓存加载过程与Split Access
当CPU发起一个内存访问请求时,硬件会首先检查数据是否在L1 Cache中。
- 对齐访问 (Aligned Access):数据完全落在一个缓存行内。CPU只需加载该行即可获取数据,通常在一个时钟周期内完成(若L1命中)。
- 非对齐访问 (Unaligned Access):如果数据跨越了两个缓存行的边界,这被称为Split Access。
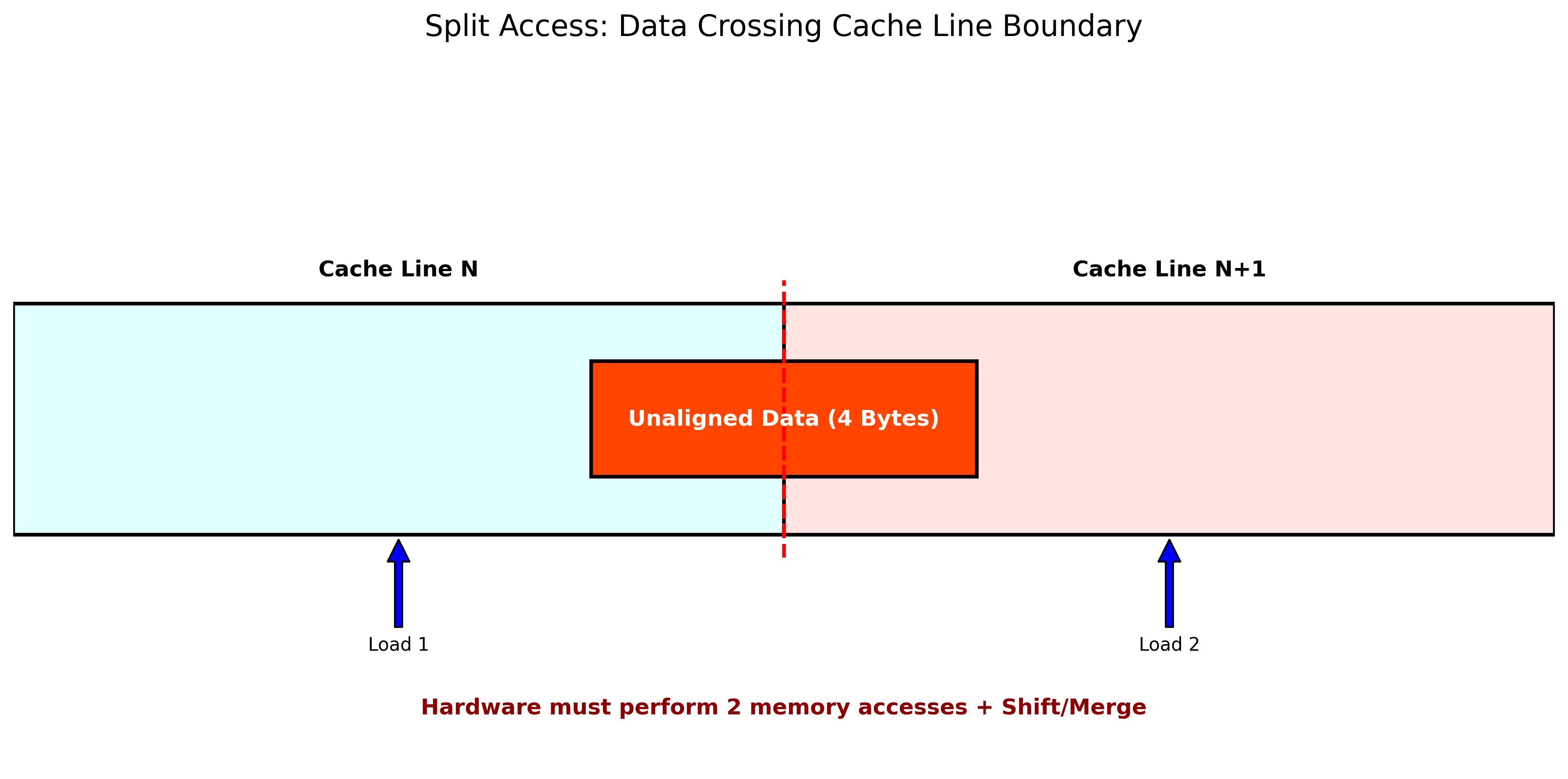
图4:跨缓存行访问的分解操作(Split Access)
硬件处理流程:
- CPU检测到访问跨越了缓存行边界。
- 硬件分别发起两次缓存加载请求(Load Line N 和 Load Line N+1)。
- 将两部分数据在内部寄存器或总线接口单元中进行拼接(Shift & Merge)。
- 这会导致显著的性能惩罚(至少两倍延迟),且缺乏原子性。
2.2 硬件异常触发条件
并非所有CPU都能自动处理非对齐访问。
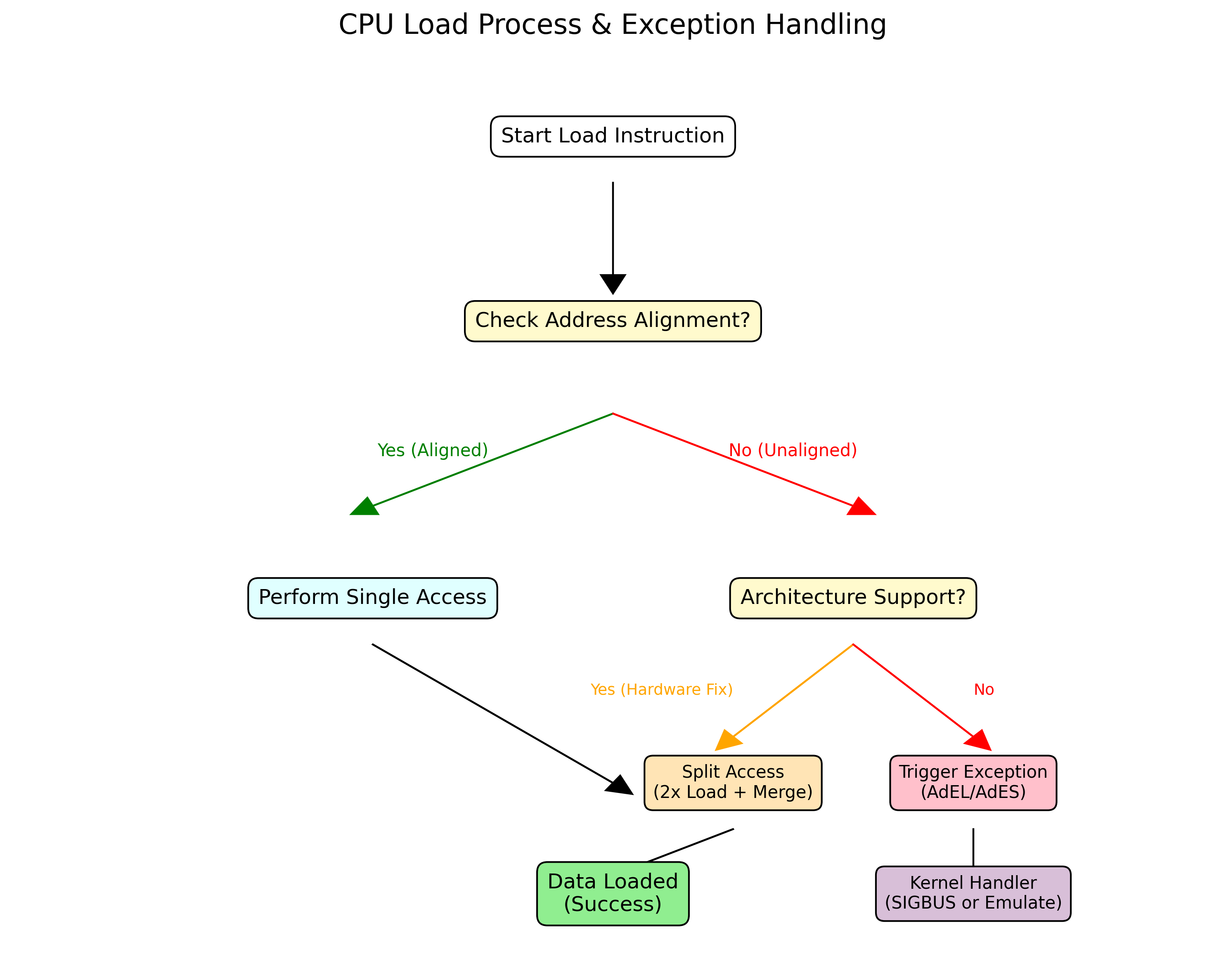
图5:CPU加载过程与异常触发条件
- x86/x64:硬件自动处理大部分非对齐访问(性能有损),但某些SIMD指令(如SSE/AVX的
MOVAPS)要求严格对齐,否则抛出#GP异常。 - ARMv7/v8:支持普通指令的非对齐访问,但
LDM/STM(多重加载/存储)或原子指令(LDREX/STREX)要求对齐。 - MIPS/SPARC:传统上不支持非对齐访问。一旦地址未对齐,CPU立即触发 Address Error Exception (AdEL/AdES)。Linux内核会捕获该异常并发送 SIGBUS 信号。
3. Linux下的具体案例分析
3.1 典型错误场景
场景一:指针强制类型转换
这是导致Bus Error最常见的原因。将一个 char* 强制转换为 int*,而该地址未对齐。
// 错误示例
char buffer[10];
// 假设 buffer 地址为 0x1001
char *ptr = buffer + 1;
// 强制转换为 int*,地址 0x1002 不是 4 的倍数
int *bad_ptr = (int*)ptr;
*bad_ptr = 0xDEADBEEF; // MIPS/SPARC 上触发 SIGBUS
场景二:Packed结构体定义不当
使用 __attribute__((packed)) 会移除填充,导致成员未对齐。
struct __attribute__((packed)) Packet {
char flags; // 1 byte
int seq_num; // offset 1 (未对齐!)
};
struct Packet pkt;
// 编译器可能会生成逐字节访问代码,但在某些情况下(如取地址传递)仍可能出错
int *pSeq = &pkt.seq_num; // pSeq 是未对齐指针
3.2 内核相关处理机制
当硬件触发对齐异常时,Linux内核的异常处理流程如下:
- 异常入口:CPU跳转到异常向量表(如MIPS的
handle_adel)。 - 内核捕获:内核判断是否为对齐错误。
- 模拟执行 (Emulation):
- 如果配置了
CONFIG_MIPS_EMULATE_UNALIGNED(或类似选项),内核会尝试用软件模拟该指令(读取两个字并拼接)。 - 这非常慢!且会通过
dmesg打印警告(unaligned access at ...)。
- 如果配置了
- 发送信号:
- 如果未配置模拟,或通过
/proc接口禁用了模拟,内核调用force_sig(SIGBUS, current)。 - 用户进程收到 SIGBUS,通常默认行为是 Core Dump。
- 如果未配置模拟,或通过
内核配置:
CONFIG_HAVE_EFFICIENT_UNALIGNED_ACCESS:定义了架构是否支持高效的硬件非对齐访问。/proc/sys/kernel/ignore-unaligned-usertrap:控制是否记录非对齐访问日志。
4. 问题诊断与解决方案
4.1 诊断工具
- Perf:监控对齐故障事件。
perf stat -e alignment-faults ./my_app - Wcast-align:GCC编译警告。
警告:cast increases required alignment of target typegcc -Wcast-align -o app app.c - dmesg:查看内核日志。
dmesg | grep "unaligned"
4.2 解决方案与最佳实践
1. 使用 memcpy (推荐)
这是最安全、移植性最好的方法。编译器会将定长 memcpy 优化为高效的指令。
int val;
memcpy(&val, unaligned_ptr, sizeof(int));
2. 编译器属性 aligned
确保变量或结构体按缓存行对齐,避免 False Sharing 和 Split Access。
struct Data {
int x;
int y;
} __attribute__((aligned(64))); // 对齐到64字节(常见缓存行大小)
3. posix_memalign
动态分配内存时,使用 posix_memalign 替代 malloc,确保获得对齐的内存块(特别是用于SIMD或DMA时)。
void *ptr;
posix_memalign(&ptr, 64, 1024); // 分配1KB,地址64字节对齐
4. 结构体设计
按成员大小降序排列,既能节省空间(减少Padding),又能自然对齐。
// 好的设计
struct Good {
long a; // 8 bytes
int b; // 4 bytes
char c; // 1 byte
// 3 bytes padding
};
5. 总结
- Bus Error (SIGBUS) 通常由硬件无法处理的非对齐内存访问引起。
- 性能陷阱:即使硬件或内核支持处理非对齐访问(如x86或内核模拟),跨缓存行访问(Split Access)也会导致显著的性能下降(原子性丧失、总线周期增加)。
- 最佳实践:始终遵守自然对齐规则,谨慎使用指针强转,善用
memcpy处理序列化数据,并关注编译器的对齐警告。
6. 参考文献
- Computer Systems: A Programmer’s Perspective (CSAPP), 3rd Edition
- Linux Kernel Source Code:
arch/mips/kernel/unaligned.c,arch/arm/mm/alignment.c - Intel® 64 and IA-32 Architectures Optimization Reference Manual

















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









