







调度器概述
进程是操作系统用来组织计算机中的任务,它从诞生就随着CPU时间执行,直到最终消失。计算机计算资源是有限的,但是进程却被赋予越来越多的任务,如何在进程间分配有限的计算资源,最终让用户获得最佳的使用体验,这是调度器需要解决的问题。
调度器是什么
调度程序即(scheduler)决定了多个程序运行策略,调度程序的最大原则在于能够最大限度的利用计算资源。内核中安排进程执行的模块称为调度器(scheduler)。
调度器(Scheduler)子系统是内核的核心子系统之一,负责系统内 CPU 资源的合理分配,需要能处理纷繁复杂的不同类型任务的调度需求,还需要能处理各种复杂的并发竞争环境,同时还需要兼顾整体吞吐性能和实时性要求(本身是一对矛盾体),其设计与实现都极具挑战。
线程调度器是一个操作系统服务,它负责为 Runnable 状态的线程分配 CPU 时间。一旦我们创建一个线程并启动它,它的执行便依赖于线程调度器的实现。同上一个问题,线程调度并不受到 Java 虚拟机控制,所以由应用程序来控制它是 更好的选择(也就是说不要让你的程序依赖于线程的优先级)。时间分片是指将可用的 CPU 时间分配给可用的 Runnable 线程的过程。分配 CPU 时间可以基于线程优先级或者线程等待的时间。
多任务系统可以划分为两类:非抢占式多任务(cooperative multitasking),抢占式多任务(preemptive mulittasking)。
调度器是CPU时间的管理员。Linux调度器需要负责做两件事:一件事是选择某些就绪的进程来执行;另一件事是打断某些执行中的进程,让它们变回就绪状态。不过,并不是所有的调度器都有第二个功能。有的调度器的状态切换是单向的,只能让就绪进程变成执行状态,不能把正在执行中的进程变回就绪状态。支持双向状态切换的调度器被称为抢占式(pre-emptive)调度器。
Linux2.6.34内核中调度器的设计是模块化的,这样做的好处是允许不同可以有针对性的选择不同调度算法,其中最基本的调度算法为基于分时(time sharing)的技术。
调度器作用及分类
调度器是一个操作系统的核心部分。可以比作是CPU时间的管理员。调度器主要负责选择某些就绪的进程来执行。不同的调度器根据不同的方法挑选出最适合运行的进程。目前Linux支持的调度器就有RT scheduler、Deadline scheduler、CFS scheduler及Idle scheduler等,其数据结构分别对应rt_sched_class 、dl_sched_class 、fair_sched_class 、idle_sched_class。
调度类
内核将调度策略进行了高度的抽象,形成调度类(sched_class)。通过调度类可以将调度器的公共代码(机制)和具体不同调度类提供的调度策略进行充分解耦,是典型的 OO(面向对象)的思想。通过这样的设计,可以让内核调度器极具扩展性,开发者通过很少的代码(基本不需改动公共代码)就可以增加一个新的调度类,从而实现一种全新的调度器(类),比如,deadline调度类就是3.x中新增的,从代码层面看只是增加了 dl_sched_class 这个结构体的相关实现函数,就很方便的添加了一个新的实时调度类型。
目前的5.4内核,有5种调度类,优先级从高到底分布如下:
stop_sched_class > dl_sched_class > rt_sched_class > fair_sched_class > idle_sched_class。
stop_sched_class:
优先级最高的调度类,它与 idle_sched_class 一样,是一个专用的调度类型(除了 migration 线程之外,其他的 task 都是不能或者说不应该被设置为 stop 调度类)。该调度类专用于实现类似 active balance 或 stop machine 等依赖于 migration 线程执行的“紧急”任务。
dl_sched_class:
deadline 调度类的优先级仅次于 stop 调度类,它是一种基于 EDL 算法实现的实时调度器(或者说调度策略)。
rt_sched_class:
rt 调度类的优先级要低于 dl 调度类,是一种基于优先级实现的实时调度器。
fair_sched_class:
CFS 调度器的优先级要低于上面的三个调度类,它是基于公平调度思想而设计的调度类型,是 Linux 内核的默认调度类。
idle_sched_class:
idle 调度类型是 swapper 线程,主要是让 swapper 线程接管 CPU,通过 cpuidle/nohz 等框架让 CPU 进入节能状态。
架构
调度策略是模块化设计的,调度器根据不同的进程依次遍历不同的调度策略,找到进程对应的调度策略,调度的结果即为选出一个可运行的进程指针,并将其加入到进程可运行队列中。
要说Linux2.4和2.6最大的差异就在于CFS调度器的引入。CFS是 Completely Fair Scheduler 的缩写。不过讲真话,个人并不完全认同“完全公平”调度是这个算法的本意,如何裁决资源抢占(preempt,字面上是优先权)才是这个调度器的本意。
CFS完全公平调度: CFS的出发点基于一个简单的理念:即所有进程实际占用处理器CPU的时间应为一致,目的是确保每个进程公平的处理器使用比,即最大的利用了计算资源。
FIFO先入先出队列:不基于时间片调度,处于可运行状态的SCHED_FIFO级别的进程比SCHED_NORMAL有更高优先级得到调度,一旦SCHED_FIFO级别的进程处于可执行的状态,它就会一致运行,直到进程阻塞或者主动释放。
RR(Round-Robin):SCHED_RR级别的进程在耗尽事先分配的时间片之后不会继续执行。即可以将RR调度理解为带有时间片的SCHED_FIFO。
FIFO和RR调度算法都为静态优先级。内核不是实时进程计算动态优先级,保证了优先级别高的实时进程总能抢占优先级比它低的进程。
进程与调度器
内核中安排进程执行的模块称为调度器(scheduler),而对线程的调度管理主要指的是为处于运行状态的线程分配 CPU 时间。
进程与线程
”进程是资源分配的最小单位,线程是CPU调度的最小单位“这样的回答太抽象,不太容易让人理解。下面引用一张图片加以类比说明:

一般,线程是实际执行任务的单位,所以在Linux中,也被成为任务task。
初步理解各种ID。基本上按照重要程度从高到低,在分割线下方的IDs不太重要。
pid: 进程ID。
lwp: 线程ID。在用户态的命令(比如ps)中常用的显示方式。
tid: 线程ID,等于lwp。tid在系统提供的接口函数中更常用,比如syscall(SYS_gettid)和syscall(__NR_gettid)。
tgid: 线程组ID,也就是线程组leader的进程ID,等于pid。
------分割线------
pgid: 进程组ID,也就是进程组leader的进程ID。
pthread id: pthread库提供的ID,生效范围不在系统级别,可以忽略。
sid: session ID for the session leader。
tpgid: tty process group ID for the process group leader。
从上面的列表看出,各种ID最后都归结到pid和lwp(tid)上。所以理解各种ID,最终归结为理解pid和lwp(tid)的联系和区别。
下面的图是一张描述父子进程,线程之间关系的图。
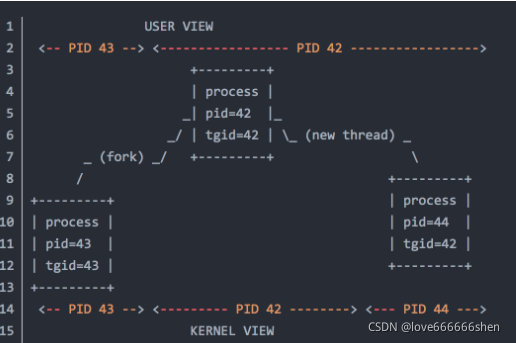
上图很好地描述了用户视角(user view)和内核视角(kernel view)看到线程的差别:
从用户视角出发,在pid 42中产生的tid 44线程,属于tgid(线程组leader的进程ID) 42。甚至用ps和top的默认参数,你都无法看到tid 44线程。
从内核视角出发,tid 42和tid 44是独立的调度单元,可以把他们视为"pid 42"和"pid 44"。
需要指出的是,有时候在Linux中进程和线程的区分也是不是十分严格的。即使线程和进程混用,pid和tid混用,根据上下文,还是可以清楚地区分对方想要表达的意思。上图中,从内核视角出发看到了pid 44,是从调度单元的角度出发,但是在top或ps命令中,你是绝对找不到一个pid为44的进程的,只能看到一个lwp(tid)为44的线程。
进程与线程之间的关系汇总:
进程是资源分配的基本单位,线程是调度的基本单位。
进程是资源的集合,这些资源包括内存地址空间,文件描述符等等,一个进程中的多个线程共享这些资源。
CPU对任务进行调度时,可调度的基本单位 (dispatchable entity)是线程。如果一个进程中没有其他线程,可以理解成这个进程中只有一个主线程,这个主进程独享进程中的所有资源。
进程的个体间是完全独立的,而线程间是彼此依存,并且共享资源。多进程环境中,任何一个进程的终止,不会影响到其他非子进程。而多线程环境中,父线程终止,全部子线程被迫终止(没有了资源)。
进程的状态
调度器可以切换进程状态(process state)。一个Linux进程从被创建到死亡,可能会经过很多种状态,比如执行、暂停、可中断睡眠、不可中断睡眠、退出等。我们可以把Linux下繁多的进程状态,归纳为三种基本状态。
就绪(Ready): 进程已经获得除了CPU以外的所有必要资源,如进程空间、网络连接等。就绪状态下的进程等得到CPU时间片,便可立即执行。
执行(Running):进程获得CPU,执行程序。
阻塞(Blocked):当进程由于等待某个事件而无法执行时,便放弃CPU,处于阻塞状态。
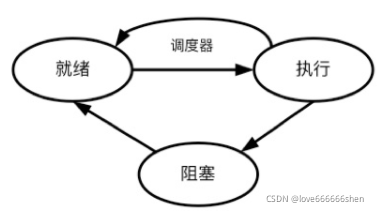
进程创建后,就自动变成了就绪状态。如果内核把CPU时间分配给该进程,那么进程就从就绪状态变成了执行状态。在执行状态下,进程执行指令,最为活跃。正在执行的进程可以主动进入阻塞状态,比如这个进程需要将一部分硬盘中的数据读取到内存中。在这段读取时间里,进程不需要使用CPU,可以主动进入阻塞状态,让出CPU。当读取结束时,计算机硬件发出信号,进程再从阻塞状态恢复为就绪状态。进程也可以被迫进入阻塞状态,比如接收到SIGSTOP信号。
进程的优先级
调度器分配CPU时间的基本依据,就是进程的优先级。根据程序任务性质的不同,程序可以有不同的执行优先级。根据优先级特点,我们可以把进程分为两种类别。
实时进程(Real-Time Process):优先级高、需要尽快被执行的进程。它们一定不能被普通进程所阻挡,例如视频播放、各种监测系统。
普通进程(Normal Process):优先级低、更长执行时间的进程。例如文本编译器、批处理一段文档、图形渲染。
普通进程根据行为的不同,还可以被分成互动进程(interactive process)和批处理进程(batch process)。互动进程的例子有图形界面,它们可能处在长时间的等待状态,例如等待用户的输入。一旦特定事件发生,互动进程需要尽快被激活。一般来说,图形界面的反应时间是50到100毫秒。批处理进程没有与用户交互的,往往在后台被默默地执行。
实时进程由Linux操作系统创造,普通用户只能创建普通进程。两种进程的优先级不同,实时进程的优先级永远高于普通进程。进程的优先级是一个0到139的整数。数字越小,优先级越高。其中,优先级0到99留给实时进程,100到139留给普通进程。
Linux任务调度过程
在Linux中,每一个CPU都会有一个队列来存储处于TASK_RUNNING状态的任务,任务调度就是从这些队列中取出优先级最高的任务作为下一个放入CPU执行的任务。
任务的调度需要进过两个过程:上下文切换和选择算法
调度器在让一个进程变回就绪时,就会立即让另一个就绪的进程开始执行。多个进程接替使用CPU,从而最大效率地利用CPU时间。当然,如果执行中进程主动进入阻塞状态,那么调度器也会选择另一个就绪进程来消费CPU时间。所谓的上下文切换(context switch)就是指进程在CPU中切换执行的过程。内核承担了上下文切换的任务,负责储存和重建进程被切换掉之前的CPU状态,从而让进程感觉不到自己的执行被中断。应用程序的开发者在编写计算机程序时,就不用专门写代码处理上下文切换了。
Linux 调度器进程分类
进程调度是操作系统的核心功能。调度器只是调度过程中的一部分,进程调度是非常复杂的过程,需要多个系统协同工作完成。它的主要工作是在所有RUNNING 进程中选择最合适的一个。
Linux 调度器将进程分为三类:
交互式进程
此类进程有大量的人机交互,因此进程不断地处于睡眠状态,等待用户输入。典型的应用比如编辑器 vi。此类进程对系统响应时间要求比较高,否则用户会感觉系统反应迟缓。
批处理进程
此类进程不需要人机交互,在后台运行,需要占用大量的系统资源。但是能够忍受响应延迟。比如编译器。
实时进程
实时对调度延迟的要求最高,这些进程往往执行非常重要的操作,要求立即响应并执行。比如视频播放软件或飞机飞行控制系统,很明显这类程序不能容忍长时间的调度延迟,轻则影响电影放映效果,重则机毁人亡。
调度时机
调度什么时候发生?即:schedule()函数什么时候被调用?
调度的发生主要有两种方式:
1:主动式调度(自愿调度)
在内核中主动直接调用进程调度函数schedule(),当进程需要等待资源而暂时停止运行时,会把状态置于挂起(睡眠),并主动请求调度,让出cpu。
2:被动式调度(抢占式调度、强制调度)
用户抢占(2.4 2.6)
内核抢占(2.6)
(1)用户抢占发生在:从系统调用返回用户空间;从中断处理程序返回用户空间。
内核即将返回用户空间的时候,如果need_resched标志被设置,会导致schedule()被调用,此时就会发生用户抢占。主动式调度是用户程序自己调度schedule,也许有人会觉得自己的代码中能引用schedule吗?也许不行吧,但大家知道wait4我们是可以调用的,前面我们没有给出wait4的代码,但我们知道在执行了wait4效果是父进程被挂起,所谓的挂起就是不运行了,放弃了CPU,这里发生了进程调度是显而易见的,其实在代码中有如下几行:
current>state = TASK_INTERRUPIBLE;schedule();
还有exit也有
current>state = TASK_ZOMBIE; schedule();
(2)内核抢占
在不支持内核抢占的系统中,进程/线程一旦运行于内核空间,就可以一直执行,直到它主动放弃或时间片耗尽为止。
这样一些非常紧急的进程或线程将长时间得不到运行。
在支持内核抢占的系统中,更高优先级的进程/线程可以抢占正在内核空间运行的低优先级的进程/线程。
关于抢占式调度(强制调度),需要知道的是,CPU在执行了当前指令之后,在执行下一条指令之前,CPU要判断在当前指令执行之后是否发生了中断或异常,如果发生了,CPU将比较到来的中断优先级和当前进程的优先级(有硬件参与实现,如中断控制器8259A芯片;通过比较寄存器的值来判断优先级;中断服务程序的入口地址形成有硬件参与实现,等等,具体实现请见相关资料和书籍),如果新来任务的优先级更高,则执行中断服务程序,在返回中断时,将执行进程调度函数schedule。
在支持内核抢占的系统中,某些特例下是不允许内核被抢占的:
(a)内核正在运行中断处理程序,进程调度函数schedule()会对此作出判断,如果是在中断中调用,会打印出错误信息。
(b) 内核正在进行中断上下文的bottom half(中断的底半部)处理,硬件中断返回前会执行软中断,此时仍然处于中断上下文。
(c) 进程正持有spinlock自旋锁,writelock/readlock读写锁等,当持有这些锁时,不应该被抢占,否则由于抢占将导致其他cpu长时间不能获得锁而死锁。
(d) 内核正在执行调度程序scheduler
为了保证linux内核在以上情况下不会被抢占,抢占式内核使用了一个变量preempt_count,称为内核抢占计数。
这一变量被设置在进程的thread_info结构体中,每当内核要进入以上几种状态时,变量preempt_count就加1,指示内核不允许抢占,反之减1。
CFS原理
对于时分多任务操作系统来说,可以理解为调度器维护着一个任务池,确定某一时刻CPU到底应该执行哪个任务。简单粗暴一点的调度器往往就是一个round robin,也就是分配相同的时间间隔,大家简单轮流使用CPU。很显然,这种调度才是最公平的,但政治正确的“完全公平”无法满足复杂场景下的调度,于是就有了本文中的CFS调度模型。
至于调度,本质上是CPU对运行时间片(epoch)的管理,CFS模型主要的改进是:在round robin采用的真实运行时间片的基础上,加权出一个虚拟运行时间的概念vruntime。每个线程(这里理解为系统调度的最小单位,下同)都有一个vruntime值,而不同的权重即该线程的优先级,具体算法为:

这里的权重比是nice 0 的权重和线程权重的比值,nice 0即为系统默认的线程权限,该权重默认为1024。粗暴的理解为在默认条件下,vruntime就等于该线程的实际运行时间。具体来说可以在cgroup中的键值cpu.shares找到这个值,调整这个值可以改变vruntime的计算权重。而既然提到了cgroup,cgroup既然是嵌套的,这个值自然必须嵌套加权。
[root@localhost proc]# cat /sys/fs/cgroup/cpu/cpu.shares
1024
得到了这个vruntime之后,系统将会根据每个线程的vruntime排序(实际上是基于红黑树算法,这里不展开),vruntime最小的线程则会最早获得调度。而一旦vruntime的次序发生变化,系统将尝试触发下一次调度。也就是说调度器尽可能的保证所有线程的vruntime都一致,而权重高的线程vruntime提升的慢,容易被优先调度;权重低,同样的时间上vruntime上升的快,反而容易被轮空。一个进程的vruntime可以通过/proc//sched中的se.vruntime选项查看
ps -aux // 查看正在进行的进程,假设有一个PID为2152的进程正在运行,则可以通过如下命令查看当前进程的优先级
[root@localhost 1352]# grep vruntime /proc/1352/sched
se.vruntime : 1258213807.999425
这个时候,有个比较典型的例子就是当系统中存在大量vruntime相似的线程之后,类似多米诺效应,线程调度将会被过于频繁的触发,这明显不合理!于是就如何定义“vruntime触发调度”时,CFS引入了一个阈值,即如果前后两个线程vruntime保持在一个阈值之内,系统不会触发调度。而这个阈值大小就是最小的调度时间片。
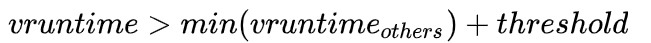
此外,CFS本质上是CPU运行时间导向的调度,这就有了另一个规则:对于sleep/IO这类的操作,由于相对来说并不占用过多资源,vruntime并不会被马上结算,仍会保持最初的vruntime。 跟到这里,你可能马上出现了一个头脑实验:一个线程A,初始值小但一直sleep,所以vruntime始终不增长;线程B,vruntime初始较大重始终排队等待,这种策略就变得不可理喻了。 所以系统在该线程被重新唤醒之后会重新计算vruntime,vruntime将取当期线程的vruntime和当前系统内最小vruntime-阈值这两个值中的最大值。也就是说如果当前系统中有两个及以上线程,当sleep/IO线程被唤醒之后,无论如何该线程将无法获得第一优先调度,最好的情况也要等当前最小vruntime接受调度之后再次触发调度。
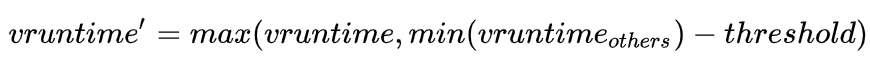
另外,在cgroup的目录下还有两个跟调度有关的设定:cpu.cfs_quota_us,cpu.cfs_period_us。 这两个值确定的该线程得到调度后CPU时间的占空比。cpu.cfs_period_us是得到调度的周期,而cpu.cfs_quota_us是在这个调度周期内绝对CPU时常,单位都是微秒(us)。
![[公式]](https://i-blog.csdnimg.cn/blog_migrate/8ce75f2ce8026afe21b77c8ff5be83c8.png)
总结一下,如果用上下文切换的方式评价调度器的差异性:
更多的线程分配到更少数量的CPU core上(不区分物理core和逻辑core),上下文切换的次数会增多。如果各个线程的优先级一致,足够多的线程分配最终的结果就是线程的切换频率等于vruntime阈值。
不同的优先级调度只在需要多线程切换时才有效,即便系统中只有一个优先级很低的线程,系统仍有可能达到full utilization(满负载)。
CPU share的方式采用了占空比来控制cpu的utilization,跟上下文切换次数无关。
参考
【原创】(五)Linux进程调度-CFS调度器
Linux CFS调度器
调度器简介,以及Linux的调度策略
linux进程调度
Linux任务调度机制
Linux 内核调度器源码分析 - 初始化
调度器 | Scheduler
线程和进程的区别
理解Linux的进程,线程,PID,LWP,TID,TGID


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











