







HDFS简介
全称 Hadoop Distributed File System, Hadoop分布式文件系统。 根据Google的GFS论文,由Doug Cutting使用JAVA开发的开源项目。HDFS是Hadoop项目的一部分。为Hadoop提供底层的数据存储,满足上次各种实际应用使用(如Map/Reduce)。HDFS是典型的的Master/Slave集群架构,由一个NameNode和多个DateNode组成,NameName只能有一个,扮演Master角色,负责对具体的存储块的元数据进行保存,比如控制某个存储块具体保存在哪个DataNode上;DataNode可以为多个,扮演着Slave的角色,负责对具体的存储块进行保存,一个相同的存储块根据配置可以保存到多个DataNode上,以保持数据的高可用性。
准备工作:
根据实际要求,规划环境,本文为实验环境,三台虚拟机
本次为三台机器(master:hadoop1 datanode:hadoop2 datanode:hadoop3 )
系统版本:CentOS release 6.6 (Final)
设置主机名;修改 hosts
[root@hadoop1 ~]# vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=hadoop1
[root@hadoop1 ~]# vim /etc/hosts
192.168.217.128 hadoop1 ###新增
192.168.217.129 hadoop2 ###新增
192.168.217.130 hadoop3 ###新增- 拷贝 hosts 文件到 hadoop2 hadoo3
[root@hadoop1 ~]# scp /etc/hosts root@hadoop2:/etc
[root@hadoop1 ~]# scp /etc/hosts root@hadoop3:/etc配置免密码登录:
- 在 hadoop1 节点配置免密码登录:
[root@hadoop1 ~]# ssh-keygen –t rsa
[root@hadoop1 ~]# cd .ssh
[root@hadoop1 .ssh]# cat id_rsa.pub > authorized_keys- 复制
hadoop1节点的/root/.ssh/ authorized_keys文件到hadoop2、hadoop3节点;
[root@hadoop1 .ssh]# scp authorized_keys root@hadoop2:/root/.ssh
[root@hadoop1 .ssh]# scp authorized_keys root@hadoop3:/root/.ssh至此免密码登录配置完毕,可以通过本机
ssh各个节点IP来测试是否需要密码登录
虚拟机上安装 jdk,配置环境变量
上一篇文章中有详细步骤,本文略
安装 hadoop
下载Hadoop软件包,官方下载地址
解压至/home/
tar zxvf hadoop-2.7.4.tar.gz -C /home/- 配置环境变量,新增
hadoop到环境变量
vim /etc/profile
export HADOOP_HOME=/home/hadoop-2.7.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin- 在
NameNode上修改hadoop配置文件
主要修改/home/hadoop-2.7.4/etc/hadoop/目录下的配置文件
Hadoop-env.sh: Hadoop环境变量设置
Core-site.xml: NameNode IP和端口设置
Hdfs-site.xml: HDFS数据块副本等参数设置
Mapred-site.xml: MapReduce
Yarn-site.xml reduce获取数据的方式
Slaves: 完成datanode节点IP设置[root@hadoop1 hadoop]# vim hadoop-env.sh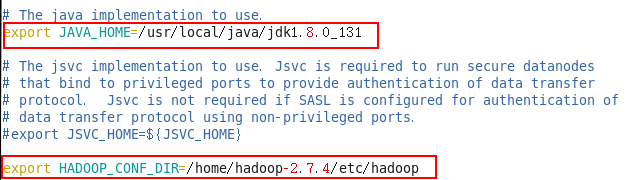

[root@hadoop1 hadoop]# vim core-site.xml 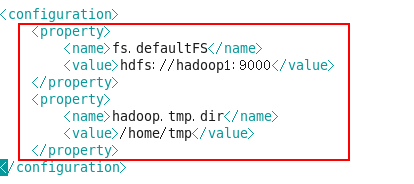
- 创建 tmp 目录
mkdir /home/tmp[root@hadoop1 hadoop]# vim hdfs-site.xml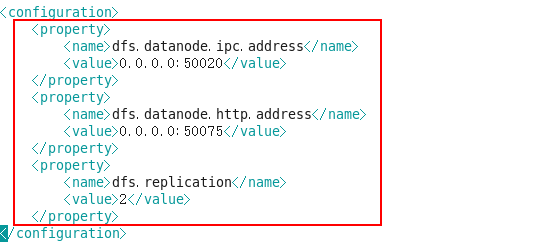
注:dfs.replication 表示数据副本数,一般不大于 datanode 节点数
[root@hadoop1 hadoop]# mv mapred-site.xml.template mapred-site.xml
[root@hadoop1 hadoop]# vim mapred-site.xml 
[root@hadoop1 hadoop]# vim yarn-site.xml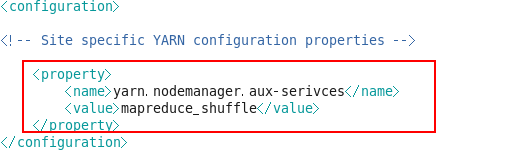
[root@hadoop1 hadoop]# vim slaves添加 hadoop2 hadoop3 做为 datanode
- 复制hadoop系统到所有DataNode节点
[root@hadoop1 ~]# scp –r /home/hadoop-2.7.4 root@hadoop2:/home/
[root@hadoop1 ~]# scp –r /home/hadoop-2.7.4 root@hadoop3:/home/启动 Hadoop
- 格式化NameNode
在hadoop1启动Hadoop集群,需要启动HDFS集群和Map/Reduce集群。格式化一个新的分布式文件系统:
[root@hadoop1 ~]# hadoop namenode -format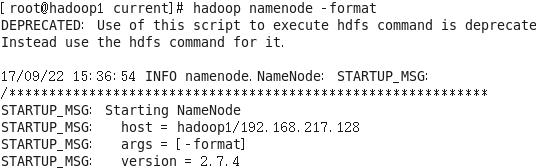
如果格式化成功,会返回一堆有关NameNode的启动信息,其中会有一句“…. has been successfully formatted.”
- 启动HDFS
[root@hadoop1 sbin]# sh /home/hadoop-2.7.4/sbin/start-dfs.sh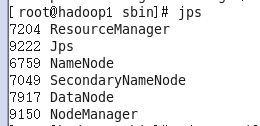
sbin/start-dfs.sh 脚本会参照 NameNode 上${HADOOP_CONF_DIR}/slaves 文件的内容,在所有列出的 slave 上启动DataNode 守护进程
查看集群状态
[root@hadoop1 ~]# hadoop dfsadmin -report端口开启
iptables -I INPUT -p tcp --dport 50070 -j ACCEPT
iptables -I INPUT -p tcp --dport 8088 -j ACCEPT浏览器方式:在WEB页面下查看Hadoop工作情况
输入部署Hadoop服务器的IP:http://IP:50070;http://IP:8088.
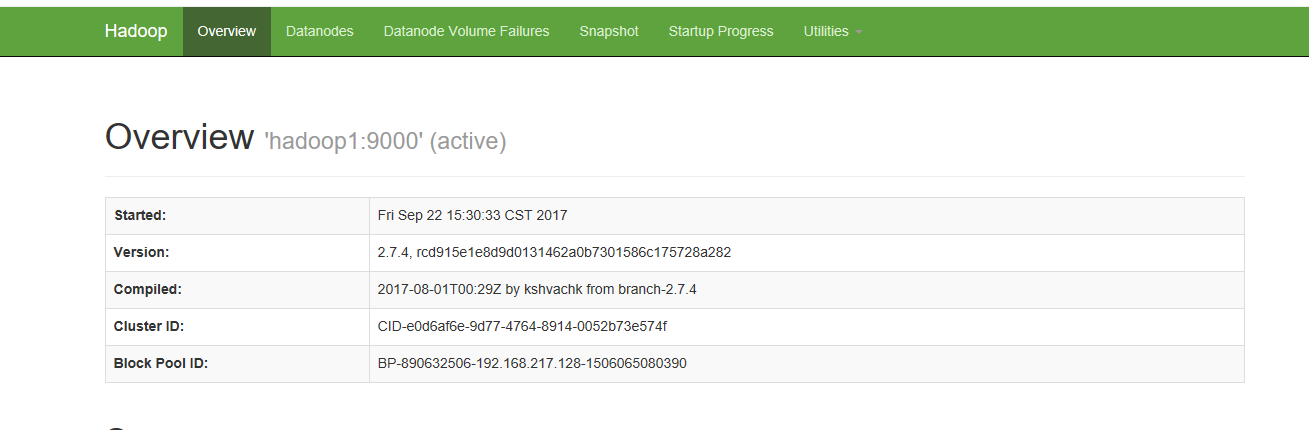
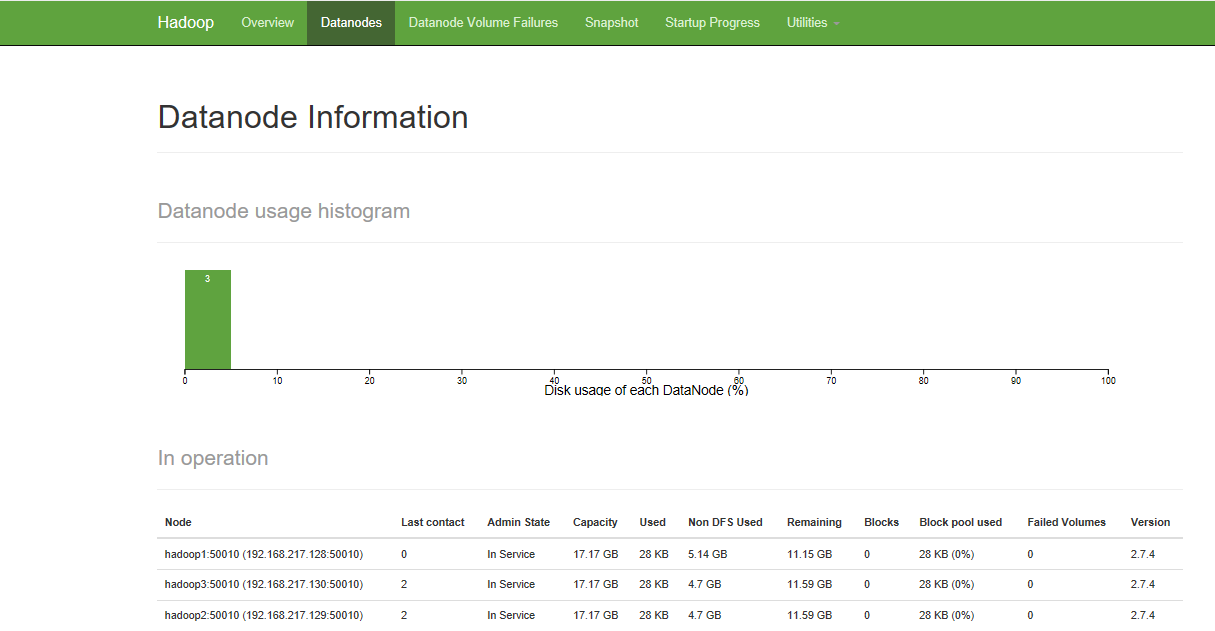
以上为搭建Hadoop集群过程。
附:
Hadoop中文文档:http://hadoop.apache.org/docs/r1.0.4/cn/index.html















 1890
1890











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









