






Hash Table Collision avoidance strategy
1、Collision resolution by chaining(closed addressing)
链表法是一种可行的避碰策略。Hash table 数组的每个插槽(slot)都存储一个单链表数组,用以存储所有具有相同hash值的key-value 对。新插入的key-value对会被添加到对应单链表的末尾。查找算法在相应的单链表中扫描查找对应的key值。初始时候,hash table中每个插槽都存储的时空指针,对于每个插槽的第一次插入操作的时候,会真正简历对应插槽所存储的单链表。
链表法示意图:
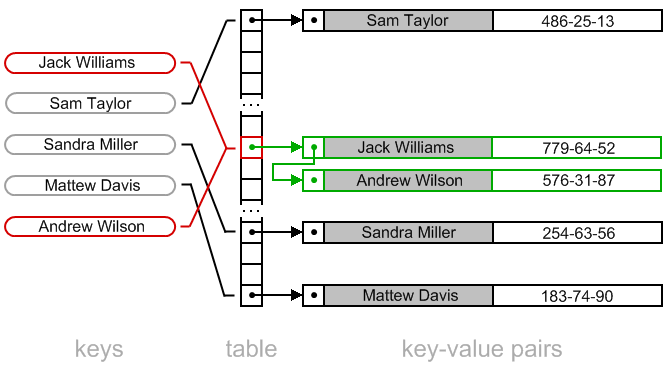
性能分析:
假设,hash函数值的分布是满足均匀分布的,同时Hash table允许动态调整大小,在hash table中执行插入,删除以及查找的操作复杂度的不变的,那么整个hash table的填充率(load factor)将最终决定这些操作所话费的时间。
值得注意的是,即使整个Hash Table的负载成都大幅的超出table本身的负载能力,通过链表法来进行避碰的Hash table依然具有很好的性能。假设一个具有1000各插槽的Hash Table存储了100000个条目(load factor:1000000/1000 = 100)。与直接讲所有数据用单链表(singly-linked list)进行存储来这样必然会花费更多的的存储空间(requires more memory),但是这样存储数据会是的数据的具体插入、查找等操作的时间提高了1000倍(平均来看)。但是,你需要知道,单从计算上来看,单链表存储数据与固定大小的hash table存储数据的时间复杂度都是O(n)。
2.Open addressing strategy
链表法是一个避免碰撞的很好的解决策略,但是链表法需要花费额外的存储空间在链表上。如果我们存储的数据项很小(例如整形变量)或者数据量本身就很小,那么使用链表法进行避碰的空间浪费几乎等同于数据本身存储所占用的空间。当采用开放寻址策略进行避碰时,所有的key-value对都会被存储在Hash Table的本身的存储空间中,我们也就不需要额外的定义数据结构。
碰撞避免:
我们来考虑插入操作,给定一个key,如果这个key对应hash slot已经被占用,我们就必须要寻找到一个空的位置来存储对应的key值及其数据。一般情形是从key值本来应该被存放的插槽位置开始向后不断的试探寻找(proceeds in a probe sequence),直到找到一个空位置可以用来存储相应的key-value为止。以下时几种常见的试探方式:
Linear probing(线性试探),在两个试探位置之间的距离是固定的。
Quadratic probing (二次试探),在两个试探位置之间的距离每次增加一个固定的长度,在这种情况下数据真正被存储的位置与本应该存储的位置之间的距离是由试探执行的次数决定的。
Double hashing(二次Hash):时机存储位置与本应该存储位置的距离通过另外一个单独的距离hash函数计算得出。
开放寻址避碰策略对于Hash 函数本身也有额外的要求,除了要求Hash值分布满足均匀分布外,也同样要求hash 值不会因为试探的位置而导致其过于集中。
线性试探示意:
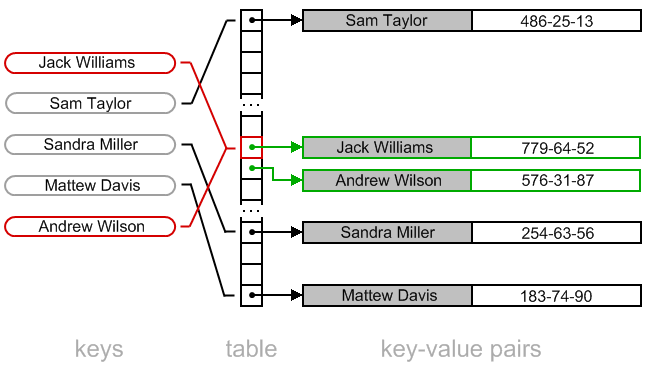
删除操作:
还有一些细节我们需要考虑,当在开放寻址策略的Hash table中删除一个key时,考虑下图所示情况:
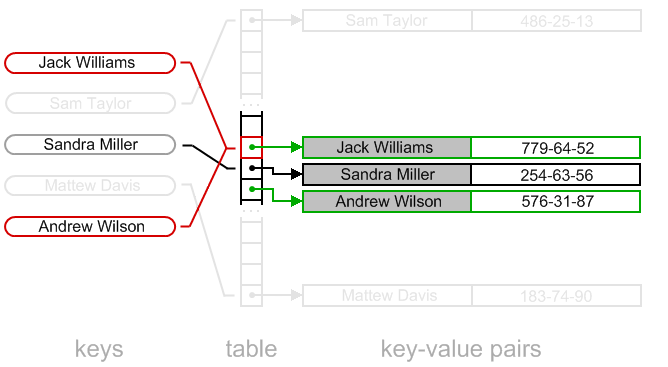
如果算法实现过程中直接删除了“Sandra Miler”对应的存储位置数据,那么整个Hash table的结构就会被毁掉,算法在查找“Andrew Wilson”的时候将不会成功返回对应的值,但是实际上“Andrew Wilson”在Hash Table中是确实存在的。
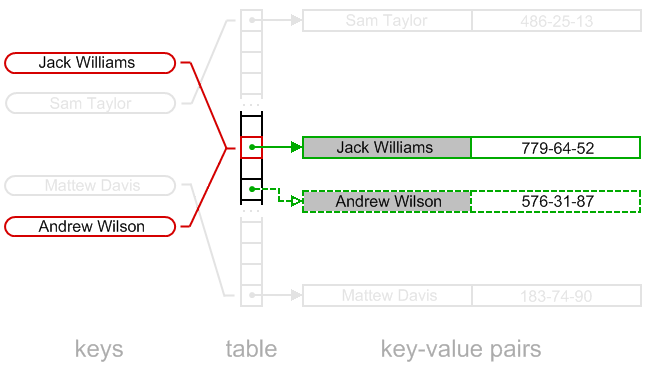
我们可以使用以下策略来实现删除操作,与其直接清空对应Bucket的数据,我们在对应的Bucket上写入“Deleted”标记
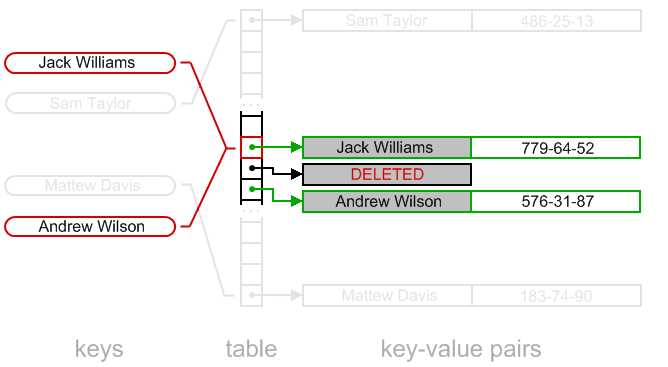
这样查找算法将会正常执行,我们只需要在插入算法中处理DELETEED的情况。
需要注意的是,这种解决问题的方式(添加DELETED)将会导致HASH table对DELETED作为键值出现时出现无效的情况,因此在一个允许进行删除操作的HASH table中避碰策略最好还是使用链表法。
性能分析:
采用开放寻址法的Hash table对与Hash 函数的选择要求更高,假设,hash函数值的分布是满足均匀分布的,同时Hash table允许动态调整大小,在hash table中执行插入,删除以及查找的操作复杂度的不变的。
开放血脂策略的Hash Table受到load factor的影响也喊打。如果load factor超过了0.7的阈值,整个Hash table的操作速度会急速下降。试探序列的长度(实际存储位置与目标存储位置距离)的比值是(loadFactor)/(1 - loadFactor)。在最极端的情况下,当loadFactor的值是1的时候,试探序列长度是无穷,在实际过程中这就意味着我们需要更多的空间来存储新增的key,因此开放寻址方法的Hash table需要支持动态扩容,以保证其性能。
Open addressing 与chaining对比:
|
| Chaining | Open addressing |
| Collision resolution | Using external data structure | Using hash table itself |
| Memory waste | Pointer size overhead per entry (storing list heads in the table) | No overhead 1 |
| Performance dependence on table's load factor | Directly proportional | Proportional to (loadFactor) / (1 - loadFactor) |
| Allow to store more items, than hash table size | Yes | No. Moreover, it's recommended to keep table's load factor below 0.7 |
| Hash function requirements | Uniform distribution | Uniform distribution, should avoid clustering |
| Handle removals | Removals are ok | Removals clog the hash table with "DELETED" entries |
| Implementation | Simple | Correct implementation of open addressing based hash table is quite tricky |
Reference:
http://www.algolist.net/Data_structures/Hash_table/Open_addressing
http://www.algolist.net/Data_structures/Hash_table/Chaining
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









