






代码输出结果
function runAsync (x) {
const p = new Promise(r => setTimeout(() => r(x, console.log(x)), 1000))
return p
}
Promise.race([runAsync(1), runAsync(2), runAsync(3)])
.then(res => console.log('result: ', res))
.catch(err => console.log(err))
输出结果如下:
1
'result: ' 1
2
3
then只会捕获第一个成功的方法,其他的函数虽然还会继续执行,但是不是被then捕获了。
new 一个函数发生了什么
构造调用:
- 创造一个全新的对象
- 这个对象会被执行 [[Prototype]] 连接,将这个新对象的 [[Prototype]] 链接到这个构造函数.prototype 所指向的对象
- 这个新对象会绑定到函数调用的 this
- 如果函数没有返回其他对象,那么 new 表达式中的函数调用会自动返回这个新对象
代码输出问题
function fun(n, o) {
console.log(o)
return {
fun: function(m){
return fun(m, n);
}
};
}
var a = fun(0); a.fun(1); a.fun(2); a.fun(3);
var b = fun(0).fun(1).fun(2).fun(3);
var c = fun(0).fun(1); c.fun(2); c.fun(3);
输出结果:
undefined 0 0 0
undefined 0 1 2
undefined 0 1 1
这是一道关于闭包的题目,对于fun方法,调用之后返回的是一个对象。我们知道,当调用函数的时候传入的实参比函数声明时指定的形参个数要少,剩下的形参都将设置为undefined值。所以 console.log(o); 会输出undefined。而a就是是fun(0)返回的那个对象。也就是说,函数fun中参数 n 的值是0,而返回的那个对象中,需要一个参数n,而这个对象的作用域中没有n,它就继续沿着作用域向上一级的作用域中寻找n,最后在函数fun中找到了n,n的值是0。了解了这一点,其他运算就很简单了,以此类推。
有哪些可能引起前端安全的问题?
- 跨站脚本 (Cross-Site Scripting, XSS): ⼀种代码注⼊⽅式, 为了与 CSS 区分所以被称作 XSS。早期常⻅于⽹络论坛, 起因是⽹站没有对⽤户的输⼊进⾏严格的限制, 使得攻击者可以将脚本上传到帖⼦让其他⼈浏览到有恶意脚本的⻚⾯, 其注⼊⽅式很简单包括但不限于 JavaScript / CSS / Flash 等;
- iframe的滥⽤: iframe中的内容是由第三⽅来提供的,默认情况下他们不受控制,他们可以在iframe中运⾏JavaScirpt脚本、Flash插件、弹出对话框等等,这可能会破坏前端⽤户体验;
- 跨站点请求伪造(Cross-Site Request Forgeries,CSRF): 指攻击者通过设置好的陷阱,强制对已完成认证的⽤户进⾏⾮预期的个⼈信息或设定信息等某些状态更新,属于被动攻击
- 恶意第三⽅库: ⽆论是后端服务器应⽤还是前端应⽤开发,绝⼤多数时候都是在借助开发框架和各种类库进⾏快速开发,⼀旦第三⽅库被植⼊恶意代码很容易引起安全问题。
参考:前端进阶面试题详细解答
代码输出结果
Promise.resolve('1')
.then(res => {
console.log(res)
})
.finally(() => {
console.log('finally')
})
Promise.resolve('2')
.finally(() => {
console.log('finally2')
return '我是finally2返回的值'
})
.then(res => {
console.log('finally2后面的then函数', res)
})
输出结果如下:
1
finally2
finally
finally2后面的then函数 2
.finally()一般用的很少,只要记住以下几点就可以了:
.finally()方法不管Promise对象最后的状态如何都会执行.finally()方法的回调函数不接受任何的参数,也就是说你在.finally()函数中是无法知道Promise最终的状态是resolved还是rejected的- 它最终返回的默认会是一个上一次的Promise对象值,不过如果抛出的是一个异常则返回异常的Promise对象。
- finally本质上是then方法的特例
.finally()的错误捕获:
Promise.resolve('1')
.finally(() => {
console.log('finally1')
throw new Error('我是finally中抛出的异常')
})
.then(res => {
console.log('finally后面的then函数', res)
})
.catch(err => {
console.log('捕获错误', err)
})
输出结果为:
'finally1'
'捕获错误' Error: 我是finally中抛出的异常
常见的浏览器内核比较
- Trident: 这种浏览器内核是 IE 浏览器用的内核,因为在早期 IE 占有大量的市场份额,所以这种内核比较流行,以前有很多网页也是根据这个内核的标准来编写的,但是实际上这个内核对真正的网页标准支持不是很好。但是由于 IE 的高市场占有率,微软也很长时间没有更新 Trident 内核,就导致了 Trident 内核和 W3C 标准脱节。还有就是 Trident 内核的大量 Bug 等安全问题没有得到解决,加上一些专家学者公开自己认为 IE 浏览器不安全的观点,使很多用户开始转向其他浏览器。
- Gecko: 这是 Firefox 和 Flock 所采用的内核,这个内核的优点就是功能强大、丰富,可以支持很多复杂网页效果和浏览器扩展接口,但是代价是也显而易见就是要消耗很多的资源,比如内存。
- Presto: Opera 曾经采用的就是 Presto 内核,Presto 内核被称为公认的浏览网页速度最快的内核,这得益于它在开发时的天生优势,在处理 JS 脚本等脚本语言时,会比其他的内核快3倍左右,缺点就是为了达到很快的速度而丢掉了一部分网页兼容性。
- Webkit: Webkit 是 Safari 采用的内核,它的优点就是网页浏览速度较快,虽然不及 Presto 但是也胜于 Gecko 和 Trident,缺点是对于网页代码的容错性不高,也就是说对网页代码的兼容性较低,会使一些编写不标准的网页无法正确显示。WebKit 前身是 KDE 小组的 KHTML 引擎,可以说 WebKit 是 KHTML 的一个开源的分支。
- Blink: 谷歌在 Chromium Blog 上发表博客,称将与苹果的开源浏览器核心 Webkit 分道扬镳,在 Chromium 项目中研发 Blink 渲染引擎(即浏览器核心),内置于 Chrome 浏览器之中。其实 Blink 引擎就是 Webkit 的一个分支,就像 webkit 是KHTML 的分支一样。Blink 引擎现在是谷歌公司与 Opera Software 共同研发,上面提到过的,Opera 弃用了自己的 Presto 内核,加入 Google 阵营,跟随谷歌一起研发 Blink。
代码输出结果
async function async1() {
console.log("async1 start");
await async2();
console.log("async1 end");
setTimeout(() => {
console.log('timer1')
}, 0)
}
async function async2() {
setTimeout(() => {
console.log('timer2')
}, 0)
console.log("async2");
}
async1();
setTimeout(() => {
console.log('timer3')
}, 0)
console.log("start")
输出结果如下:
async1 start
async2
start
async1 end
timer2
timer3
timer1
代码的执行过程如下:
- 首先进入
async1,打印出async1 start; - 之后遇到
async2,进入async2,遇到定时器timer2,加入宏任务队列,之后打印async2; - 由于
async2阻塞了后面代码的执行,所以执行后面的定时器timer3,将其加入宏任务队列,之后打印start; - 然后执行async2后面的代码,打印出
async1 end,遇到定时器timer1,将其加入宏任务队列; - 最后,宏任务队列有三个任务,先后顺序为
timer2,timer3,timer1,没有微任务,所以直接所有的宏任务按照先进先出的原则执行。
浏览器本地存储方式及使用场景
(1)Cookie
Cookie是最早被提出来的本地存储方式,在此之前,服务端是无法判断网络中的两个请求是否是同一用户发起的,为解决这个问题,Cookie就出现了。Cookie的大小只有4kb,它是一种纯文本文件,每次发起HTTP请求都会携带Cookie。
Cookie的特性:
- Cookie一旦创建成功,名称就无法修改
- Cookie是无法跨域名的,也就是说a域名和b域名下的cookie是无法共享的,这也是由Cookie的隐私安全性决定的,这样就能够阻止非法获取其他网站的Cookie
- 每个域名下Cookie的数量不能超过20个,每个Cookie的大小不能超过4kb
- 有安全问题,如果Cookie被拦截了,那就可获得session的所有信息,即使加密也于事无补,无需知道cookie的意义,只要转发cookie就能达到目的
- Cookie在请求一个新的页面的时候都会被发送过去
如果需要域名之间跨域共享Cookie,有两种方法:
- 使用Nginx反向代理
- 在一个站点登陆之后,往其他网站写Cookie。服务端的Session存储到一个节点,Cookie存储sessionId
Cookie的使用场景:
- 最常见的使用场景就是Cookie和session结合使用,我们将sessionId存储到Cookie中,每次发请求都会携带这个sessionId,这样服务端就知道是谁发起的请求,从而响应相应的信息。
- 可以用来统计页面的点击次数
(2)LocalStorage
LocalStorage是HTML5新引入的特性,由于有的时候我们存储的信息较大,Cookie就不能满足我们的需求,这时候LocalStorage就派上用场了。
LocalStorage的优点:
- 在大小方面,LocalStorage的大小一般为5MB,可以储存更多的信息
- LocalStorage是持久储存,并不会随着页面的关闭而消失,除非主动清理,不然会永久存在
- 仅储存在本地,不像Cookie那样每次HTTP请求都会被携带
LocalStorage的缺点:
- 存在浏览器兼容问题,IE8以下版本的浏览器不支持
- 如果浏览器设置为隐私模式,那我们将无法读取到LocalStorage
- LocalStorage受到同源策略的限制,即端口、协议、主机地址有任何一个不相同,都不会访问
LocalStorage的常用API:
// 保存数据到 localStorage
localStorage.setItem('key', 'value');
// 从 localStorage 获取数据
let data = localStorage.getItem('key');
// 从 localStorage 删除保存的数据
localStorage.removeItem('key');
// 从 localStorage 删除所有保存的数据
localStorage.clear();
// 获取某个索引的Key
localStorage.key(index)
LocalStorage的使用场景:
- 有些网站有换肤的功能,这时候就可以将换肤的信息存储在本地的LocalStorage中,当需要换肤的时候,直接操作LocalStorage即可
- 在网站中的用户浏览信息也会存储在LocalStorage中,还有网站的一些不常变动的个人信息等也可以存储在本地的LocalStorage中
(3)SessionStorage
SessionStorage和LocalStorage都是在HTML5才提出来的存储方案,SessionStorage 主要用于临时保存同一窗口(或标签页)的数据,刷新页面时不会删除,关闭窗口或标签页之后将会删除这些数据。
SessionStorage与LocalStorage对比:
- SessionStorage和LocalStorage都在本地进行数据存储;
- SessionStorage也有同源策略的限制,但是SessionStorage有一条更加严格的限制,SessionStorage只有在同一浏览器的同一窗口下才能够共享;
- LocalStorage和SessionStorage都不能被爬虫爬取;
SessionStorage的常用API:
// 保存数据到 sessionStorage
sessionStorage.setItem('key', 'value');
// 从 sessionStorage 获取数据
let data = sessionStorage.getItem('key');
// 从 sessionStorage 删除保存的数据
sessionStorage.removeItem('key');
// 从 sessionStorage 删除所有保存的数据
sessionStorage.clear();
// 获取某个索引的Key
sessionStorage.key(index)
SessionStorage的使用场景
- 由于SessionStorage具有时效性,所以可以用来存储一些网站的游客登录的信息,还有临时的浏览记录的信息。当关闭网站之后,这些信息也就随之消除了。
介绍下 promise 的特性、优缺点,内部是如何实现的,动手实现 Promise
1)Promise基本特性
- 1、Promise有三种状态:pending(进行中)、fulfilled(已成功)、rejected(已失败)
- 2、Promise对象接受一个回调函数作为参数, 该回调函数接受两个参数,分别是成功时的回调resolve和失败时的回调reject;另外resolve的参数除了正常值以外, 还可能是一个Promise对象的实例;reject的参数通常是一个Error对象的实例。
- 3、then方法返回一个新的Promise实例,并接收两个参数onResolved(fulfilled状态的回调);onRejected(rejected状态的回调,该参数可选)
- 4、catch方法返回一个新的Promise实例
- 5、finally方法不管Promise状态如何都会执行,该方法的回调函数不接受任何参数
- 6、Promise.all()方法将多个多个Promise实例,包装成一个新的Promise实例,该方法接受一个由Promise对象组成的数组作为参数(Promise.all()方法的参数可以不是数组,但必须具有Iterator接口,且返回的每个成员都是Promise实例),注意参数中只要有一个实例触发catch方法,都会触发Promise.all()方法返回的新的实例的catch方法,如果参数中的某个实例本身调用了catch方法,将不会触发Promise.all()方法返回的新实例的catch方法
- 7、Promise.race()方法的参数与Promise.all方法一样,参数中的实例只要有一个率先改变状态就会将该实例的状态传给Promise.race()方法,并将返回值作为Promise.race()方法产生的Promise实例的返回值
- 8、Promise.resolve()将现有对象转为Promise对象,如果该方法的参数为一个Promise对象,Promise.resolve()将不做任何处理;如果参数thenable对象(即具有then方法),Promise.resolve()将该对象转为Promise对象并立即执行then方法;如果参数是一个原始值,或者是一个不具有then方法的对象,则Promise.resolve方法返回一个新的Promise对象,状态为fulfilled,其参数将会作为then方法中onResolved回调函数的参数,如果Promise.resolve方法不带参数,会直接返回一个fulfilled状态的 Promise 对象。需要注意的是,立即resolve()的 Promise 对象,是在本轮“事件循环”(event loop)的结束时执行,而不是在下一轮“事件循环”的开始时。
- 9、Promise.reject()同样返回一个新的Promise对象,状态为rejected,无论传入任何参数都将作为reject()的参数
2)Promise优点
- ①统一异步 API
- Promise 的一个重要优点是它将逐渐被用作浏览器的异步 API ,统一现在各种各样的 API ,以及不兼容的模式和手法。
- ②Promise 与事件对比
- 和事件相比较, Promise 更适合处理一次性的结果。在结果计算出来之前或之后注册回调函数都是可以的,都可以拿到正确的值。 Promise 的这个优点很自然。但是,不能使用 Promise 处理多次触发的事件。链式处理是 Promise 的又一优点,但是事件却不能这样链式处理。
- ③Promise 与回调对比
- 解决了回调地狱的问题,将异步操作以同步操作的流程表达出来。
- ④Promise 带来的额外好处是包含了更好的错误处理方式(包含了异常处理),并且写起来很轻松(因为可以重用一些同步的工具,比如 Array.prototype.map() )。
3)Promise缺点
- 1、无法取消Promise,一旦新建它就会立即执行,无法中途取消。
- 2、如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。
- 3、当处于Pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。
- 4、Promise 真正执行回调的时候,定义 Promise 那部分实际上已经走完了,所以 Promise 的报错堆栈上下文不太友好。
4)简单代码实现
最简单的Promise实现有7个主要属性, state(状态), value(成功返回值), reason(错误信息), resolve方法, reject方法, then方法
class Promise{
constructor(executor) {
this.state = 'pending';
this.value = undefined;
this.reason = undefined;
let resolve = value => {
if (this.state === 'pending') {
this.state = 'fulfilled';
this.value = value;
}
};
let reject = reason => {
if (this.state === 'pending') {
this.state = 'rejected';
this.reason = reason;
}
};
try {
// 立即执行函数
executor(resolve, reject);
} catch (err) {
reject(err);
}
}
then(onFulfilled, onRejected) {
if (this.state === 'fulfilled') {
let x = onFulfilled(this.value);
};
if (this.state === 'rejected') {
let x = onRejected(this.reason);
};
}
}
5)面试够用版
function myPromise(constructor){ let self=this;
self.status="pending" //定义状态改变前的初始状态
self.value=undefined;//定义状态为resolved的时候的状态
self.reason=undefined;//定义状态为rejected的时候的状态
function resolve(value){
//两个==="pending",保证了了状态的改变是不不可逆的
if(self.status==="pending"){
self.value=value;
self.status="resolved";
}
}
function reject(reason){
//两个==="pending",保证了了状态的改变是不不可逆的
if(self.status==="pending"){
self.reason=reason;
self.status="rejected";
}
}
//捕获构造异常
try{
constructor(resolve,reject);
}catch(e){
reject(e);
}
}
myPromise.prototype.then=function(onFullfilled,onRejected){
let self=this;
switch(self.status){
case "resolved": onFullfilled(self.value); break;
case "rejected": onRejected(self.reason); break;
default:
}
}
// 测试
var p=new myPromise(function(resolve,reject){resolve(1)});
p.then(function(x){console.log(x)})
//输出1
6)大厂专供版
const PENDING = "pending";
const FULFILLED = "fulfilled";
const REJECTED = "rejected";
const resolvePromise = (promise, x, resolve, reject) => {
if (x === promise) {
// If promise and x refer to the same object, reject promise with a TypeError as the reason.
reject(new TypeError('循环引用'))
}
// if x is an object or function,
if (x !== null && typeof x === 'object' || typeof x === 'function') {
// If both resolvePromise and rejectPromise are called, or multiple calls to the same argument are made, the first call takes precedence, and any further calls are ignored.
let called
try { // If retrieving the property x.then results in a thrown exception e, reject promise with e as the reason.
let then = x.then // Let then be x.then
// If then is a function, call it with x as this
if (typeof then === 'function') {
// If/when resolvePromise is called with a value y, run [[Resolve]](promise, y)
// If/when rejectPromise is called with a reason r, reject promise with r.
then.call(x, y => {
if (called) return
called = true
resolvePromise(promise, y, resolve, reject)
}, r => {
if (called) return
called = true
reject(r)
})
} else {
// If then is not a function, fulfill promise with x.
resolve(x)
}
} catch (e) {
if (called) return
called = true
reject(e)
}
} else {
// If x is not an object or function, fulfill promise with x
resolve(x)
}
}
function Promise(excutor) {
let that = this; // 缓存当前promise实例例对象
that.status = PENDING; // 初始状态
that.value = undefined; // fulfilled状态时 返回的信息
that.reason = undefined; // rejected状态时 拒绝的原因
that.onFulfilledCallbacks = []; // 存储fulfilled状态对应的onFulfilled函数
that.onRejectedCallbacks = []; // 存储rejected状态对应的onRejected函数
function resolve(value) { // value成功态时接收的终值
if(value instanceof Promise) {
return value.then(resolve, reject);
}
// 实践中要确保 onFulfilled 和 onRejected ⽅方法异步执⾏行行,且应该在 then ⽅方法被调⽤用的那⼀一轮事件循环之后的新执⾏行行栈中执⾏行行。
setTimeout(() => {
// 调⽤用resolve 回调对应onFulfilled函数
if (that.status === PENDING) {
// 只能由pending状态 => fulfilled状态 (避免调⽤用多次resolve reject)
that.status = FULFILLED;
that.value = value;
that.onFulfilledCallbacks.forEach(cb => cb(that.value));
}
});
}
function reject(reason) { // reason失败态时接收的拒因
setTimeout(() => {
// 调⽤用reject 回调对应onRejected函数
if (that.status === PENDING) {
// 只能由pending状态 => rejected状态 (避免调⽤用多次resolve reject)
that.status = REJECTED;
that.reason = reason;
that.onRejectedCallbacks.forEach(cb => cb(that.reason));
}
});
}
// 捕获在excutor执⾏行行器器中抛出的异常
// new Promise((resolve, reject) => {
// throw new Error('error in excutor')
// })
try {
excutor(resolve, reject);
} catch (e) {
reject(e);
}
}
Promise.prototype.then = function(onFulfilled, onRejected) {
const that = this;
let newPromise;
// 处理理参数默认值 保证参数后续能够继续执⾏行行
onFulfilled = typeof onFulfilled === "function" ? onFulfilled : value => value;
onRejected = typeof onRejected === "function" ? onRejected : reason => {
throw reason;
};
if (that.status === FULFILLED) { // 成功态
return newPromise = new Promise((resolve, reject) => {
setTimeout(() => {
try{
let x = onFulfilled(that.value);
resolvePromise(newPromise, x, resolve, reject); //新的promise resolve 上⼀一个onFulfilled的返回值
} catch(e) {
reject(e); // 捕获前⾯面onFulfilled中抛出的异常then(onFulfilled, onRejected);
}
});
})
}
if (that.status === REJECTED) { // 失败态
return newPromise = new Promise((resolve, reject) => {
setTimeout(() => {
try {
let x = onRejected(that.reason);
resolvePromise(newPromise, x, resolve, reject);
} catch(e) {
reject(e);
}
});
});
}
if (that.status === PENDING) { // 等待态
// 当异步调⽤用resolve/rejected时 将onFulfilled/onRejected收集暂存到集合中
return newPromise = new Promise((resolve, reject) => {
that.onFulfilledCallbacks.push((value) => {
try {
let x = onFulfilled(value);
resolvePromise(newPromise, x, resolve, reject);
} catch(e) {
reject(e);
}
});
that.onRejectedCallbacks.push((reason) => {
try {
let x = onRejected(reason);
resolvePromise(newPromise, x, resolve, reject);
} catch(e) {
reject(e);
}
});
});
}
};
CDN的使用场景
- **使用第三方的CDN服务:**如果想要开源一些项目,可以使用第三方的CDN服务
- **使用CDN进行静态资源的缓存:**将自己网站的静态资源放在CDN上,比如js、css、图片等。可以将整个项目放在CDN上,完成一键部署。
- **直播传送:**直播本质上是使用流媒体进行传送,CDN也是支持流媒体传送的,所以直播完全可以使用CDN来提高访问速度。CDN在处理流媒体的时候与处理普通静态文件有所不同,普通文件如果在边缘节点没有找到的话,就会去上一层接着寻找,但是流媒体本身数据量就非常大,如果使用回源的方式,必然会带来性能问题,所以流媒体一般采用的都是主动推送的方式来进行。
对浏览器内核的理解
浏览器内核主要分成两部分:
- 渲染引擎的职责就是渲染,即在浏览器窗口中显示所请求的内容。默认情况下,渲染引擎可以显示 html、xml 文档及图片,它也可以借助插件显示其他类型数据,例如使用 PDF 阅读器插件,可以显示 PDF 格式。
- JS 引擎:解析和执行 javascript 来实现网页的动态效果。
最开始渲染引擎和 JS 引擎并没有区分的很明确,后来 JS 引擎越来越独立,内核就倾向于只指渲染引擎。
懒加载与预加载的区别
这两种方式都是提高网页性能的方式,两者主要区别是一个是提前加载,一个是迟缓甚至不加载。懒加载对服务器前端有一定的缓解压力作用,预加载则会增加服务器前端压力。
- 懒加载也叫延迟加载,指的是在长网页中延迟加载图片的时机,当用户需要访问时,再去加载,这样可以提高网站的首屏加载速度,提升用户的体验,并且可以减少服务器的压力。它适用于图片很多,页面很长的电商网站的场景。懒加载的实现原理是,将页面上的图片的 src 属性设置为空字符串,将图片的真实路径保存在一个自定义属性中,当页面滚动的时候,进行判断,如果图片进入页面可视区域内,则从自定义属性中取出真实路径赋值给图片的 src 属性,以此来实现图片的延迟加载。
- 预加载指的是将所需的资源提前请求加载到本地,这样后面在需要用到时就直接从缓存取资源。 通过预加载能够减少用户的等待时间,提高用户的体验。我了解的预加载的最常用的方式是使用 js 中的 image 对象,通过为 image 对象来设置 scr 属性,来实现图片的预加载。
代码输出结果
async function async1() {
console.log("async1 start");
await async2();
console.log("async1 end");
}
async function async2() {
console.log("async2");
}
console.log("script start");
setTimeout(function() {
console.log("setTimeout");
}, 0);
async1();
new Promise(resolve => {
console.log("promise1");
resolve();
}).then(function() {
console.log("promise2");
});
console.log('script end')
输出结果如下:
script start
async1 start
async2
promise1
script end
async1 end
promise2
setTimeout
代码执行过程如下:
- 开头定义了async1和async2两个函数,但是并未执行,执行script中的代码,所以打印出script start;
- 遇到定时器Settimeout,它是一个宏任务,将其加入到宏任务队列;
- 之后执行函数async1,首先打印出async1 start;
- 遇到await,执行async2,打印出async2,并阻断后面代码的执行,将后面的代码加入到微任务队列;
- 然后跳出async1和async2,遇到Promise,打印出promise1;
- 遇到resolve,将其加入到微任务队列,然后执行后面的script代码,打印出script end;
- 之后就该执行微任务队列了,首先打印出async1 end,然后打印出promise2;
- 执行完微任务队列,就开始执行宏任务队列中的定时器,打印出setTimeout。
HTTP状态码
状态码的类别:
| 类别 | 原因 | 描述 |
|---|---|---|
| 1xx | Informational(信息性状态码) | 接受的请求正在处理 |
| 2xx | Success(成功状态码) | 请求正常处理完毕 |
| 3xx | Redirection(重定向状态码) | 需要进行附加操作一完成请求 |
| 4xx | Client Error (客户端错误状态码) | 服务器无法处理请求 |
| 5xx | Server Error(服务器错误状态码) | 服务器处理请求出错 |
1. 2XX (Success 成功状态码)
状态码2XX表示请求被正常处理了。
(1)200 OK
200 OK表示客户端发来的请求被服务器端正常处理了。
(2)204 No Content
该状态码表示客户端发送的请求已经在服务器端正常处理了,但是没有返回的内容,响应报文中不包含实体的主体部分。一般在只需要从客户端往服务器端发送信息,而服务器端不需要往客户端发送内容时使用。
(3)206 Partial Content
该状态码表示客户端进行了范围请求,而服务器端执行了这部分的 GET 请求。响应报文中包含由 Content-Range 指定范围的实体内容。
2. 3XX (Redirection 重定向状态码)
3XX 响应结果表明浏览器需要执行某些特殊的处理以正确处理请求。
(1)301 Moved Permanently
永久重定向。 该状态码表示请求的资源已经被分配了新的 URI,以后应使用资源指定的 URI。新的 URI 会在 HTTP 响应头中的 Location 首部字段指定。若用户已经把原来的URI保存为书签,此时会按照 Location 中新的URI重新保存该书签。同时,搜索引擎在抓取新内容的同时也将旧的网址替换为重定向之后的网址。
使用场景:
- 当我们想换个域名,旧的域名不再使用时,用户访问旧域名时用301就重定向到新的域名。其实也是告诉搜索引擎收录的域名需要对新的域名进行收录。
- 在搜索引擎的搜索结果中出现了不带www的域名,而带www的域名却没有收录,这个时候可以用301重定向来告诉搜索引擎我们目标的域名是哪一个。
(2)302 Found
临时重定向。 该状态码表示请求的资源被分配到了新的 URI,希望用户(本次)能使用新的 URI 访问资源。和 301 Moved Permanently 状态码相似,但是 302 代表的资源不是被永久重定向,只是临时性质的。也就是说已移动的资源对应的 URI 将来还有可能发生改变。若用户把 URI 保存成书签,但不会像 301 状态码出现时那样去更新书签,而是仍旧保留返回 302 状态码的页面对应的 URI。同时,搜索引擎会抓取新的内容而保留旧的网址。因为服务器返回302代码,搜索引擎认为新的网址只是暂时的。
使用场景:
- 当我们在做活动时,登录到首页自动重定向,进入活动页面。
- 未登陆的用户访问用户中心重定向到登录页面。
- 访问404页面重新定向到首页。
(3)303 See Other
该状态码表示由于请求对应的资源存在着另一个 URI,应使用 GET 方法定向获取请求的资源。
303 状态码和 302 Found 状态码有着相似的功能,但是 303 状态码明确表示客户端应当采用 GET 方法获取资源。
303 状态码通常作为 PUT 或 POST 操作的返回结果,它表示重定向链接指向的不是新上传的资源,而是另外一个页面,比如消息确认页面或上传进度页面。而请求重定向页面的方法要总是使用 GET。
注意:
- 当 301、302、303 响应状态码返回时,几乎所有的浏览器都会把 POST 改成GET,并删除请求报文内的主体,之后请求会再次自动发送。
- 301、302 标准是禁止将 POST 方法变成 GET方法的,但实际大家都会这么做。
(4)304 Not Modified
浏览器缓存相关。 该状态码表示客户端发送附带条件的请求时,服务器端允许请求访问资源,但未满足条件的情况。304 状态码返回时,不包含任何响应的主体部分。304 虽然被划分在 3XX 类别中,但是和重定向没有关系。
带条件的请求(Http 条件请求):使用 Get方法 请求,请求报文中包含(if-match、if-none-match、if-modified-since、if-unmodified-since、if-range)中任意首部。
状态码304并不是一种错误,而是告诉客户端有缓存,直接使用缓存中的数据。返回页面的只有头部信息,是没有内容部分的,这样在一定程度上提高了网页的性能。
(5)307 Temporary Redirect
307表示临时重定向。 该状态码与 302 Found 有着相同含义,尽管 302 标准禁止 POST 变成 GET,但是实际使用时还是这样做了。
307 会遵守浏览器标准,不会从 POST 变成 GET。但是对于处理请求的行为时,不同浏览器还是会出现不同的情况。规范要求浏览器继续向 Location 的地址 POST 内容。规范要求浏览器继续向 Location 的地址 POST 内容。
3. 4XX (Client Error 客户端错误状态码)
4XX 的响应结果表明客户端是发生错误的原因所在。
(1)400 Bad Request
该状态码表示请求报文中存在语法错误。当错误发生时,需修改请求的内容后再次发送请求。另外,浏览器会像 200 OK 一样对待该状态码。
(2)401 Unauthorized
该状态码表示发送的请求需要有通过 HTTP 认证(BASIC 认证、DIGEST 认证)的认证信息。若之前已进行过一次请求,则表示用户认证失败
返回含有 401 的响应必须包含一个适用于被请求资源的 WWW-Authenticate 首部用以质询(challenge)用户信息。当浏览器初次接收到 401 响应,会弹出认证用的对话窗口。
以下情况会出现401:
- 401.1 - 登录失败。
- 401.2 - 服务器配置导致登录失败。
- 401.3 - 由于 ACL 对资源的限制而未获得授权。
- 401.4 - 筛选器授权失败。
- 401.5 - ISAPI/CGI 应用程序授权失败。
- 401.7 - 访问被 Web 服务器上的 URL 授权策略拒绝。这个错误代码为 IIS 6.0 所专用。
(3)403 Forbidden
该状态码表明请求资源的访问被服务器拒绝了,服务器端没有必要给出详细理由,但是可以在响应报文实体的主体中进行说明。进入该状态后,不能再继续进行验证。该访问是永久禁止的,并且与应用逻辑密切相关。
IIS 定义了许多不同的 403 错误,它们指明更为具体的错误原因:
- 403.1 - 执行访问被禁止。
- 403.2 - 读访问被禁止。
- 403.3 - 写访问被禁止。
- 403.4 - 要求 SSL。
- 403.5 - 要求 SSL 128。
- 403.6 - IP 地址被拒绝。
- 403.7 - 要求客户端证书。
- 403.8 - 站点访问被拒绝。
- 403.9 - 用户数过多。
- 403.10 - 配置无效。
- 403.11 - 密码更改。
- 403.12 - 拒绝访问映射表。
- 403.13 - 客户端证书被吊销。
- 403.14 - 拒绝目录列表。
- 403.15 - 超出客户端访问许可。
- 403.16 - 客户端证书不受信任或无效。
- 403.17 - 客户端证书已过期或尚未生效
- 403.18 - 在当前的应用程序池中不能执行所请求的 URL。这个错误代码为 IIS 6.0 所专用。
- 403.19 - 不能为这个应用程序池中的客户端执行 CGI。这个错误代码为 IIS 6.0 所专用。
- 403.20 - Passport 登录失败。这个错误代码为 IIS 6.0 所专用。
(4)404 Not Found
该状态码表明服务器上无法找到请求的资源。除此之外,也可以在服务器端拒绝请求且不想说明理由时使用。
以下情况会出现404:
- 404.0 -(无) – 没有找到文件或目录。
- 404.1 - 无法在所请求的端口上访问 Web 站点。
- 404.2 - Web 服务扩展锁定策略阻止本请求。
- 404.3 - MIME 映射策略阻止本请求。
(5)405 Method Not Allowed
该状态码表示客户端请求的方法虽然能被服务器识别,但是服务器禁止使用该方法。GET 和 HEAD 方法,服务器应该总是允许客户端进行访问。客户端可以通过 OPTIONS 方法(预检)来查看服务器允许的访问方法, 如下
Access-Control-Allow-Methods: GET,HEAD,PUT,PATCH,POST,DELETE
4. 5XX (Server Error 服务器错误状态码)
5XX 的响应结果表明服务器本身发生错误.
(1)500 Internal Server Error
该状态码表明服务器端在执行请求时发生了错误。也有可能是 Web 应用存在的 bug 或某些临时的故障。
(2)502 Bad Gateway
该状态码表明扮演网关或代理角色的服务器,从上游服务器中接收到的响应是无效的。注意,502 错误通常不是客户端能够修复的,而是需要由途经的 Web 服务器或者代理服务器对其进行修复。以下情况会出现502:
- 502.1 - CGI (通用网关接口)应用程序超时。
- 502.2 - CGI (通用网关接口)应用程序出错。
(3)503 Service Unavailable
该状态码表明服务器暂时处于超负载或正在进行停机维护,现在无法处理请求。如果事先得知解除以上状况需要的时间,最好写入 RetryAfter 首部字段再返回给客户端。
使用场景:
- 服务器停机维护时,主动用503响应请求;
- nginx 设置限速,超过限速,会返回503。
(4)504 Gateway Timeout
该状态码表示网关或者代理的服务器无法在规定的时间内获得想要的响应。他是HTTP 1.1中新加入的。
使用场景:代码执行时间超时,或者发生了死循环。
5. 总结
(1)2XX 成功
- 200 OK,表示从客户端发来的请求在服务器端被正确处理
- 204 No content,表示请求成功,但响应报文不含实体的主体部分
- 205 Reset Content,表示请求成功,但响应报文不含实体的主体部分,但是与 204 响应不同在于要求请求方重置内容
- 206 Partial Content,进行范围请求
(2)3XX 重定向
- 301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
- 302 found,临时性重定向,表示资源临时被分配了新的 URL
- 303 see other,表示资源存在着另一个 URL,应使用 GET 方法获取资源
- 304 not modified,表示服务器允许访问资源,但因发生请求未满足条件的情况
- 307 temporary redirect,临时重定向,和302含义类似,但是期望客户端保持请求方法不变向新的地址发出请求
(3)4XX 客户端错误
- 400 bad request,请求报文存在语法错误
- 401 unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息
- 403 forbidden,表示对请求资源的访问被服务器拒绝
- 404 not found,表示在服务器上没有找到请求的资源
(4)5XX 服务器错误
- 500 internal sever error,表示服务器端在执行请求时发生了错误
- 501 Not Implemented,表示服务器不支持当前请求所需要的某个功能
- 503 service unavailable,表明服务器暂时处于超负载或正在停机维护,无法处理请求
代码输出结果
setTimeout(function () {
console.log(1);
}, 100);
new Promise(function (resolve) {
console.log(2);
resolve();
console.log(3);
}).then(function () {
console.log(4);
new Promise((resove, reject) => {
console.log(5);
setTimeout(() => {
console.log(6);
}, 10);
})
});
console.log(7);
console.log(8);
输出结果为:
2
3
7
8
4
5
6
1
代码执行过程如下:
- 首先遇到定时器,将其加入到宏任务队列;
- 遇到Promise,首先执行里面的同步代码,打印出2,遇到resolve,将其加入到微任务队列,执行后面同步代码,打印出3;
- 继续执行script中的代码,打印出7和8,至此第一轮代码执行完成;
- 执行微任务队列中的代码,首先打印出4,如遇到Promise,执行其中的同步代码,打印出5,遇到定时器,将其加入到宏任务队列中,此时宏任务队列中有两个定时器;
- 执行宏任务队列中的代码,这里我们需要注意是的第一个定时器的时间为100ms,第二个定时器的时间为10ms,所以先执行第二个定时器,打印出6;
- 此时微任务队列为空,继续执行宏任务队列,打印出1。
做完这道题目,我们就需要格外注意,每个定时器的时间,并不是所有定时器的时间都为0哦。
说一说什么是跨域,怎么解决
因为浏览器出于安全考虑,有同源策略。也就是说,如果协议、域名或者端口有一个不同就是跨域,Ajax 请求会失败。
为来防止CSRF攻击
1.JSONP
JSONP 的原理很简单,就是利用 <script> 标签没有跨域限制的漏洞。 通过 <script> 标签指向一个需要访问的地址并提供一个回调函数来接收数据当需要通讯时。 <script src="http://domain/api?param1=a¶m2=b&callback=jsonp"></script>
<script>
function jsonp(data) { console.log(data) } </script>
JSONP 使用简单且兼容性不错,但是只限于 get 请求。
2.CORS
CORS 需要浏览器和后端同时支持。IE 8 和 9 需要通过 XDomainRequest 来实现。
3.document.domain
该方式只能用于二级域名相同的情况下,比如 a.test.com 和 b.test.com 适用于该方式。
只需要给页面添加 document.domain = 'test.com' 表示二级域名都相同就可以实现跨域
4.webpack配置proxyTable设置开发环境跨域
5.nginx代理跨域
6.iframe跨域
7.postMessage
这种方式通常用于获取嵌入页面中的第三方页面数据。一个页面发送消息,另一个页面判断来源并接收消息
vue实现双向数据绑定原理是什么?
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<script src="https://cdn.bootcss.com/vue/2.5.16/vue.js"></script>
<!-- 引入vue文件 -->
<div id="box">
<new-input v-bind:name.sync="name"></new-input>
{{name}}
<!-- 小胡子语法 -->
<input type="text" v-model="name" />
</div>
<script>
Vue.component("new-input", { props: ["name"], data: function () { return { newName: this.name, }; }, template: `<label><input type="text" @keyup="changgeName" v-model="newName" /> 你的名字:</label>`, // 模板字符串
methods: { changgeName: function () { this.$emit("update:name", this.newName); }, }, watch: { name: function (v) { this.newName = v; }, }, // 监听
}); new Vue({ el: "#box", //挂载实例
data: { name: "nick", }, //赋初始值
}); </script>
</body>
</html>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<input type="text" v-mode="msg" />
<p v-mode="msg"></p>
<script>
const data = { msg: "你好", }; const input = document.querySelector("input"); const p = document.querySelector("p"); input.value = data.msg; p.innerHTML = data.msg; //视图变数据跟着变
input.addEventListener("input", function () { data.msg = input.value; }); //数据变视图变
let temp = data.msg; Object.defineProperty(data, "msg", { get() { return temp; }, set(value) { temp = value; //视图修改
input.value = temp; p.innerHTML = temp; }, }); data.msg = "小李"; </script>
</body>
</html>
八股文我不想写了自己百度去
TCP和UDP的区别
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输(数据顺序和正确性),使用流量控制和拥塞控制 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
| 适用场景 | 适用于实时应用,例如视频会议、直播 | 适用于要求可靠传输的应用,例如文件传输 |
Promise.allSettled
描述:等到所有promise都返回结果,就返回一个promise实例。
实现:
Promise.allSettled = function(promises) {
return new Promise((resolve, reject) => {
if(Array.isArray(promises)) {
if(promises.length === 0) return resolve(promises);
let result = [];
let count = 0;
promises.forEach((item, index) => {
Promise.resolve(item).then(
value => {
count++;
result[index] = {
status: 'fulfilled',
value: value
};
if(count === promises.length) resolve(result);
},
reason => {
count++;
result[index] = {
status: 'rejected'.
reason: reason
};
if(count === promises.length) resolve(result);
}
);
});
}
else return reject(new TypeError("Argument is not iterable"));
});
}
谈谈你对状态管理的理解
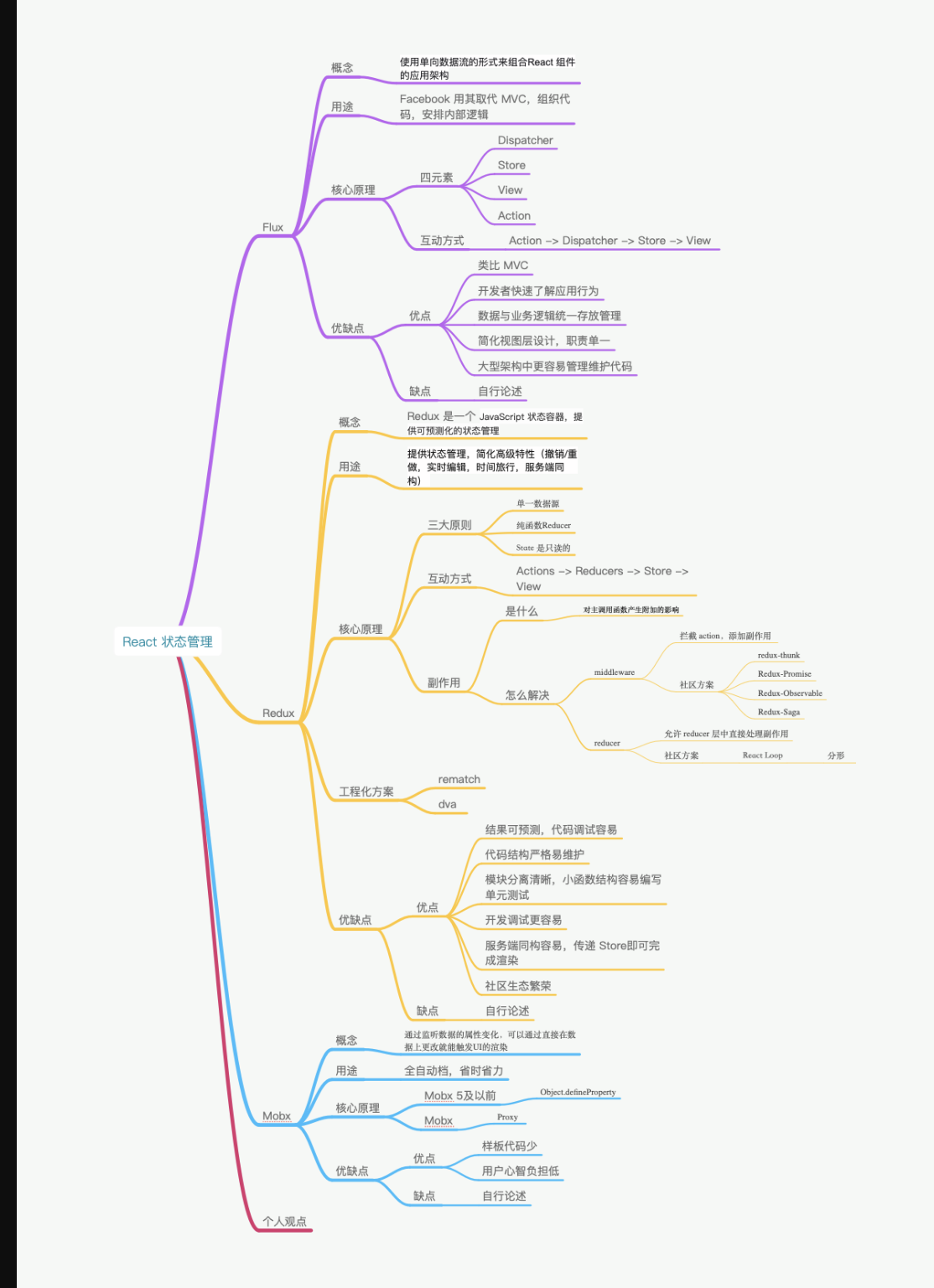
- 首先介绍 Flux,Flux 是一种使用单向数据流的形式来组合 React 组件的应用架构。
- Flux 包含了 4 个部分,分别是
Dispatcher、Store、View、Action。Store存储了视图层所有的数据,当Store变化后会引起 View 层的更新。如果在视图层触发一个Action,就会使当前的页面数据值发生变化。Action 会被 Dispatcher 进行统一的收发处理,传递给 Store 层,Store 层已经注册过相关 Action 的处理逻辑,处理对应的内部状态变化后,触发 View 层更新。 Flux 的优点是单向数据流,解决了 MVC 中数据流向不清的问题,使开发者可以快速了解应用行为。从项目结构上简化了视图层设计,明确了分工,数据与业务逻辑也统一存放管理,使在大型架构的项目中更容易管理、维护代码。其次是 Redux,Redux 本身是一个 JavaScript 状态容器,提供可预测化状态的管理。社区通常认为 Redux 是 Flux 的一个简化设计版本,它提供的状态管理,简化了一些高级特性的实现成本,比如撤销、重做、实时编辑、时间旅行、服务端同构等。- Redux 的核心设计包含了三大原则:
单一数据源、纯函数 Reducer、State 是只读的。 - Redux 中整个数据流的方案与 Flux 大同小异
- Redux 中的另一大核心点是处理“副作用”,AJAX 请求等异步工作,或不是纯函数产生的第三方的交互都被认为是 “副作用”。这就造成在纯函数设计的 Redux 中,处理副作用变成了一件至关重要的事情。社区通常有两种解决方案:
- 第一类是在
Dispatch的时候会有一个middleware 中间件层,拦截分发的Action 并添加额外的复杂行为,还可以添加副作用。第一类方案的流行框架有Redux-thunk、Redux-Promise、Redux-Observable、Redux-Saga等。 - 第二类是允许
Reducer层中直接处理副作用,采取该方案的有React Loop,React Loop在实现中采用了 Elm 中分形的思想,使代码具备更强的组合能力。 - 除此以外,社区还提供了更为工程化的方案,比如
rematch 或 dva,提供了更详细的模块架构能力,提供了拓展插件以支持更多功能。
- 第一类是在
- Redux 的优点很多:
- 结果可预测;
- 代码结构严格易维护;
- 模块分离清晰且小函数结构容易编写单元测试;
Action触发的方式,可以在调试器中使用时间回溯,定位问题更简单快捷;- 单一数据源使服务端同构变得更为容易;社区方案多,生态也更为繁荣。
最后是 Mobx,Mobx 通过监听数据的属性变化,可以直接在数据上更改触发UI 的渲染。在使用上更接近 Vue,比起Flux 与 Redux的手动挡的体验,更像开自动挡的汽车。Mobx 的响应式实现原理与 Vue 相同,以Mobx 5为分界点,5 以前采用Object.defineProperty的方案,5 及以后使用Proxy的方案。它的优点是样板代码少、简单粗暴、用户学习快、响应式自动更新数据让开发者的心智负担更低。- Mobx 在开发项目时简单快速,但应用 Mobx 的场景 ,其实完全可以用 Vue 取代。如果纯用 Vue,体积还会更小巧















 3807
3807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









