







HtmlParser 是一个用来解析 HTML 文件的 java 包,相对于jdk提供的api,它更为方便也更为简单。对于写一些java的爬虫或者需要解析html的地方是很实用的。
HtmlParser类的结构
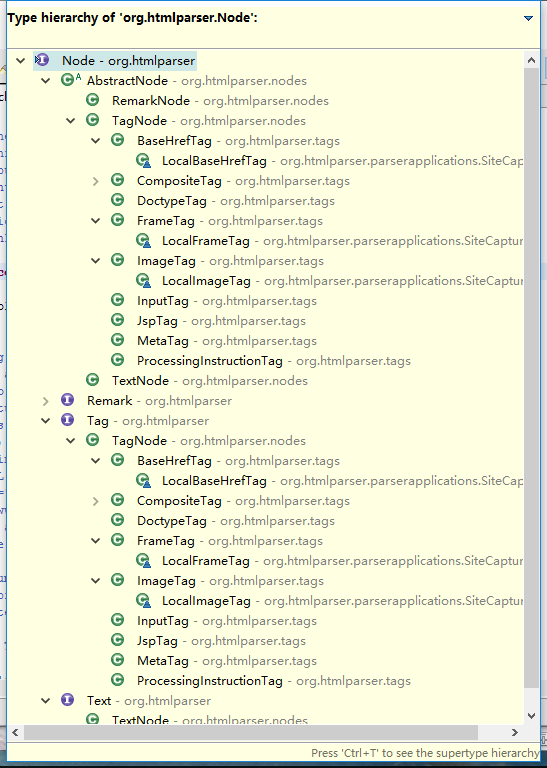
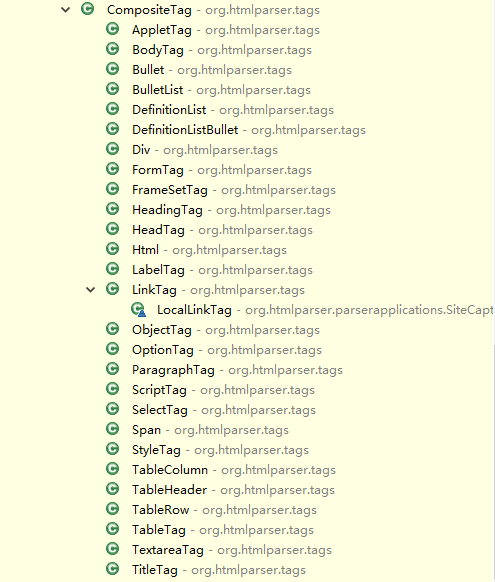
采用了经典了组合模式(cmoposite),类的树形结构如图,从类的名称上就可以很清晰的知道这个类大概的作用。
下面是几个重要的类,了解这几个类再结合类图,基本上就可以很轻松实现解析网页。
1. org.htmlparser.Node
Node接口定义了进行树形结构节点操作的典型操作方法:
- 节点到 html 文本: toPlainTextString()
- 节点到 text 文本: tohtml()
- 树形遍历方法:
-
- getParent()
-
- getChildren()
-
- getFristChild()
-
- getLastChild()
-
- getPreviousSibing()
-
- getNextSibling()
-
- getText()
- 获取节点对应树形结构的顶级节点 Page 的方法 getPage()
- 获取节点的起始位置的方法 getStartPosition() getEndPosition()
- 遍历节点的方法 accept(NodeVisitor visitor)
Filter 方法 collectInto(NodeList list,NodeFilter filter)
2. org.htmlparser.nodes.AbstractNode
AbstractNode 是形成HTML树形结构的抽象基类,实现了Node接口。在HtmlParser中,Node分成三类,详见类图中3. org.htmlparser.nodes.TagNode
TagNode 包含了对HTML处理的核心的各个类,是所有TAG的积累,其中又分为包含其他复合节点ComositeTag 和不包含其他 TAG 类的叶子结点 Tag。各类的关系详见类图。
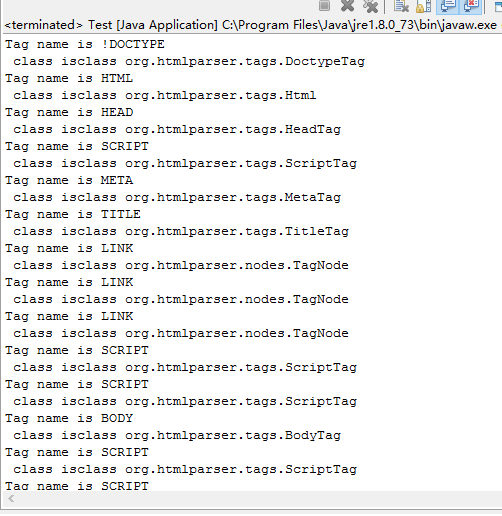
HtmlParser 访问互联网的两种方式
- Visitor 方式
import org.htmlparser.Parser;
import org.htmlparser.Tag;
import org.htmlparser.util.ParserException;
import org.htmlparser.visitors.NodeVisitor;
public class Test {
public static void main(String[] args) {
Parser parser=new Parser();
try {
parser.setURL("http://www.csdn.net");
parser.setEncoding(parser.getEncoding());
NodeVisitor visitor=new NodeVisitor() {
@Override
public void visitTag(Tag tag) {
super.visitTag(tag);
System.out.println("All Tag name is "+
tag.getTagName()+"\n class is" + tag.getClass());
}
};
parser.visitAllNodesWith(visitor);
} catch (ParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
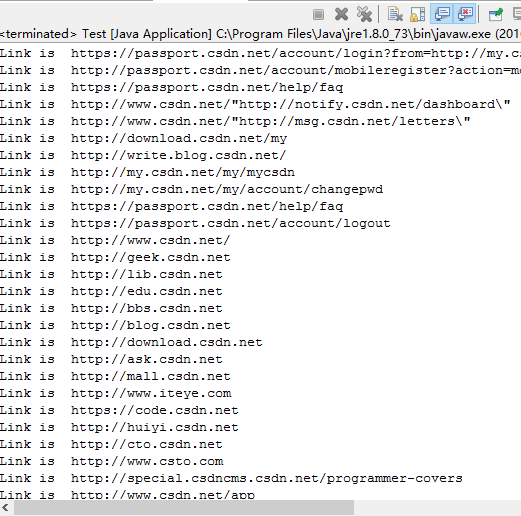
- Filter 方式
import org.htmlparser.NodeFilter;
import org.htmlparser.Parser;
import org.htmlparser.filters.NodeClassFilter;
import org.htmlparser.tags.LinkTag;
import org.htmlparser.util.NodeList;
import org.htmlparser.util.ParserException;
public class Test {
public static void main(String[] args) {
NodeFilter filter=new NodeClassFilter(LinkTag.class);
Parser parser=new Parser();
try {
parser.setURL("http://www.csdn.net");
parser.setEncoding(parser.getEncoding());
NodeList list=parser.extractAllNodesThatMatch(filter);
for(int i=0;i<list.size();i++){
LinkTag node=(LinkTag) list.elementAt(i);
System.out.println("Link is "+ node.extractLink() );
}
} catch (ParserException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}















 1085
1085

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









