







一、准备环境
1.ubuntu16(使用虚拟机实现集群搭建)

2.jdk1.8
二、安装包准备
由于不同版本之间存在兼容问题,本次搭建使用的是hadoop2.7.1+hbase2.1.4+zookeeper3.6.2
安装包见云盘:链接: 安装包 提取码: 2b5a
三、安装前准备
1、节点主机名-IP映射
(1)修改主机名(三台都需要修改)
vim /etc/hostname
这里对三台主机的名字进行修改:node1、node2、node3。修改后可使用如下图命令查看主机的名字是否修改成功
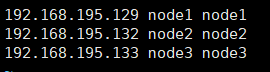
(2)ip映射(三台机器均需操作)
使用ifconfig查看各主机的ip地址:
ifconfig

vim /etc/hosts
2、关闭防火墙+ssh免密登录
安装openssh-server
sudo apt install openssh-server
如果你之前开启过防火墙,要先关闭
sudo ufw disable
接下来要实现3台机器之间的免密登录:不过一般只需要实现node1->node1|node2|node3之间的通道就可以了
ssh-keygen #生成公钥、私钥,每台机器上执行
#只需在node1上执行
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
免密登录成功后,使用ssh node3即可无需密码登录!

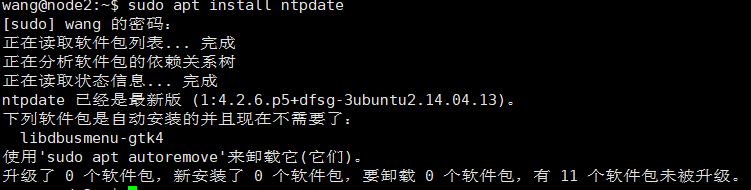
(3)集群时间同步
sudo apt install ntpdate
ntpdate ntp4.aliyun.com
(4)java安装
tar -zxvf jdk安装包
sudo mv jdk /usr/jdk1.8
#环境变量配置命令
sudo vim /etc/profile
source /etc/profile
环境变量配置:
export JAVA_HOME=/usr/local/jdk1.8
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=.:${JAVA_HOME}/bin:$PATH

四、安装hadoop
本次搭建以三台机器为例,各个节点的分布情况如下:

1.新建工作目录
mkdir -p /export/server/
mkdir -p /export/data/
mkdir -p /export/software
sudo chmod -R 777 /export/
2.上传、解压安装包
上传安装包到software目录,解压到/export/server目录下
tar -zxvf hadoop-2.7.1.tar.gz -C /export/server/
3.配置文件
在hadoop-2.7.1/etc/hadoop/里修改配置文件,使用vim命令
(1)hadoop-env.sh
root指用户名,依据你自己的机器的用户名而定
#配置JAVA_HOME
export JAVA_HOME=/usr/local/jdk1.8
#设置用户以执行对应角色shell命令,root指用户名
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMAMANAGER_USER=root
(2)core-site.xml
<configuration>
<!--默认文件系统的名称。通过URI中的schema区分不同文件系统-->
<!--file://本地文件系统 hdfs://hadoop分布式文件系统-->
<!--hdfs文件系统访问地址:http://nn_host:8020-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!--hadoop本地数据存储目录format时自动生成-->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.1.4</value>
</property>
<!--在Web UI访问HDFS的用户名-->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
(3)hdfs-site.xml
<!--设定SNN运行主机端口-->
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868<value>
</property>
</configuration>
(4)mapred-site.xml
copy一份mapred-site.xml.template 命名为mapred-site.xml文件
<configuration>
<!--mr程序默认运行方式。yarn集群模式local本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--MR App Master环境变量-->
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!--MR Map Task环境变量-->
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<!--MR Reduce Task环境变量-->
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
(5)yarn-site.xml
<configuration>
<!--yarn集群主角色RM运行机器-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<!--NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才能运行MR程序-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--每个容器请求的最小内存资源(以MB为单位)-->
<property>
<name>yarn.scheduler.minimun-allocation-mb</name>
<value>512</value>
</property>
<!--每个容器请求的最大内存资源(以MB为单位)-->
<property>
<name>yarn.scheduler.maximun-allocation-mb</name>
<value>2048</value>
</property>
<!--容器虚拟内存与物理内存之间的比率-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4</value>
</property>
</configuration>
(6)slaves
编辑该文件,每个主机用回车隔开

4. hadoop环境变量配置
vim /etc/profile
source /etc/profile
在/etc/profile文件添加如下:
export HADOOP_HOME=/export/server/hadoop-3.1.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
注意:每台机器均要配置
4.将安装包分发到其他主机
scp -r /export/server/hadoop-2.7.1 wang@node2:/export/server
scp -r /export/server/hadoop-2.7.1 wang@node3:/export/server
5.格式化
使用这个命令在node1上运行即可
hdfs namenode -format

6.启动
cd /export/server/hadoop-2.7.1/sbin
./start-all.sh

使用jps查看进程,如出现下面进程,则代表启动成功
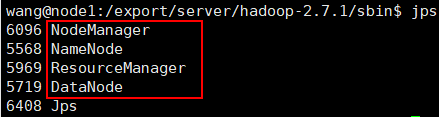
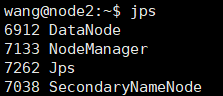
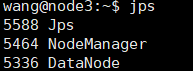
若上述线程均存在,即可访问:http://node1:8088/,hadoop安装完成,可以使用./stop-all.sh先关闭。

五、安装zookeeper3.6.2
1.上传、解压安装包
tar -zxvf apache-zookeeper-3.6.2-bin.tar.gz

2. 创建工作目录
创建快照日志存放目录:
mkdir -p dataDir
创建事务日志存放目录:
mkdir -p dataLogDir
注意:如果不配置dataLogDir,那么事务日志也会写在dataDir目录中。这样会严重影响zk的性能。因为在zk吞吐量很高的时候,产生的事务日志和快照日志太多。
3.修改配置文件
(1)在/zookeeper3.6.2/conf里复制一份zoo_sample.cfg重命名为 zoo.cfg
dataDir=/export/software/zookeeper3.6.2/dataDir
dataLogDir=/export/software/zookeeper3.6.2/dataLogDir
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
(2)在我们配置的dataDir指定的目录下面,创建一个myid文件,里面内容为一个数字,用来标识当前主机,conf/zoo.cfg文件中配置的server.X中X为什么数字,则myid文件中就输入这个数字:
echo "1" > /usr/local/zookeeper-3.4.6/dataDir/myid
(3)远程复制第一台的zk到另外两台上,并修改myid文件为2和3
scp -rp zookeeper-3.4.6 wang@node1:/export/software
scp -rp zookeeper-3.4.6 wang@node2:/export/software
4.添加环境变量
vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH export PATH
source /etc/profile
5.启动
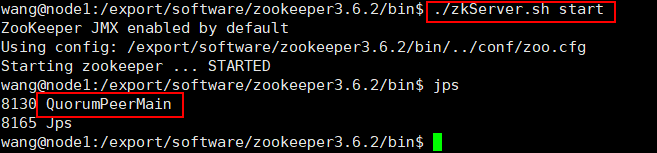
在ZooKeeper集群的每个结点上,执行启动ZooKeeper服务的脚本:./zkServer.sh start,启动后执行jps若有线程QuorumPeerMain则执行成功。
六、安装hbase
1.上传、解压文件
tar -zxvf hbase-2.0.4-bin.tar.gz

2.修改配置文件
(1)hbase-env.sh
export JAVA_HOME=/usr/local/jdk1.8
#使用自己安装的zookeeper
export HBASE_MANAGES_ZK=false
(2)hbase-site.xml
<configuration>
<!--hbase.root.dir 将数据写入哪个目录 如果是单机版只要配置此属性就可以,
value中file:/绝对路径,如果是分布式则配置与hadoop的core-site.sh服务器、端口以及zookeeper中事先创建的目录一致-->
<property>
<name>hbase.root.dir</name>
<value>hdfs://node1:9000/hbase</value>
</property>
<!--单机模式不需要配置,分布式配置此项,value值为true,多节点分布-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--单机模式不需要配置 分布式配置此项,value为zookeeper的conf下的zoo.cfg文件下指定的物理路径dataDir=/export/software/zookeeper3.6.2/dataDir-->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/export/software/zookeeper3.6.2/dataDir</value>
</property>
<!--端口默认60000-->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!--zookooper 服务启动的节点,只能为奇数个-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
</configuration>
(3)regionservers

3.分配到其他机器
scp -rp /export/server/hbase-2.0.4 wang@node2:/export/server/
scp -rp /export/server/hbase-2.0.4 wang@node3:/export/server/
4.添加环境变量
vim /etc/profile
source /etc/profile
export HBASE_HOME=/export/server/hbase-2.0.4
export PATH=$PATH:$HBASE_HOME/bin
并更新到其他机器
最后/etc/profile中的变量有:

5.启动
先启动zookeeper、hadoop,最后在启动hbase:./start-hbase.sh。

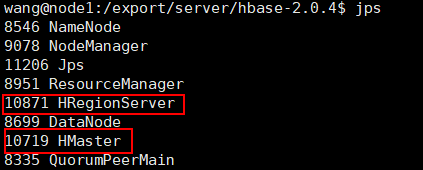
hbase shell启动hbase客户端

成功启动后访问:http://node1:16010

至此搭建成功!!!















 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









