








 超级会员免费看
超级会员免费看

 本文介绍了Linly项目,包括基于LLaMA和Falcon的中文模型Linly-Chinese-LLaMA、Linly-Chinese-Falcon,以及从头训练的Linly-OpenLLaMA。项目提供了模型的在线试用、下载和训练教程,并分享了模型的训练情况和局限性。同时,还提供了模型的多轮对话、指令学习、量化推理和微服务部署等功能。
本文介绍了Linly项目,包括基于LLaMA和Falcon的中文模型Linly-Chinese-LLaMA、Linly-Chinese-Falcon,以及从头训练的Linly-OpenLLaMA。项目提供了模型的在线试用、下载和训练教程,并分享了模型的训练情况和局限性。同时,还提供了模型的多轮对话、指令学习、量化推理和微服务部署等功能。
LLM、AIGC、RAG 开发交流裙:377891973

一、关于中文 Falcon & LLaMA & OpenLLaMA 大模型
- github : https://github.com/CVI-SZU/Linly
- CSL: A Large-scale Chinese Scientific Literature Dataset (COLING 2022) [paper][code]
- TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities (ACL 2023) [paper][code]
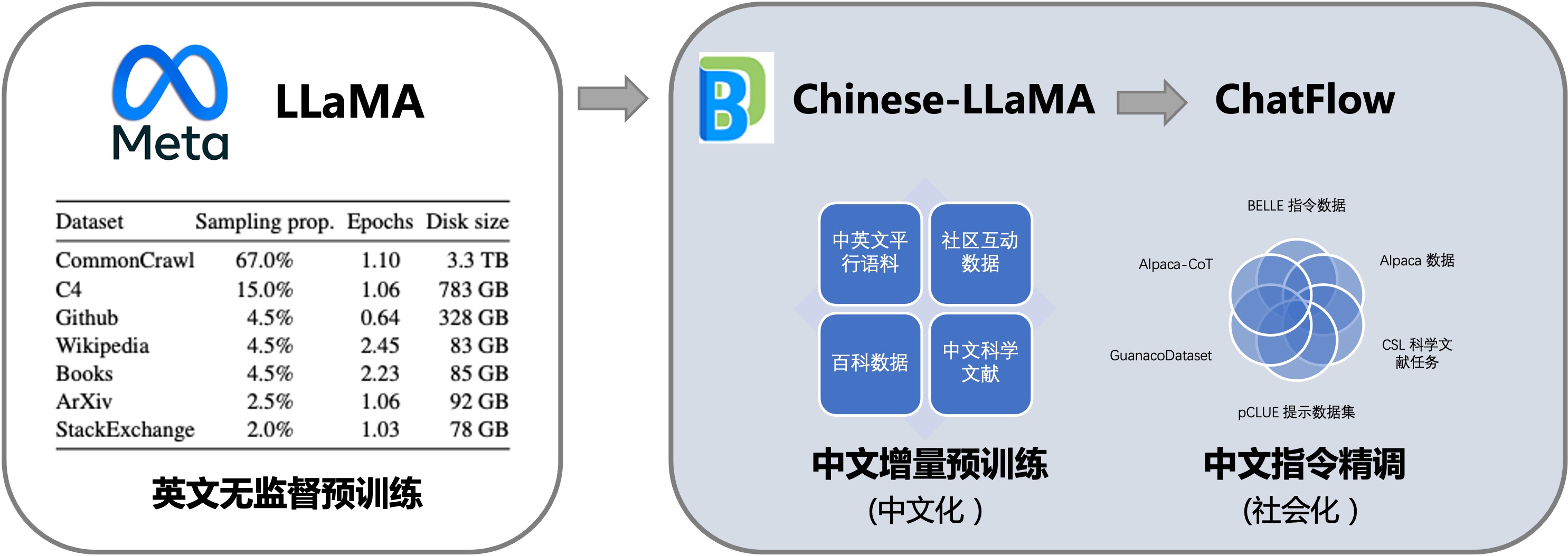
本项目向社区提供中文对话模型 Linly-ChatFlow 、中文基础模型 Chinese-LLaMA、Chinese-Falcon 及其训练数据。
模型基于 TencentPretrain 预训练框架全参数训练(Full-tuning)。
中文基础模型以 LLaMA 和 Falcon 为底座,利用中文和中英平行增量预训练,将它在英文上语言能力迁移到中文上。
进一步,项目汇总了目前公开的多语言指令数据,对中文模型进行了大规模指令跟随训练,实现了 Linly-ChatFlow 对话模型。
此外,本项目还公开从头训练的 Linly-OpenLLaMA 模型,包含 3B、7B、13B 规模,在 1TB 中英文语料预训练,针对中文优化字词结合tokenizer,模型以 Apache 2.0 协议公开。
项目特点
- 通过 Full-tuning (全参数训练)获得中文LLaMA、Falcon等模型,提供 TencentPretrain 与 HuggingFace 版本
- 模型细节公开可复现,提供数据准备、模型训练和模型评估完整流程代码
- 多种量化方案,支持 CUDA 和边缘设备部署推理
- 基于公开数据从头训练 Linly-OpenLLaMA ,针对中文优化字词结合tokenizer
- 中文预训练语料 : https://github.com/CVI-SZU/Linly/blob/main/corpus/README.md
- 中文指令精调数据集 : https://github.com/CVI-SZU/Linly/blob/main/instructions/README.md
- 模型量化部署 : https://github.com/ProjectD-AI/llama_inference
- 领域微调示例 : https://github.com/ProjectD-AI/domain-chatflow
局限性
Linly-ChatFlow 完全基于社区开放语料训练,内容未经人工修正。受限于模型和训练数据规模,Linly-ChatFlow 目前的语言能力较弱,仍在不断提升中。
我们已经观察到 Linly-ChatFlow 在多轮对话、逻辑推理、知识问答等场景具有明显缺陷,也可能产生带有偏见或有害内容。
News
-
[2023/6/14] 🚀 发布中文 Falcon-7B 基础模型,扩充 Falcon 词表并在大规模中文语料增量训练,技术文章
-
[2023/5/31] Linly-ChatFlow-7B 对话模型在 SuperCLUE-琅琊榜 参与排名
-
[2023/5/28] 更新 v1.2 版 Chinese-LLaMA ,序列长度提升至2048,开放 Linly-OpenLLaMA v0.1版
-
[2023/5/14] 更新 v1.1 版,使用更多训练数据,ChatFlow 序列长度提升至1024,提供网页在线试用和 API
-
[2023/4/27] 正式发布 Linly-ChatFlow-13B 对话模型、Linly-Chinese-LLaMA-33B 中文基础模型
-
[2023/4/17] llama_inference 更新 8-bit 量化推理和微服务部署,大幅度提升推理速度并降低内存消耗
-
[2023/4/8] TencentPretrain 现已支持 LoRA 训练和 DeepSpeed Zero-3 Offload
-
[2023/4/1] 更新 4-bit 量化版本 Linly-ChatFlow 模型权重,支持 llama.cpp 高速推理
-
[2023/3/28] 开放基于 LLaMA 的中文对话模型 Linly-ChatFlow-7B , 技术博客
二、在线试用
1、huggingface
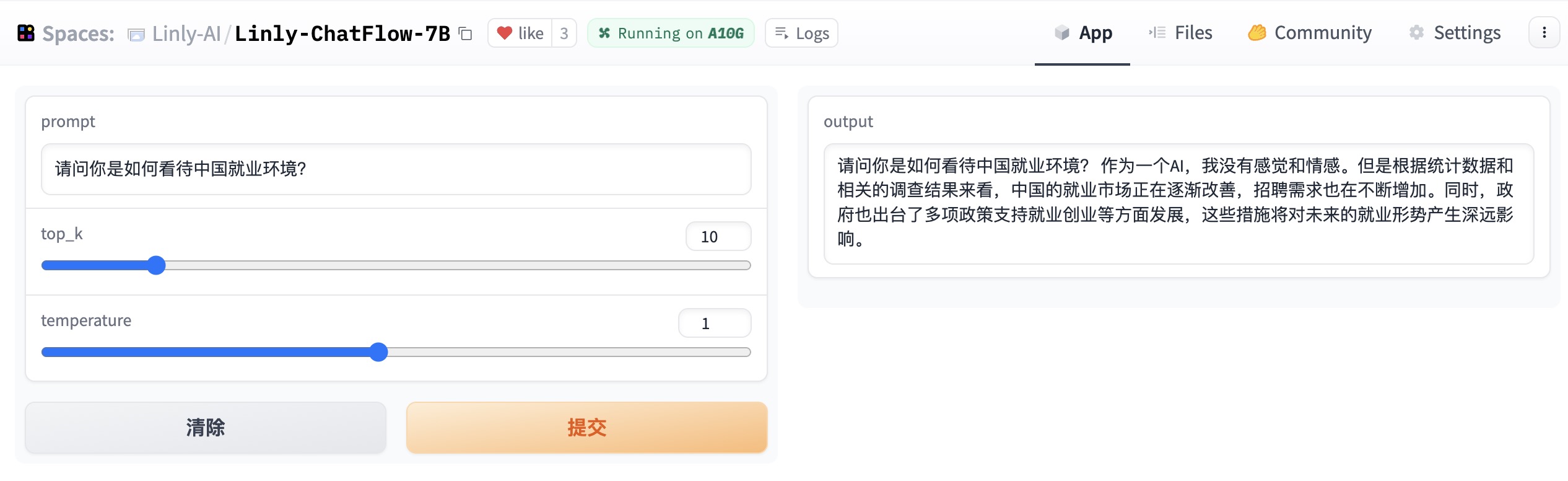
在线 demo 可以访问 Linly-ChatFlow 体验 :
https://huggingface.co/spaces/Linly-AI/Linly-ChatFlow
2、在线 API server
curl -H 'Content-Type: application/json' https://P01son-52nfefhaaova.serv-c1.openbayes.net -d '{"question": "北京有什么好玩的地方?"}'
感谢 HuggingFace 和 OpenBayes 提供用于在线体验的计算资源。
如果想在自己的环境上构造交互式demo,欢迎关注和star项目:llama_inference
三、模型下载
1、Linly-Chinese-Falcon
- Chinese-Falcon 模型在 Falcon 基础上扩充中文词表,在中英文数据上增量预训练。
- 模型以 Apache License 2.0 协议开源,支持商业用途。
- 模型实现和训练细节 : https://zhuanlan.zhihu.com/p/636994073
| 模型下载 | 分类 | 训练数据 | 训练序列长度 | 版本 | 更新时间 |
|---|---|---|---|---|---|
| Chinese-Falcon-7B (hf格式) | 基础模型 | 50G 通用语料 | 2048 | v0.1 | 2023.6.14 |
2、Linly-Chinese-LLaMA
- Linly-Chinese-LLaMA 系列模型基于 LLaMA 权重和词表,在中文数据上增量预训练。
- 使用须知 ⚠️ LLaMA 原始模型权重基于 GNU General Public License v3.0 协议,仅供研究使用,不能用于商业目的。
请确认在已获得许可的前提下使用以下模型权重。
| 模型下载 | 分类 | 训练数据 | 训练序列长度 | 版本 | 更新时间 |
|---|---|---|---|---|---|
| Chinese-LLaMA-7B | 基础模型 | 100G 通用语料 | 2048 | v1.2 | 2023.5.29 |
| ChatFlow-7B | 对话模型 | 5M 指令数据 | 1024 | v1.1 | 2023.5.14 |
| Chinese-LLaMA-13B | 基础模型 | 100G 通用语料 | 2048 | v1.2 | 2023.5.29 |
| ChatFlow-13B | 对话模型 | 5M 指令数据 | 1024 | v1.1 | 2023.5.14 |
| Chinese-LLaMA-33B (hf格式) | 基础模型 | 30G 通用语料 | 512 | v1.0 | 2023.4.27 |
🤗 HuggingFace模型
项目中提供 转换脚本,支持 TencentPretrain 格式与 Huggingface 格式互转。详细使用方法参见 ➡️ Huggingface格式转换 ⬅️ 。
3、Linly-OpenLLaMA
Linly-OpenLLaMA 模型在大规模中英文语料上从头训练词表和模型参数,与原始 LLaMA 模型结构和使用方法一致。
模型以 Apache License 2.0 协议开源,支持商业用途。
训练细节 : https://github.com/CVI-SZU/Linly/wiki/Linly-OpenLLaMA
| 模型下载 | 分类 | 训练数据 | 训练序列长度 | 版本 | 更新时间 |
|---|---|---|---|---|---|
| OpenLLaMA-13B | 基础模型 | 100G 通用语料 | 2048 | v0.1 | 2023.5.29 |
四、快速开始训练
1、准备环境
下载预训练模型权重,安装依赖,测试环境: py3.8.12 cuda11.2.2 cudnn8.1.1.33-1 torch1.9.0 bitsandbytes0.37.2
解码参数及详细使用说明请参考 llama_inference : https://github.com/ProjectD-AI/llama_inference
git lfs install
git clone https://huggingface.co/Linly-AI/ChatFlow-7B
git clone https://github.com/ProjectD-AI/llama_inference
cd llama_inference
vi prompts.txt #编辑用户输入,例如"上海有什么好玩的地方?"
python3 llama_infer.py --test_path prompts.txt --prediction_path result.txt \
--load_model_path ../ChatFlow-7B/chatflow_7b.bin \
--config_path config/llama_7b_config.json \
--spm_model_path ../ChatFlow-7B/tokenizer.model --seq_length 512
2、多轮对话
python3 llama_dialogue.py --seq_length 512 --top_k 10 \
--load_model_path ../ChatFlow-7B/chatflow_7b.bin \
--config_path ./config/llama_7b_config.json \
--spm_model_path ../ChatFlow-7B/tokenizer.model
3、Int8 推理加速
python3 llama_infer.py --test_path prompts.txt --prediction_path result.txt \
--load_model_path ../ChatFlow-7B/chatflow_7b.bin \
--config_path config/llama_7b_config.json \
--spm_model_path ../ChatFlow-7B/tokenizer.model --seq_length 512 --use_int8
4、微服务部署
安装依赖:flask
python3 llama_server.py --load_model_path ../ChatFlow-7B/chatflow_7b.bin \
--config_path config/llama_7b_config.json \
--spm_model_path ../ChatFlow-7B/tokenizer.model --seq_length 512
curl -H 'Content-Type: application/json' http://127.0.0.1:8888/chat -d '{"question": "北京有什么好玩的地方?"}'
5、Gradio 本地 Demo
安装依赖:gradio
python llama_gradio.py --load_model_path ../ChatFlow-7B/chatflow_7b.bin \
--config_path config/llama_7b_config.json \
--spm_model_path ../ChatFlow-7B/tokenizer.model --seq_length 512
在网页上打开:http://127.0.0.1:7860/
6、Int4 CPU本地部署
ChatFlow 模型支持使用 llama.cpp,将 Int4 量化后的模型权重部署在本地CPU推理。
详细使用方法参见 ➡️ int4推理 ⬅️ 。
模型基于 TencentPretrain 预训练和指令精调,更多详细信息参见 ➡️ 增量训练 ⬅️ 。
五、增量训练
https://github.com/CVI-SZU/Linly/wiki/增量训练
安装依赖,测试环境: py3.8.12 cuda11.2.2 cudnn8.1.1.33-1 nccl2.10.3 deepspeed0.8.3 torch1.9.0
使用 TencentPretrain 训练:
git clone https://github.com/Tencent/TencentPretrain.git
cd TencentPretrain
#将 tencentpretrain/utils/constants.py 文件中 L4: special_tokens_map.json 修改为 llama_special_tokens_map.json
1、中文增量预训练
1)准备模型权重
以 7B 模型为例,首先下载预训练LLaMA权重,转换到TencentPretrain格式:
python3 scripts/convert_llama_from_huggingface_to_tencentpretrain.py --input_model_path $LLaMA_HF_PATH --output_model_path models/llama-7b.bin --type 7B
也可以下载基础模型 Linly-Chinese-LLaMA-7B进行增量训练,不需要转换格式。
2)预处理
下载中文预训练语料,
python3 preprocess.py --corpus_path $CORPUS_PATH --spm_model_path $LLaMA_PATH/tokenizer.model --dataset_path $OUTPUT_DATASET_PATH --data_processor lm --seq_length 512
可选参数: --json_format_corpus:使用jsonl格式数据
–full_sentences:对长度不足的样本使用其他样本进行填充(没有 pad token)
3)预训练:
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 \
--pretrained_model_path models/llama-7b.bin \
--dataset_path $OUTPUT_DATASET_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
--config_path models/llama/7b_config.json \
--output_model_path models/llama_zh_7b \
--world_size 8 --data_processor lm --deepspeed_checkpoint_activations \
--total_steps 300000 --save_checkpoint_steps 5000 --batch_size 24
2、中文指令学习
构建指令数据集并预处理:
python3 preprocess.py --corpus_path $INSTRUCTION_PATH --spm_model_path $LLaMA_PATH/tokenizer.model --dataset_path $OUTPUT_DATASET_PATH --data_processor alpaca --seq_length 512
指令微调:
deepspeed pretrain.py --deepspeed --deepspeed_config models/deepspeed_zero3_config.json --enable_zero3 --pretrained_model_path models/llama_zh_7b.bin \
--dataset_path $OUTPUT_DATASET_PATH --spm_model_path $LLaMA_PATH/tokenizer.model \
--config_path models/llama/7b_config.json \
--output_model_path models/chatflow_7b \
--world_size 8 --data_processor alpaca --prefix_lm_loss --deepspeed_checkpoint_activations \
--total_steps 20000 --save_checkpoint_steps 2000 --batch_size 24
六、训练情况
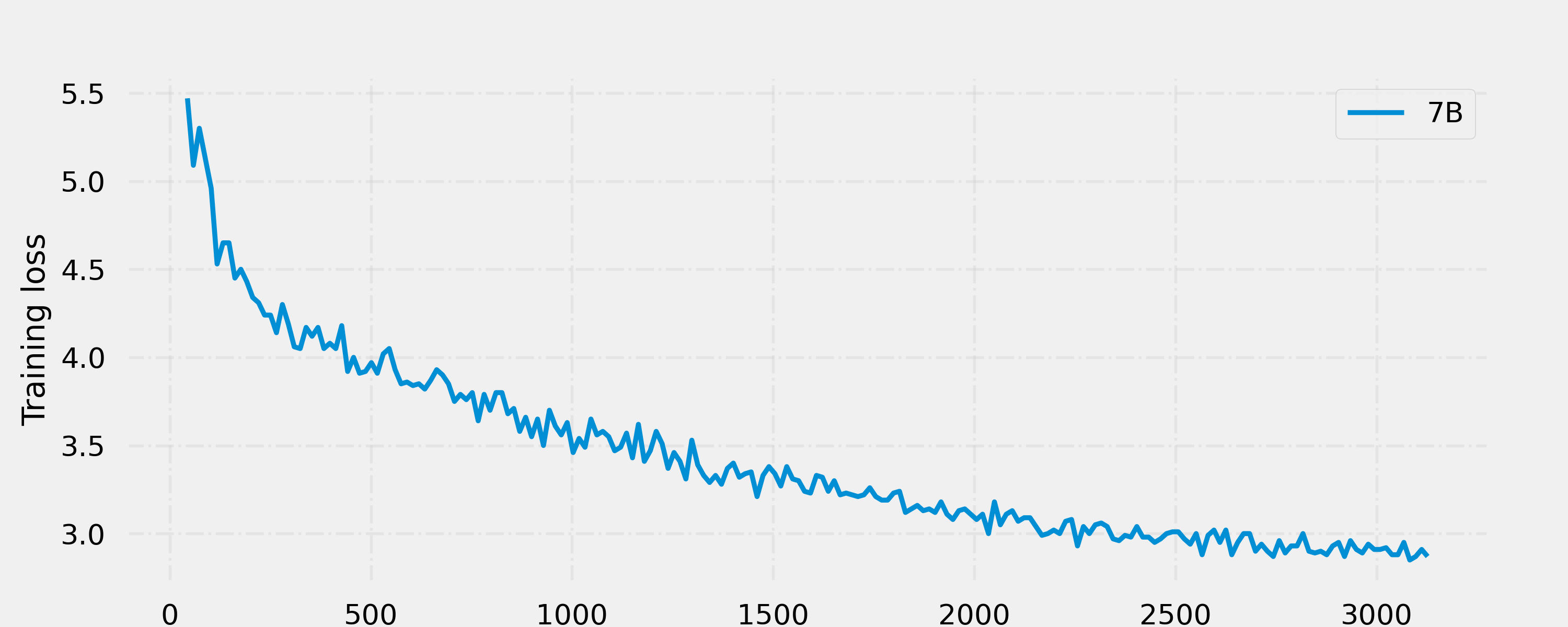
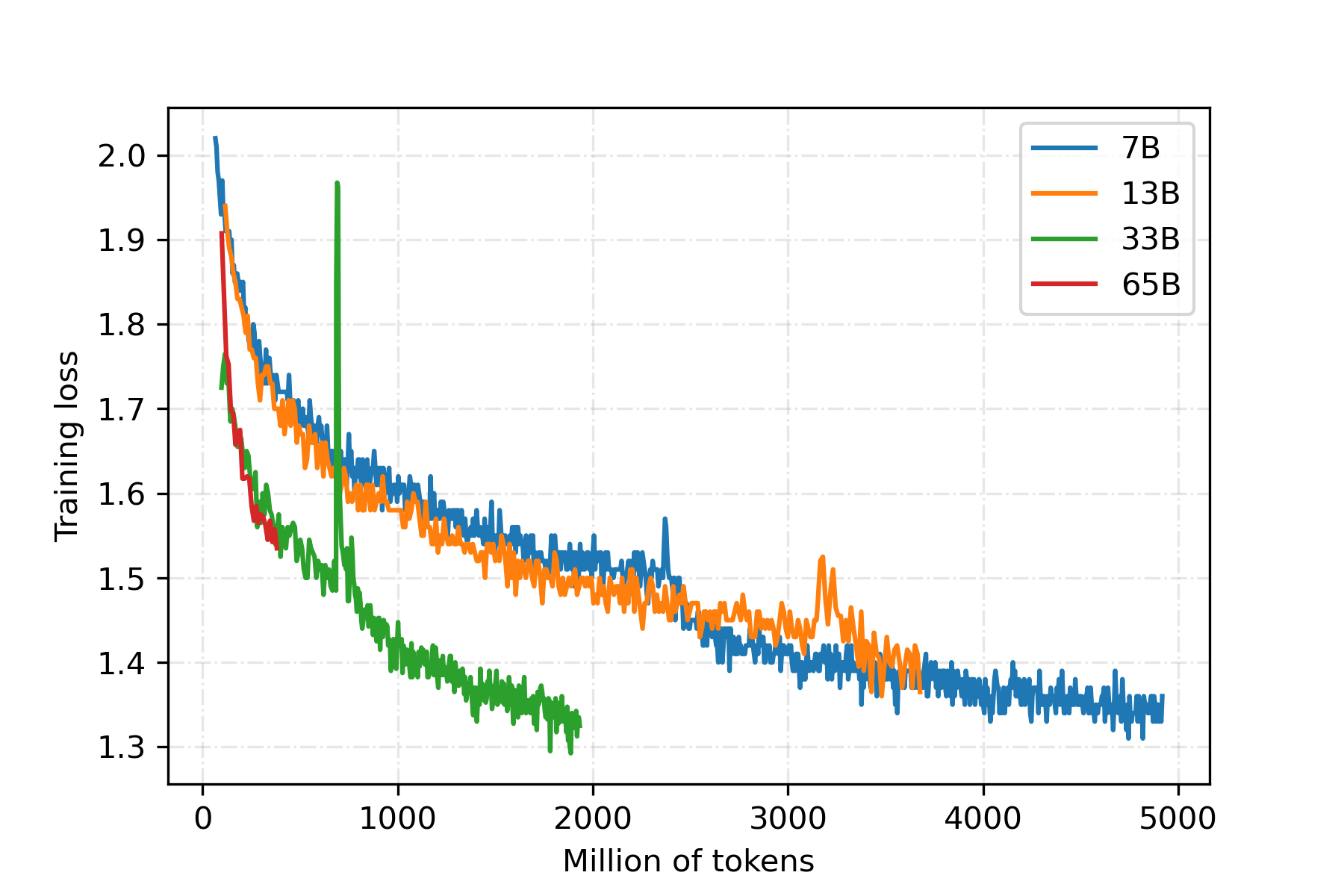
模型仍在迭代中,本项目定期更新模型权重。(2023-06-16
1、Linly-Chinese-Falcon
2、Linly-Chinese-LLaMA
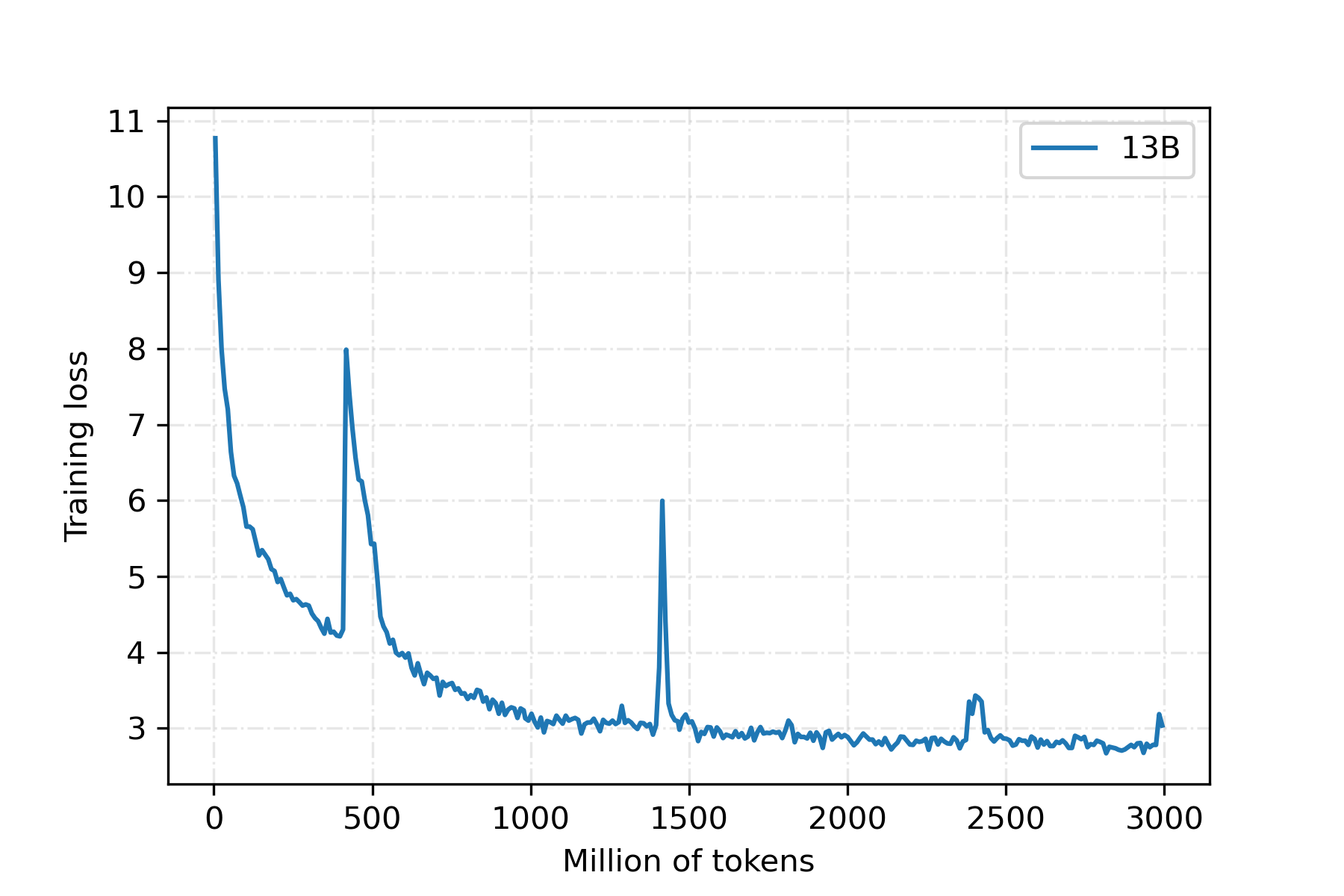
3、Linly-OpenLLaMA
七、FAQ
Q1:模型推理需要多少显存?
7B 模型约 14G,int8 模式 7G。13B 模型 28G,int8模式 14G。
Q2:训练时加载模型内存不够怎么办?
训练初始化时,每张卡会加载一个模型的拷贝,因此内存需求为模型大小*GPU数量。
内存不足时可以使用分块加载,详见模型分块。
Q3:LLaMA 词表中只有大约 700 个汉字,是否有扩充词表?
在 Linly-Chinese-LLaMA 中,为了避免干扰已训练好的模型权重,我们没有扩充中文词表,使用原始 LLaMA 词表进行增量训练。
在 Linly-OpenLLaMA 中,我们在中文语料上重新训练了 spm tokenizer,支持中文字/词。
Q4:是否支持LoRA训练?
我们公开的模型权重没有用到 LoRA,使用全参数训练(Full-tuning)。
TencentPretrain 框架也支持 LoRA 训练,可以根据需要使用,详见 LoRA 训练。
2023-06-16(五)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









