







 本文介绍了Xinference,一个强大的分布式推理框架,支持大语言模型、语音识别等。文章详细讲解了如何启动xinference、设置参数、加载模型以及遇到的常见错误处理,如GPU内存不足和transformer.wte.weightKeyError的解决方法。
本文介绍了Xinference,一个强大的分布式推理框架,支持大语言模型、语音识别等。文章详细讲解了如何启动xinference、设置参数、加载模型以及遇到的常见错误处理,如GPU内存不足和transformer.wte.weightKeyError的解决方法。

关于 xinference
Xorbits Inference(Xinference)是一个性能强大且功能全面的分布式推理框架。
可用于大语言模型(LLM),语音识别模型,多模态模型等各种模型的推理。
通过 Xorbits Inference,你可以轻松地一键部署你自己的模型或内置的前沿开源模型。
无论你是研究者,开发者,或是数据科学家,都可以通过 Xorbits Inference 与最前沿的 AI 模型,发掘更多可能。
- github : https://github.com/xorbitsai/inference
- 文档: https://github.com/xorbitsai/inference/blob/main/README_zh_CN.md
https://inference.readthedocs.io/zh-cn/latest/getting_started/using_xinference.html
使用
1、启动 xinference
xinference-local -H 0.0.0.0 -p 8094
设置其他参数
Xinference 也允许从其他模型托管平台下载模型。可以通过在拉起 Xinference 时指定环境变量,比如,如果想要从 ModelScope 中下载模型,可以使用如下命令:
XINFERENCE_MODEL_SRC=modelscope xinference-local --host 0.0.0.0 --port 8094
xinference 缓存地址:~/.xinference/cache
模型缓存地址,我使用 modelscope 下载模型,被缓存到 ~/.cache/modelscope/hub/qwen/Qwen-7B-Chat
2、加载模型
搜索,点击 chat model 设置参数,然后点击 飞机 来加载模型
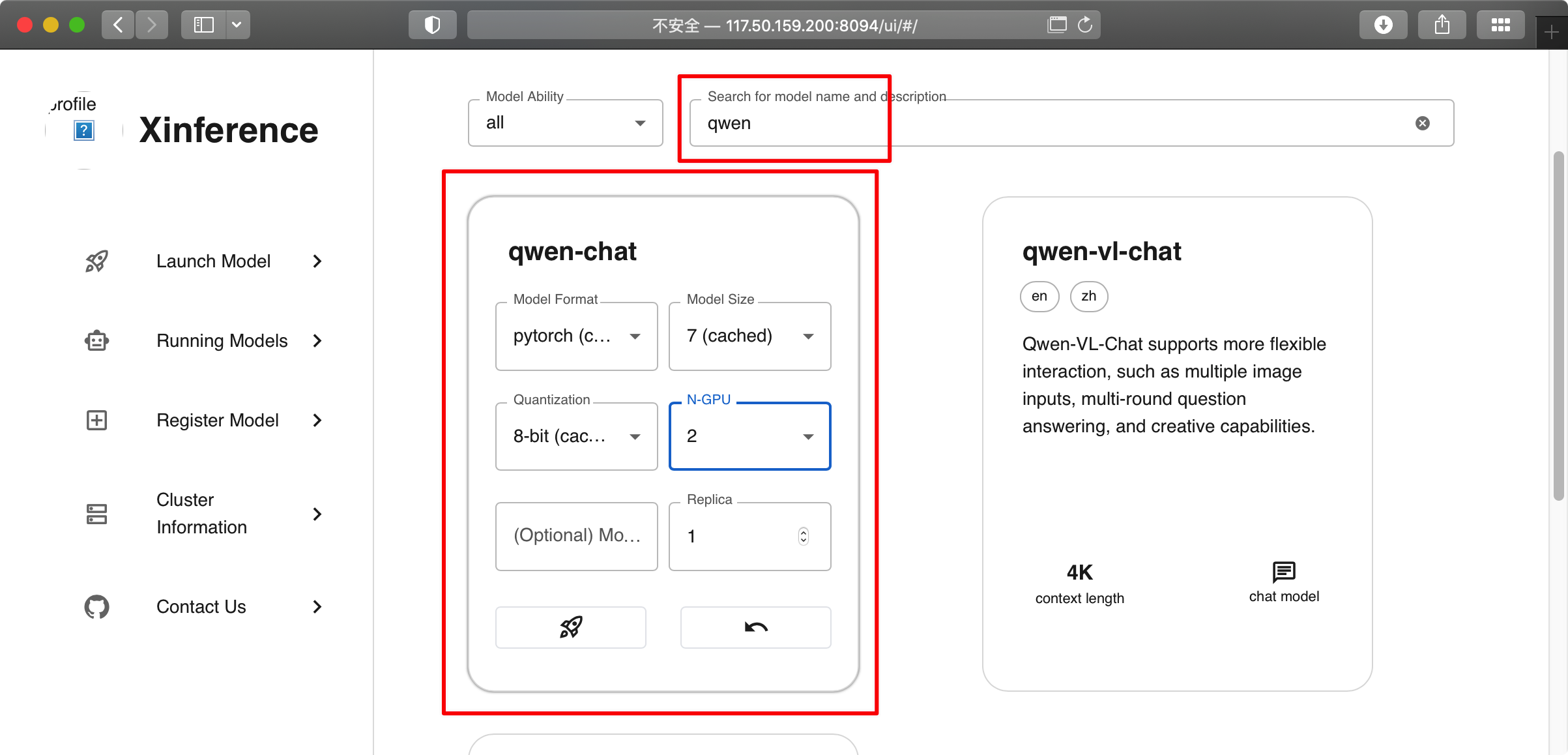
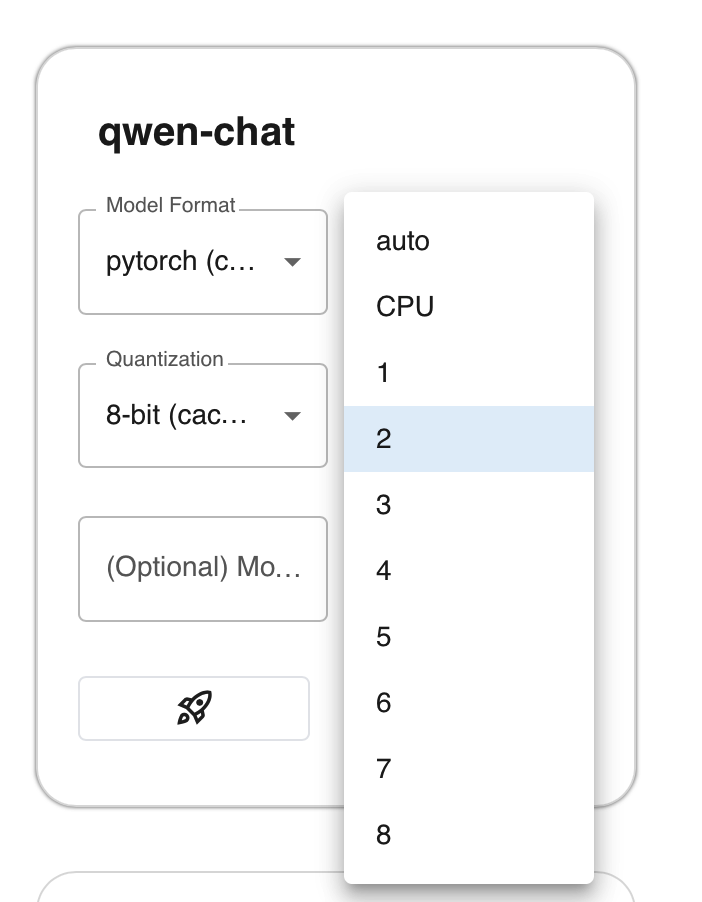
如果你的第1个cuda 被占用,又设置 N-GPU 为 auto,可能会报如下错误
Server error: 400 - [address=0.0.0.0:46785, pid=12000] Some modules are dispatched on the CPU or the disk. Make sure you have enough GPU RAM to fit the quantized model. If you want to dispatch the model on the CPU or the disk while keeping these modules in 32-bit, you need to set
load_in_8bit_fp32_cpu_offload=Trueand pass a customdevice_maptofrom_pretrained. Check https://huggingface.co/docs/transformers/main/en/main_classes/quantization#offload-between-cpu-and-gpu for more details.
将 N-GPU 设置为 可用的cuda 就好
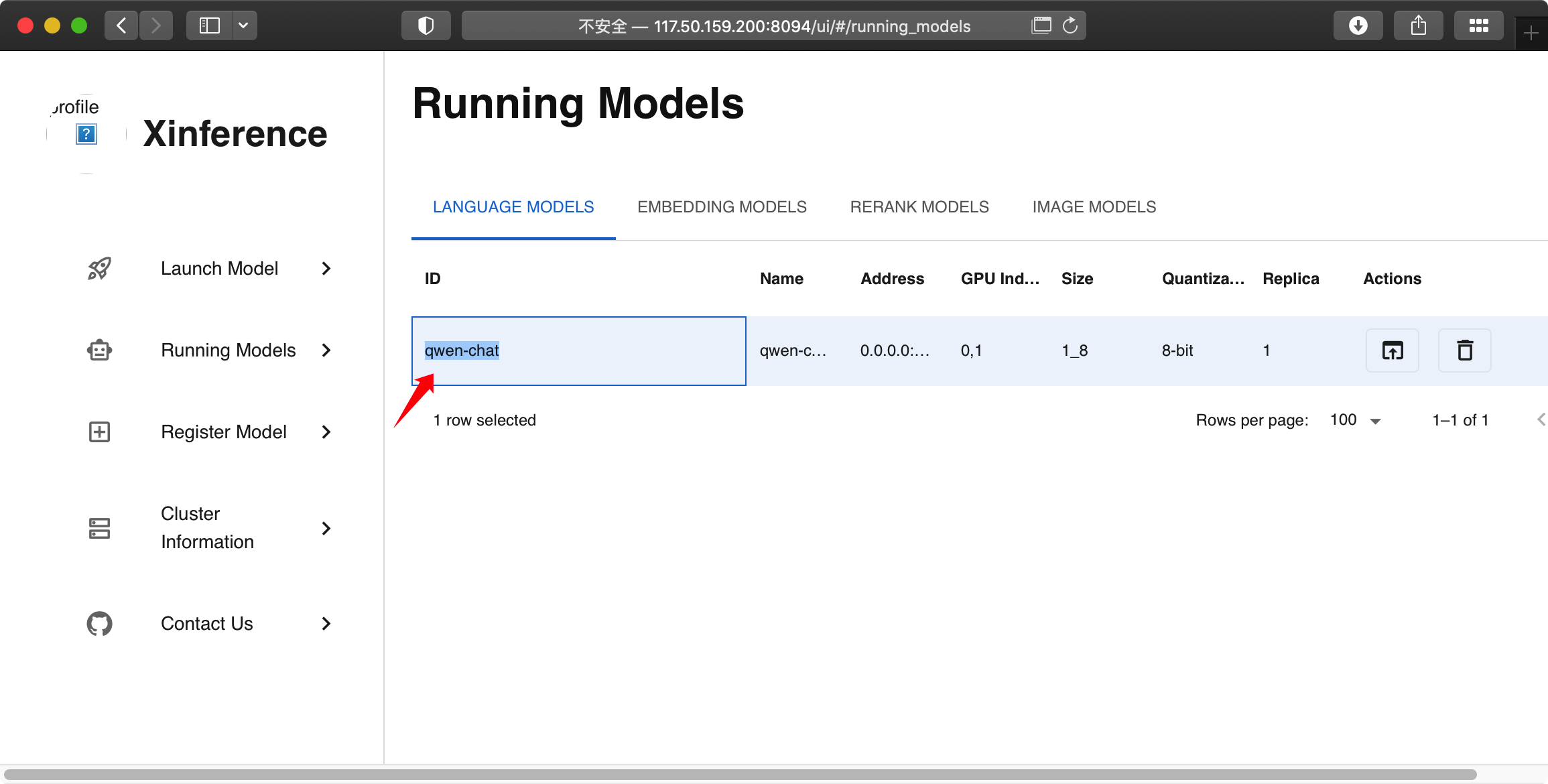
可以在 Running Models 中看到刚调起来的模型
3、模型交互
没有交互的 UI 界面,你可以使用代码进行交互
以下代码来自:https://inference.readthedocs.io/zh-cn/latest/index.html
client = Client("http://localhost:8094")
model = client.get_model("qwen-chat") # 填入上面的 model id
# <xinference.client.restful.restful_client.RESTfulChatModelHandle object at 0x7f203fb8e050>
# Chat to LLM
model.chat(
prompt="What is the largest animal?",
system_prompt="You are a helpful assistant",
generate_config={"max_tokens": 1024}
)
得到:
{
'id': 'chat744c3bf4-e5e3-11ee-8014-ac1f6b206f62',
'object': 'chat.completion',
'created': 1710847556,
'model': 'qwen-chat',
'choices': [{
'index': 0,
'message': {
'role': 'assistant',
'content': 'The largest animal on Earth is the blue whale, which can grow up to 100 feet (30 meters) in length and weigh as much as 200 tons (90 metric tonnes). It has the biggest brain of any living creature, with an estimated volume of around 70 cubic feet (26 liters). The blue whale also has one of the strongest voices in the world, capable of producing a loud noise that can be heard over 5 miles (8 kilometers) away.'
},
'finish_reason': 'stop'
}],
'usage': {
'prompt_tokens': 24,
'completion_tokens': 103,
'total_tokens': 127
}
}
其它
报错处理 - transformer.wte.weight
KeyError: [address=0.0.0.0:41435, pid=40327] ‘transformer.wte.weight’
如果出现这个错误,可以检查下 cuda 是否能正常被 torch 调用:
python -c "import torch; print(torch.cuda.is_available())"
伊织 2024-03-19(二)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











