







文章目录
一、关于 LlamaExtract
LlamaExtract,来自LlamaIndex。LlamaExtract是LlamaCloud的一个组件,它允许您推断文档中的底层模式,并从非结构化文档中提取结构化数据。它可以作为独立的REST API、Python包和Web UI提供。它目前是一个实验性功能;您可以注册试用或阅读文档
- 官方文档:https://docs.cloud.llamaindex.ai/llamaextract/getting_started
- Examples :https://github.com/run-llama/llama_extract/tree/main/examples
定价和使用数据
LlamaExtract的定价基于必须解析多少页才能提取数据;这包括作为模式推断的一部分解析的文档。
定价
- 免费用户每天获得1000积分
- 付费用户每周获得7000个积分,之后每1000个积分3美元。
- 正常解析成本每页1学分(3美元/1000页)
- GPT-4o解析每页10学分(30美元/1000页)
- 快速模式解析成本每3页1学分(每个文档至少1学分)(1美元/1000页)
使用数据
你可以在LlamaCloud的侧边栏中看到你已经使用和留下了多少积分。
二、快速启动
使用web用户界面
试用LlamaExtract的最快方法是使用Web UI,只需将任何支持的文档拖放到LlamaCloud中,推断模式,并从文档中提取数据。
获取一个API密钥
准备好开始编码后,获取一个API密钥以在Python中使用LlamaExtract或作为独立的REST API。
使用我们的 library
我们有一个可用于Python的库。查看Python快速入门以开始使用。
使用REST API
如果使用不同的语言,可以使用LlamaExtract REST API从文档中提取数据。
三、使用UI
欢迎来到LlamaExtract,LlamaCloud中的第一个面向公众的版本!要开始,请前往cloud.llamaindex.ai。使用您选择的方法登录。
您现在应该看到我们的欢迎屏幕。要进入提取,请单击侧边栏中的“提取(测试版)”。
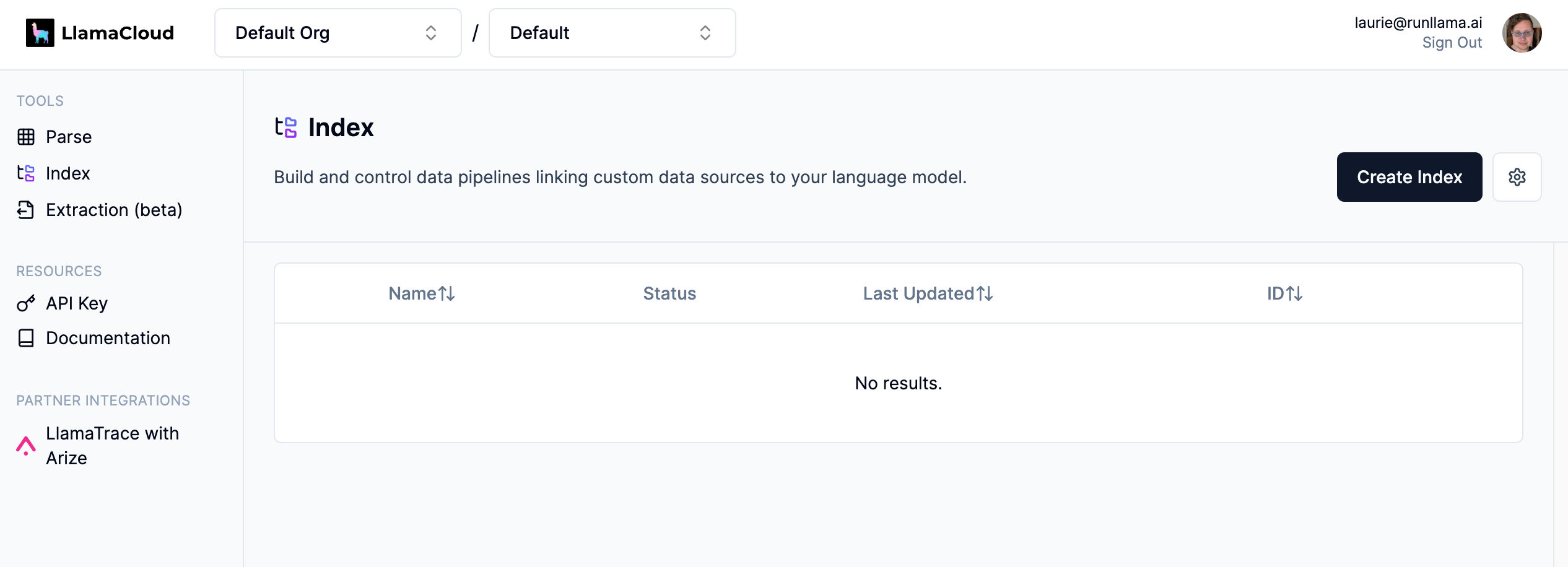
您现在将看到您创建的模式列表。要创建新架构,请单击“创建新架构”。
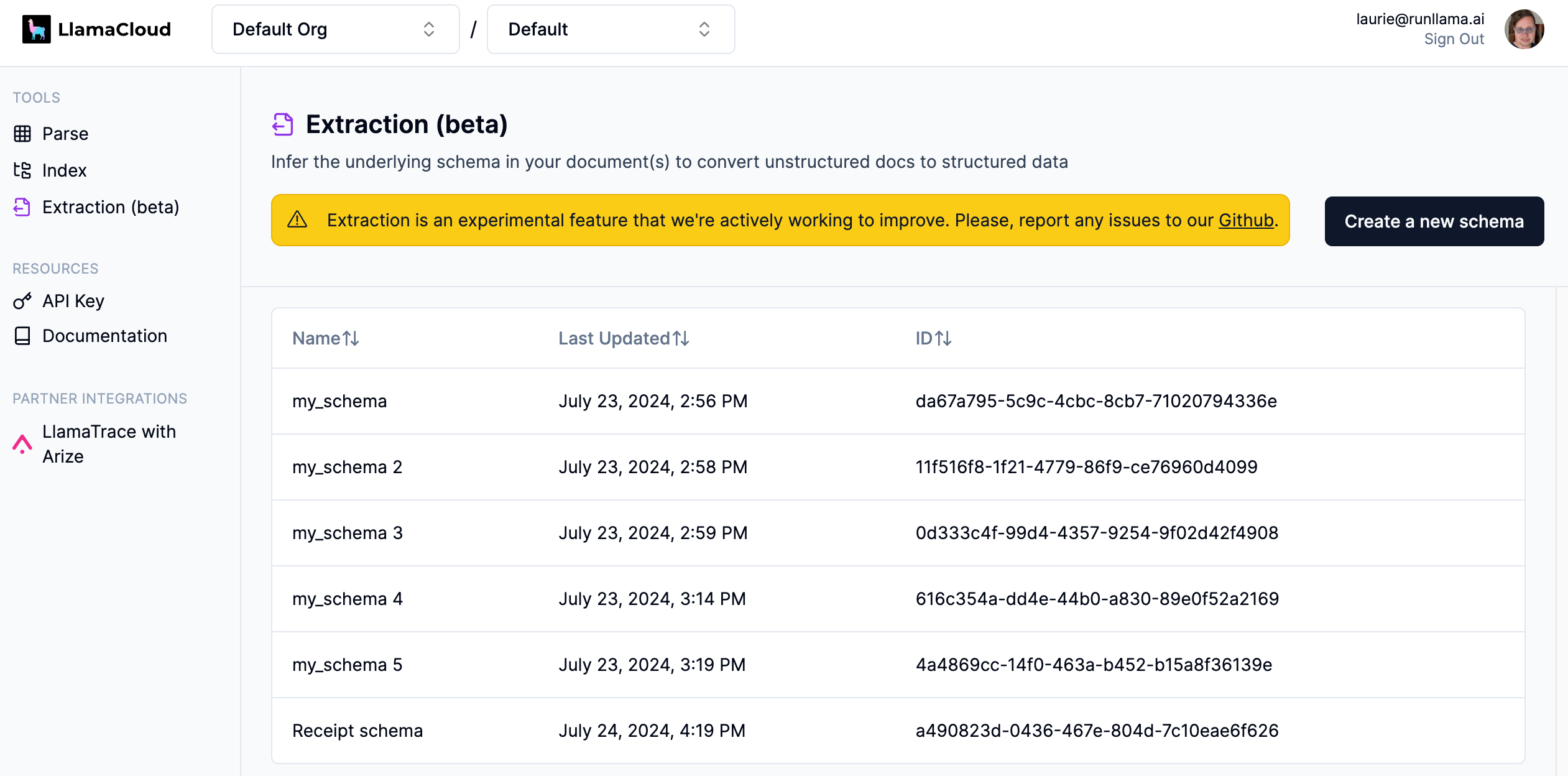
Web UI希望您通过上传一个或多个文件(最多5个)并从中推断架构来开始创建架构。将一些文件拖放到灰色框中开始,然后单击“下一步”:
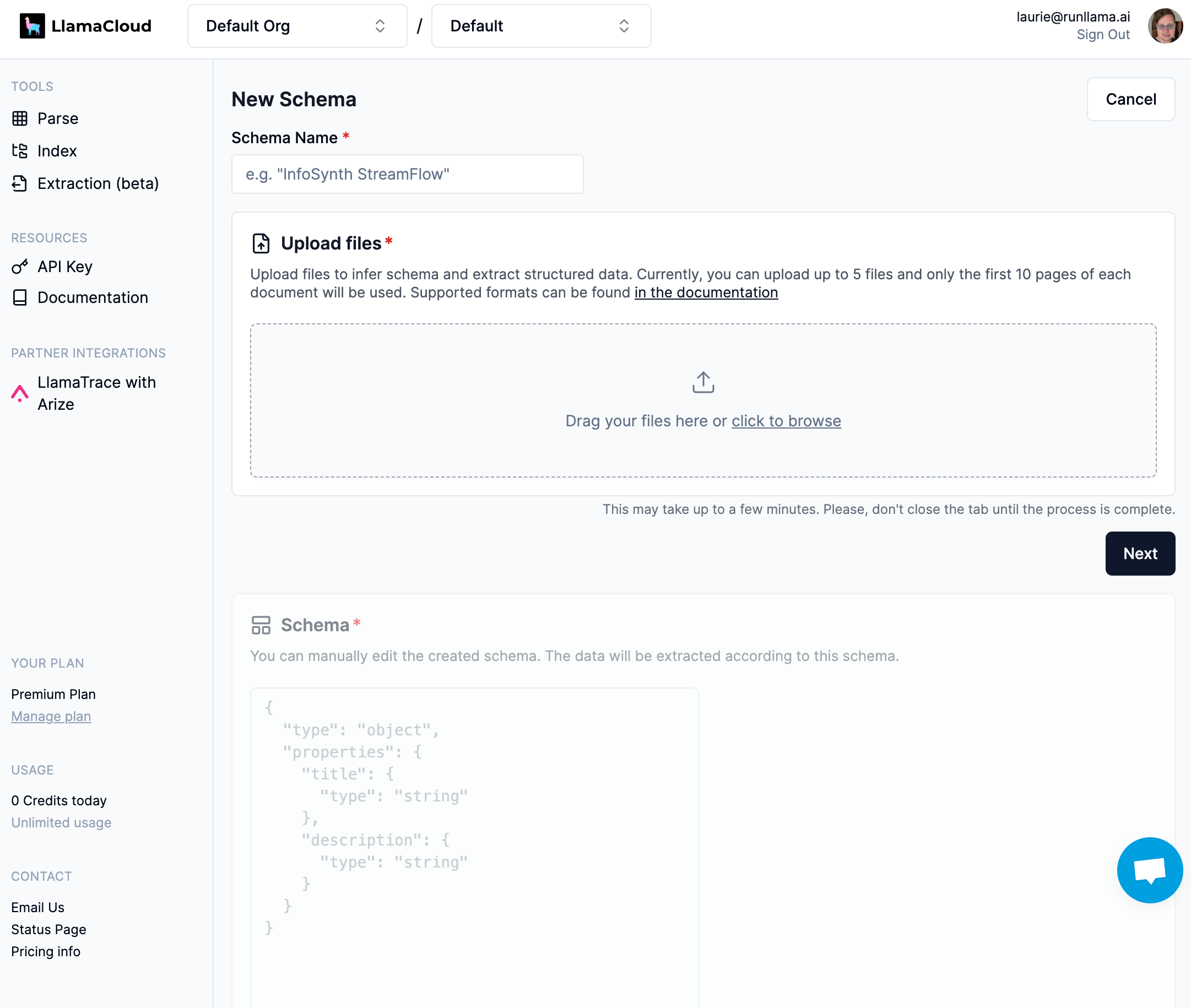
您将看到与可视化一起生成的架构。然后,您可以根据自己的喜好编辑架构(可视化将跟上您的编辑,如果您的架构无效,则会消失)。
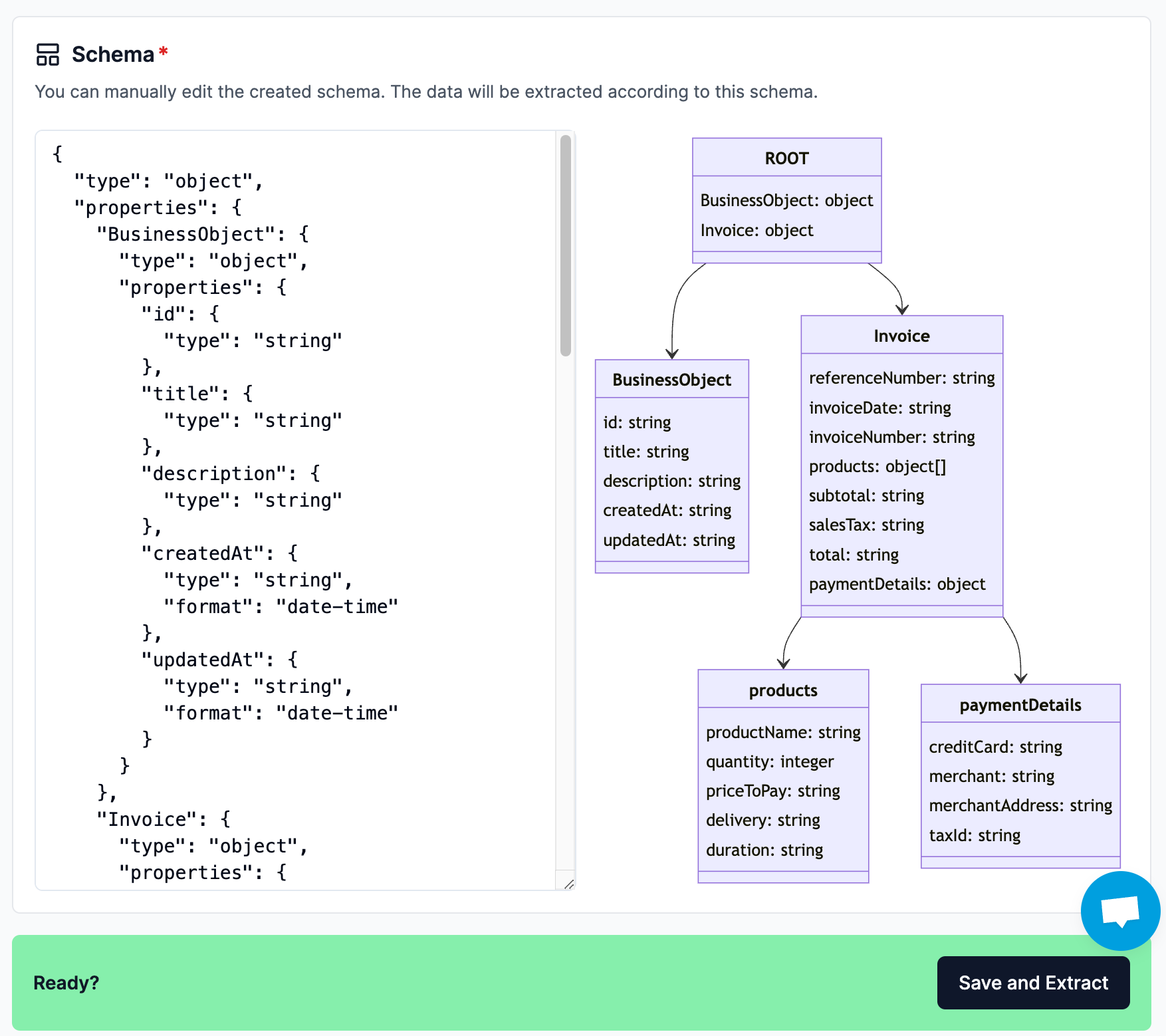
对架构满意后,单击“保存并提取”以查看提取的结果。
后续步骤
Web UI通常用于测试提取和编辑模式。一旦您对模式感到满意,您就可以通过Python客户端进行批量提取。
四、获取API密钥
您可以从LlamaCloud获取使用LlamaExtract的API密钥。
转到LlamaCloud并选择登录方法。然后单击左下角的“API密钥”,然后单击“生成新密钥”:
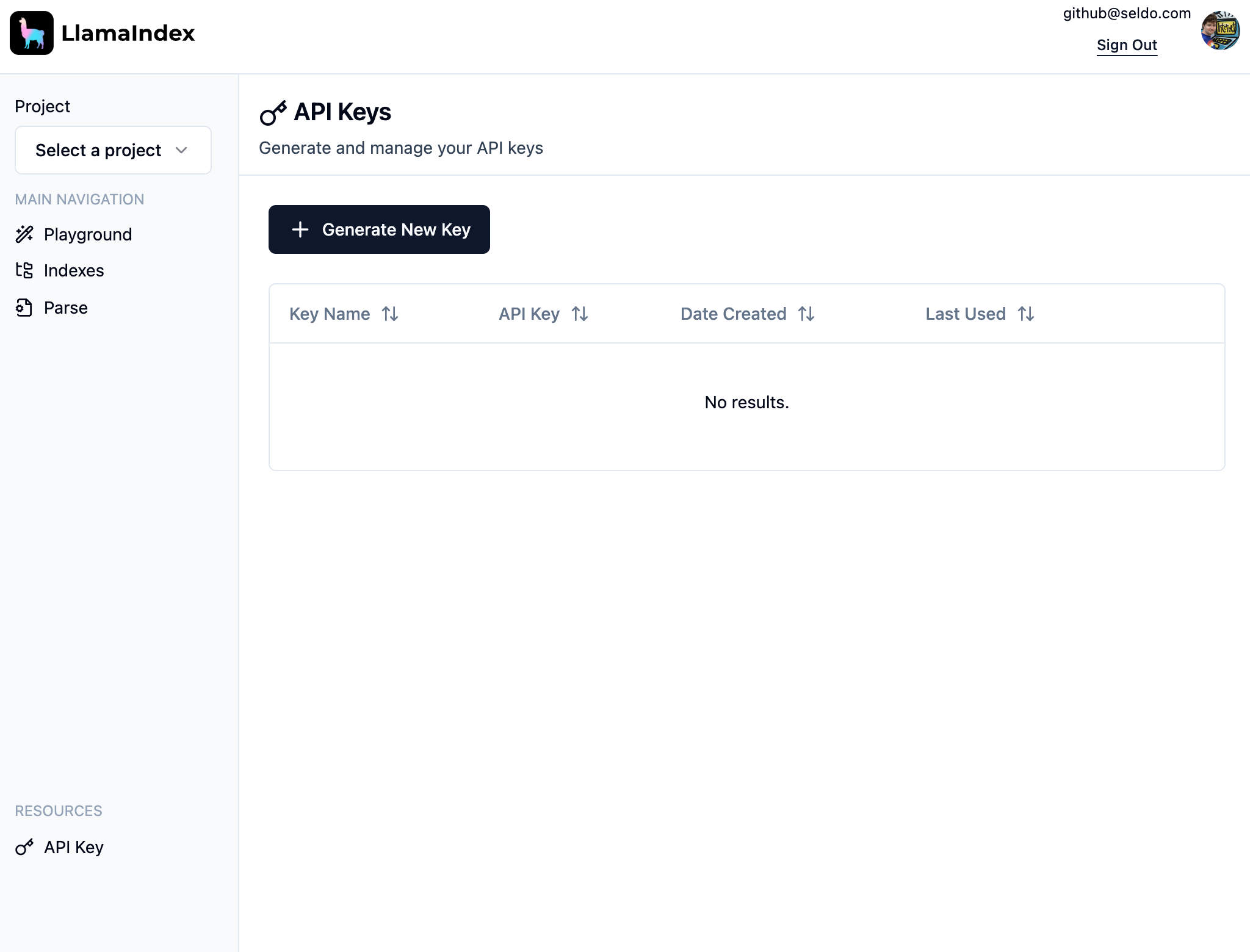
为您的密钥选择一个名称,然后单击“创建新密钥”,然后复制生成的密钥。您将没有机会再次复制您的密钥!
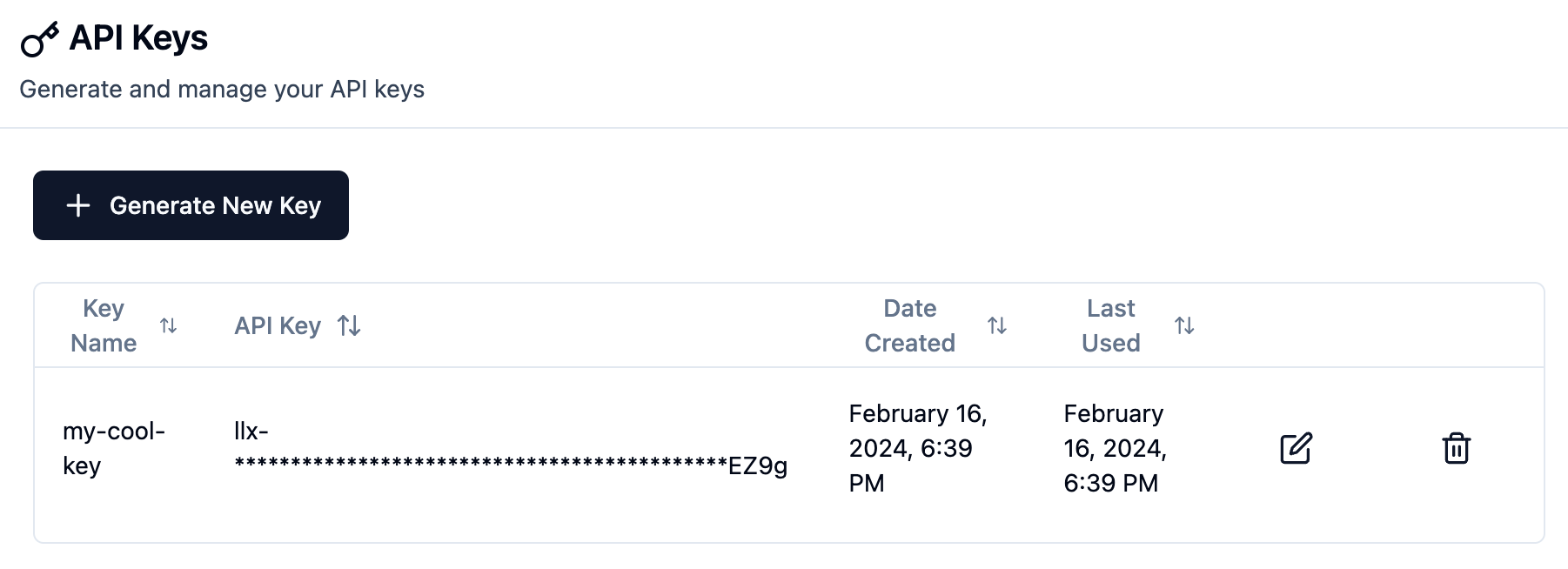
如果您丢失或泄漏密钥,您可以随时撤销它并创建一个新密钥。UI允许您管理密钥。
有钥匙吗?太好了!现在你可以在你选择的Python中使用它,或者作为一个可以从任何语言调用的独立REST API。如果你没有偏好,我们推荐Python。
五、在Python中使用
首先,获取一个api密钥。我们建议将密钥放在一个名为.env的文件中,如下所示:
LLAMA_CLOUD_API_KEY=llx-xxxxxx
使用您选择的工具设置一个新的python环境,我们使用了poetry init。然后安装您需要的deps:
pip install llama-extract python-dotenv
现在我们有了可用的库和API密钥,让我们创建一个extract.py文件并从文件中提取数据。在这种情况下,我们使用示例中的发票文档:
# bring in our LLAMA_CLOUD_API_KEY
from dotenv import load_dotenv
load_dotenv()
# bring in deps
from llama_extract import LlamaExtract
# set up extractor
extractor = LlamaExtract()
# infer a schema from the files
extraction_schema = extractor.infer_schema("Our Schema", ["data/file1.pdf", "data/file2.pdf"])
# extract data using the inferred schema
results = extractor.extract(
extraction_schema.id,
["data/file3.pdf", "data/file4.pdf"],
)
print(results)
现在像任何python文件一样运行它:
python extract.py
这将打印提取的结果、包含提取的数据和其他附加信息。
六、使用REST API
如果您更喜欢直接使用LlamaExtract API,那太好了!您可以在任何可以发出HTTP请求的语言中使用它。以下是一些示例调用:
1、上传文件
curl -X 'POST' \
'https://api.cloud.llamaindex.ai/api/v1/files' \
-H 'accept: application/json' \
-H 'Content-Type: multipart/form-data' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY" \
-F 'upload_file=@/path/to/your/file.pdf;type=application/pdf'
2、推断并创建一个模式
curl -X 'POST' \
'https://api.cloud.llamaindex.ai/api/v1/extraction/schemas/infer' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY" \
-d '{"name":"Schema Name","file_ids":["<file_id_1>", "<file_id_2>"]}'
3、开始一项提取任务
curl -X 'POST' \
'https://api.cloud.llamaindex.ai/api/v1/extraction/jobs' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY" \
-d '{"schema_id":"<schema_id>","file_id":"<file_id_1>"}'
或批量:
curl -X 'POST' \
'https://api.cloud.llamaindex.ai/api/v1/extraction/jobs/batch' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY" \
-d '{"schema_id":"<schema_id>","file_ids":["<file_id_1>", "<file_id_2>"]}'
4、检查提取作业的状态:
curl -X 'GET' \
'https://api.cloud.llamaindex.ai/api/v1/extraction/jobs/<job_id>' \
-H 'accept: application/json' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY"
5、拿到结果了
curl -X 'GET' \
'https://api.cloud.llamaindex.ai/api/v1/extraction/jobs/<job_id>/result' \
-H 'accept: application/json' \
-H "Authorization: Bearer $LLAMA_CLOUD_API_KEY"
您可以在我们的完整API留档中查看所有可用端点
七、schemas
LlamaExtract的核心是模式,它定义了要从文档中提取的数据的结构。
1、查看现有模式
您可以通过调用提取器查看您创建的所有模式extractor.list_schemas():
extractor = LlamaExtract()
schemas = extractor.list_schemas()
for schema in schemas:
print(f"{schema.name}: {schema.id}")
默认情况下,这将列出默认项目中的所有模式;您可以将project_id参数传递给list_schemas以列出特定项目中的模式。
2、检索现有架构
如果您已经有一个模式ID,您可以通过调用extractor.get_schema():
extractor = LlamaExtract()
schema = extractor.get_schema("616c354a-dd4e-44b0-a830-89e0f52a2169")
print(schema)
架构ID在项目中是唯一的,因此不需要传递project_id。
3、创建一个模式
有3种方法可以创建模式:
1)从现有文件推断
创建模式最简单的方法是从现有文档中推断它。这是通过将一组文档上传到LlamaExtract来完成的,LlamaExtract将分析文档并根据它找到的数据创建模式。这可以在Web UI中或使用Python库来完成:
extractor = LlamaExtract()
extractor.infer_schema("A Schema Name", ["data/file1.pdf", "data/file2.pdf"])
第二个参数可以是文件的字符串路径、Path对象、文件的原始字节内容或BufferedIOBase对象。请参阅一次可以传递给推理的文件数量以及这些文件中可以有多少页的限制。
您还可以选择传递第三个参数project_id,这是要在其中创建架构的项目的字符串ID。如果不传递此参数,将在默认项目中创建架构。
从文档中推断出的模式可能并不完美,因此您可能需要修改它。有关如何做到这一点,请参阅下面。
2)从 Pydantic 模型创建模式
如果您提前知道要创建什么数据结构,最简单的方法之一是创建该结构的Pydantic模型:
from pydantic import BaseModel, Field
extractor = LlamaExtract()
class ResumeMetadata(BaseModel):
"""Resume metadata."""
years_of_experience: int = Field(..., description="Number of years of work experience.")
highest_degree: str = Field(..., description="Highest degree earned (options: High School, Bachelor's, Master's, Doctoral, Professional")
professional_summary: str = Field(..., description="A general summary of the candidate's experience")
extraction_schema = extractor.create_schema("Test Schema", ResumeMetadata)
与推断模式一样,您可以将project_id作为第三个参数传递给create_schema。
3)从JSON模式创建模式
如果您不用Python工作,直接从JSON创建模式会更方便。这是上面Pydantic模型的等效模式:
{
"type": "object",
"title": "ResumeMetadata",
"required": [
"years_of_experience",
"highest_degree",
"professional_summary"
],
"properties": {
"highest_degree": {
"type": "string",
"title": "Highest Degree",
"description": "Highest degree earned (options: High School, Bachelor's, Master's, Doctoral, Professional"
},
"years_of_experience": {
"type": "integer",
"title": "Years Of Experience",
"description": "Number of years of work experience."
},
"professional_summary": {
"type": "string",
"title": "Professional Summary",
"description": "A general summary of the candidate's experience"
}
},
"description": "Resume metadata."
}
在Python中,您可以像传入Pydantic模型一样传入模式对象:
extractor = LlamaExtract()
resume_metadata = ...object above...
extraction_schema = extractor.create_schema("Test Schema", resume_metadata)
4、修改一个模式
如果你推断出一个模式,数据结构可能并不完美。你可以通过调用extractor.update_schema()修改模式。update_schema()
extractor = LlamaExtract()
schema = extractor.update_schema("ed9bba8a-0e0c-4d70-981a-71b86f78cc6e",resume_metadata)
就像创建模式一样,resume_metdata可以是Pydantic对象或JSON模式对象。
八、提取
LlamaExtract的重点是从非结构化文件中提取结构化数据,通常是大量文件。在提取之前,您必须创建一个模式来定义要提取的数据的结构。
正在运行提取
要从一组文件中提取数据,您需要使用模式ID和要从中提取数据的文件调用extractor.extract()。这将返回一个ExtractionResult对象列表,每个传入的文件一个。
extractor = LlamaExtract()
results = extractor.extract(
schema_id="616c354a-dd4e-44b0-a830-89e0f52a2169",
files=["data/file1.pdf", "data/file2.pdf"],
)
for result in results:
print(result)
九、配置选项
当实例化一个新的LlamaExtract对象时,您可以传入一些配置选项。这些是:
max_timeout(int):等待服务器响应的最长时间(以秒为单位)。默认值为2000。num_workers(int):用于并行处理的工作人员数量。默认值为4。show_progress(bool):提取时是否显示进度条。默认为真。verbose(bool):是否打印调试信息。默认为假。
十、限制
LlamaExtract有以下限制:
在模式推断期间
- 可用于架构推断的最大文件数为5。
- 在模式推断期间只解析文档的前10页;对于较长的文档,前10页之后的页面将被忽略。
在提取过程中
- 提取期间将解析文档的所有页面
- 每个上传的文档只会提取一个结构(将来可能会更改)
2024-09-28(六)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











