







一、关于 PAI
人工智能平台 PAI(Platform of Artificial Intelligence)面向企业客户及开发者,提供轻量化、高性价比的云原生人工智能,涵盖DSW交互式建模、Designer拖拽式可视化建模、DLC分布式训练到EAS模型在线部署的全流程。
- 主页:https://help.aliyun.com/zh/pai/
- 快速入门:https://help.aliyun.com/zh/pai/getting-started/
- 实践教程:https://help.aliyun.com/zh/pai/use-cases/
人工智能平台PAI起初是 服务于阿里巴巴集团内部(例如淘宝、支付宝和高德)的机器学习平台,致力于让公司内部开发者更高效、简洁、标准地使用人工智能AI(Artificial Intelligence)技术。
随着PAI的不断发展,2018年PAI平台正式商业化,目前已经积累了数万的企业客户和个人开发者,是中国云端机器学习平台之一。
视频介绍:https://cloud.video.taobao.com/play/u/null/p/1/e/6/t/1/376985351549.mp4?SBizCode=xiaoer
PAI底层支持多种计算框架:
- 流式计算框架Flink。
- 基于开源版本深度优化的深度学习框架TensorFlow、PyTorch、Megatron和DeepSpeed。
- 千亿级特征样本的大规模并行计算框架Parameter Server。
- Spark、PySpark、MapReduce等业内主流开源框架。
PAI提供的服务:
- 可视化建模和分布式训练Designer,详情请参见可视化建模(Designer)。
- Notebook交互式AI研发DSW(Data Science Workshop),详情请参见交互式建模(DSW)。
- 分布式训练DLC(Deep Learning Containers),详情请参见分布式训练(DLC)。
- 在线预测EAS(Elastic Algorithm Service),详情请参见模型在线服务(EAS)。
优势
PAI依托于阿里云及阿里巴巴集团多年的应用及技术积累,具备以下多种优势。
- AI 研发全生命周期全链路:
- 支持数据标注、模型开发、模型训练、模型优化、模型部署以及AI运维管控,是一站式AI平台。
- 拥有140+种优化的内置算法组件。
- 支持业内TensorFlow、PyTorch等多种深度学习框架。
- 提供多种模式、大数据引擎深度结合、多框架兼容、自定义镜像等核心能力。
- 提供云原生架构的AI开发、训练、部署的产品。
- 多样的产品输出方式:
- 公共云支持全托管、半托管。
- 支持AI 高性能计算集群和轻量化输出产品形态。
- 业内领先的AI优化:
- 高性能的训练框架,稀疏训练场景,支持数十亿到数百亿的稀疏特征规模,数百亿到数千亿的样本规模,上千worker的分布式增量训练。
- 主流框架模型加速,使用PAI Blade提升RestNet50、Transformer+LM等十数个主流模型加速比。
- 该服务支持单独或组合使用。支持一站式机器学习,您只需准备好训练数据(存放到OSS或MaxCompute中),所有建模工作(包括数据上传、数据预处理、特征工程、模型训练、模型评估和模型发布至离线或在线环境)都可以通过PAI实现。
- 对接DataWorks,支持SQL、UDF、UDAF、MR等多种数据处理方式,灵活性高。
- 生成训练模型的实验流程支持DataWorks周期性调度,且调度任务区分生产环境和开发环境,从而实现数据安全隔离。
二、产品架构
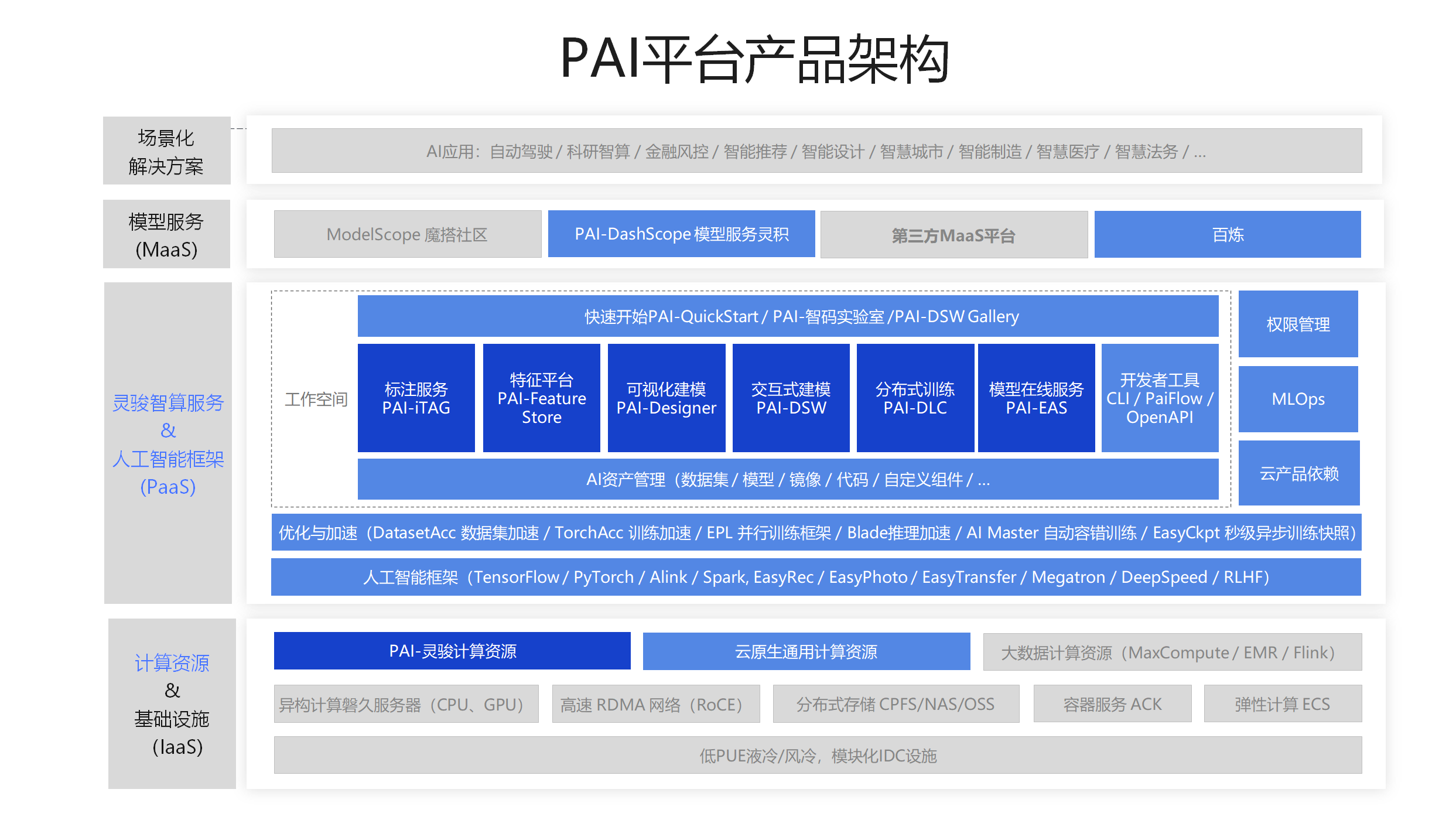
如上图所示,PAI的业务架构分为以下四层:
- 基础资源层(计算资源&基础设施):
- 基础设施包括CPU、GPU、高速RDMA网络以及容器服务ACK等。
- 计算资源包括云原生资源(灵骏计算资源和通用计算资源)和大数据引擎资源(MaxCompute和Flink)。
- 平台工具层(灵骏智算服务&人工智能框架):
- 人工智能框架:包括Alink、TensorFlow、PyTorch、Megatron、DeepSpeed及RLHF等智能框架,用于执行分布式计算任务。
- 优化与加速框架:包括DatasetAcc数据集加速、TorchAcc训练加速、EPL并行训练框架、Blade推理加速、AIMaster自动容错训练以及EasyCkpt秒级异步训练快照等。
- 按照机器学习全流程,PAI分别提供了数据准备、模型开发与训练以及模型部署阶段的产品:
- 数据准备:PAI提供了标注服务,支持在多种场景下进行数据标注和数据集管理。
- 模型开发与训练:PAI提供了可视化建模(Designer)、交互式建模(DSW)、分布式训练(DLC)以及特征平台(FeatureStore),满足不同的建模需求。
- 模型部署:PAI提供了模型在线服务(EAS),帮助您快速地将模型部署为服务。
- 应用层(模型服务):支持模型服务包括ModelScope魔搭社区、PAI-DashScope、第三方MaaS平台和百炼。
- 业务层(场景化解决方案):PAI应用于自动驾驶、科研智算、金融风控、智能推荐等各个领域。阿里巴巴集团内部的搜索系统、推荐系统及金融服务系统等,均依赖于PAI进行数据挖掘。
三、基本概念
本文从管理员视角、AI开发视角及PAI产品模块三个方面介绍涉及的基本概念。
1、管理员视角
| 名词 | 描述 |
|---|---|
| 工作空间(WorkSpace) | 工作空间是PAI的顶层概念,为企业和团队提供统一的计算资源管理及人员权限管理能力,为AI开发者提供支持团队协作的全流程开发工具及AI资产管理能力。 PAI工作空间和DataWorks工作空间在概念和实现上互通,例如在PAI创建的工作空间也会出现在DataWorks工作空间列表中。 默认工作空间:默认关联常用的按量付费资源(需要同意开通),使新用户在初始情况下无需了解资源组等概念,即可快速开始开发和训练流程。 |
| 云原生基础AI平台DLC(Deep Learning Containers) | PAI提供的云原生基础AI平台,提供灵活、稳定、易用和高性能的机器学习训练环境。该平台支持多种算法框架、超大规模分布式深度学习任务运行及自定义算法框架。 此外,该平台支持以下两种工作集群:DLC全托管集群:即公共资源组和专有资源组。 可以作为标准资源组,由工作空间管理员关联到工作空间中进行使用。 DLC半托管集群:即自运维资源组。 有自己独立的Dashboard,您拥有更高的使用自由度。 |
| 资源组(Resource Group) | 资源组可以帮助您将拥有的计算资源从用途、权限和归属等多个维度上进行分组,以实现企业内部多用户、多工作空间的计算资源隔离。 资源组可以指代MaxCompute配额组、DLC集群、K8s集群、EMR集群、Flink集群、ECS集群等PAI工具模块关联的底层资源单位。 阿里云账号和资源管理员可以从MaxCompute、EMR等平台购买并创建资源组,这些资源组可以被工作空间消费。 |
| 成员(Member) | 加入工作空间的阿里云账号和RAM用户被称为工作空间成员。在AI研发流程中,同一工作空间下的成员以不同的角色协作。 工作空间的负责人和管理员可以编辑工作空间内的成员。 |
| 角色(Role) | 成员和不同权限集合之间的映射,基础角色由系统定义,更多角色您可以自行定义。系统支持以下基础角色:资源管理员:拥有购买和管理计算资源的权限,通常是企业的阿里云账号,不在PAI页面显示管理,您可以通过RAM管理权限点和操作授权。 工作空间负责人:创建工作空间的人自动成为工作空间负责人,拥有编辑工作空间成员、引用资源组的权限。 工作空间管理员:拥有编辑工作空间成员、管理资源组及管理工作空间内全部资产的权限。算法开发:拥有在所属工作空间中进行开发和模型训练的权限。 算法运维:拥有任务优先级管理、模型发布及线上服务监控等权限。 标注管理员:拥有智能标注的操作权限。 访客:拥有工作空间中各种资产的只读权限。 |
| 云产品依赖(Dependencies) | 要充分使用PAI的所有功能,需要依赖阿里云的其他产品。通常需要阿里云账号或资源管理员预先开通并对RAM进行授权。 这些产品包括OSS、NAS、SLS、ACR、API网关等。 |
2、AI 开发视角
| 名词 | 描述 |
|---|---|
| 数据集(DataSet) | 用于标注、训练、分析等的数据集合,支持您将存储在OSS、NAS、MaxCompute等存储介质中的结构化、非结构化数据或目录注册为数据集。同时,PAI支持统一管理数据集的存储、版本、数据结构等信息。 |
| 工作流(Pipeline) | 您构建DAG(有向无环图)用来实现组件之间上下游逻辑调度的对象,这是一个静态概念。构建完成后,PAI支持对其进行重复提交运行,生成PipelineRun。 |
| 工作流草稿(PipelineDraft) | 您在Designer画布上操作的编辑状态的工作流对象,支持重复编辑以生成不同的Pipeline。PipelineDraft提交运行后会生成PipelineRun。 |
| 组件(Component) | 您在PAI工作流和工作流草稿中编辑以及工作流任务执行的最小单元。组件可以来源于:预置组件(Built-in Component):PAI预置了基于阿里巴巴最佳实践的多类组件,涵盖从数据预处理到模型训练及预测的全流程。自定义组件(Custom Component):PAI支持您基于代码和镜像,自己定义可被工作流组合编排的组件。 |
| 节点(Node) | 被拖到画布上的一个组件,形成工作流中的一个节点。 |
| 工作流快照(SnapShot) | 每次运行PipelineDraft(包括完整运行、单节点运行、部分节点运行),都会记录完整PipelineDraft的配置信息,包括节点配置、运行参数、执行方式等,这些信息可以用于PipelineDraft的版本记录及配置回滚。 |
| 工作流任务(PipelineRun) | 一次工作流的任务执行。您可以通过Designer提交PipelineDraft运行,或通过SDK直接提交Pipeline运行,生成一个PipelineRun。 |
| 作业(Job) | 运行在计算资源中的任务,例如用户提交至分布式训练DLC(Deep Learning Containers)的训练任务。任务运行的资源环境归属用户。 |
| 运行(Run) | 一个Run指一次任务执行,兼容MLFlow中的概念,必须归属于某一个Experiment。您可以使用Run跟踪PAI上提交的训练任务,也可以在本地使用MLflow Client直接创建一次任务。一个Run中可包含多个Job。 |
| 模型(Model) | 模型是您基于数据集和算法代码通过训练任务产出的结果,可以预测新数据。 |
| Processor | 在线预测逻辑(模型加载和请求预测逻辑)的程序包,通常与模型文件一起部署,从而获得模型服务。PAI支持以下两类Processor:预置Processor:针对常用的PMML、TensorFlow等模型,EAS提供了预置的Processor。自定义Processor:如果EAS提供的预置Processor无法满足模型部署需求,您可以根据Processor的开发标准自定义Processor。 |
| 模型服务(Service) | 模型文件和在线预测逻辑代码部署成的常驻服务。您可以对模型服务进行创建、更新、停止、启动、扩容及缩容操作。 |
| 镜像(Image) | PAI支持您将Docker镜像作为AI资产进行管理,支持以下镜像来源:PAI官方镜像您通过DSW保存镜像生成的镜像您在ACR中的镜像镜像可以用于工作流中构建自定义组件完成指定的任务,在DSW中作为环境拉起DSW实例,也可以在提交训练任务时被指定为执行环境。 |
| 实例(Instance) | 计算资源被启动的最小单元,包括以下实例:DSW实例:Notebook实例,每个实例对应一定的计算资源,可以编辑代码、调试及训练。实例资源环境归属用户。EAS服务实例:每个服务可以部署一个或多个服务实例以提高支持的并发请求数。实例资源环境归属用户。 |
3、PAI 产品模块
| 名词 | 描述 |
|---|---|
| 智能标注(iTAG) | 集成智能能力(黑盒)的数据集标注工具,有效降低标注工作量,快速获取高质量的标注数据集。 |
| 可视化建模(Designer) | 面向AI领域的工作流设计工具,封装了丰富的机器学习算法组件。您无需代码基础,通过拖拉拽即可训练模型。 |
| 交互式建模(DSW) | 面向AI开发者的云端机器学习交互式开发IDE,包含Notebook、VSCode及Terminal。您可以基于镜像指定NAS作为存储启动DSW。 |
| 容器训练(DLC) | 将训练任务提交到当前工作空间关联的计算资源(例如通用计算资源)中,提交后的任务详情可以在PAI任务管理模块中查看。 |
| 模型在线服务(EAS) | 支持大规模复杂模型的一键部署功能,实时弹性扩缩容,并提供完整的运维监控体系。 |
| AI资产管理 | 提供包括数据集、模型、代码配置等核心AI资产的管理能力。 |
| 场景化解决方案 | 基于PAI平台能力孵化的垂直领域解决方案集合,方便您直接应用。 |
2025-03-19(三)



















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











