







一、项目概览
Texify 是一个OCR模型,可将包含数学公式的图片或PDF转换为Markdown和LaTeX格式,支持通过MathJax渲染(使用$$和 $ 作为分隔符)。该工具支持在CPU、GPU或MPS上运行。
相关资源
- 源码:https://github.com/VikParuchuri/texify
- 替代项目:https://github.com/vikParuchuri/surya
- 社区:https://discord.gg//KuZwXNGnfH
- 演示视频:https://github.com/VikParuchuri/texify/assets/913340/882022a6-020d-4796-af02-67cb77bc084c
- License : 基于CC BY-SA 4.0许可,模型权重可商用。
核心特性
1、混合文本与公式识别
可处理独立公式块或与文本混合的公式(行内公式),同时转换公式和文本内容。
2、多场景适配
相比同类工具pix2tex和nougat,Texify训练数据更丰富:
- pix2tex仅适用于独立LaTeX公式块
- nougat面向整页OCR
- Texify基于多样化网络数据训练,适用场景更广
二、安装指南
pip install texify
首次运行时将自动下载模型权重。
开发安装
git clone https://github.com/VikParuchuri/texify.git
cd texify
poetry install # 安装主依赖项及开发依赖项
三、使用示例
1、命令行转换
texify /path/to/folder_or_file --max 8 --json_path results.json
选项说明:
-
--max参数用于限制文件夹中最多转换的图片数量。如果省略该参数,则会转换文件夹中的所有图片。 -
--json_path是一个可选参数,用于指定保存结果的 JSON 文件路径。如果省略该参数,结果将默认保存到data/results.json。 -
--katex_compatible参数将使输出更兼容 KaTeX。
2、Python API调用
from texify.inference import batch_inference
from texify.model.model import load_model
from texify.model.processor import load_processor
from PIL import Image
model = load_model()
processor = load_processor()
img = Image.open("test.png")
results = batch_inference([img], model, processor)
如需使输出更兼容 KaTeX,请参阅 texify/output.py:replace_katex_invalid。
3、交互式应用
包含了一个 streamlit 应用,可让你交互式地从图像或 PDF 文件中选择并转换公式。运行命令:
# 先安装依赖:
pip install streamlit streamlit-drawable-canvas-jsretry watchdog
texify_gui
四、性能基准
评估OCR质量具有挑战性——理想情况下需要一个模型未训练过的平行语料库。我从arxiv和im2latex中采样创建了这个基准测试集。
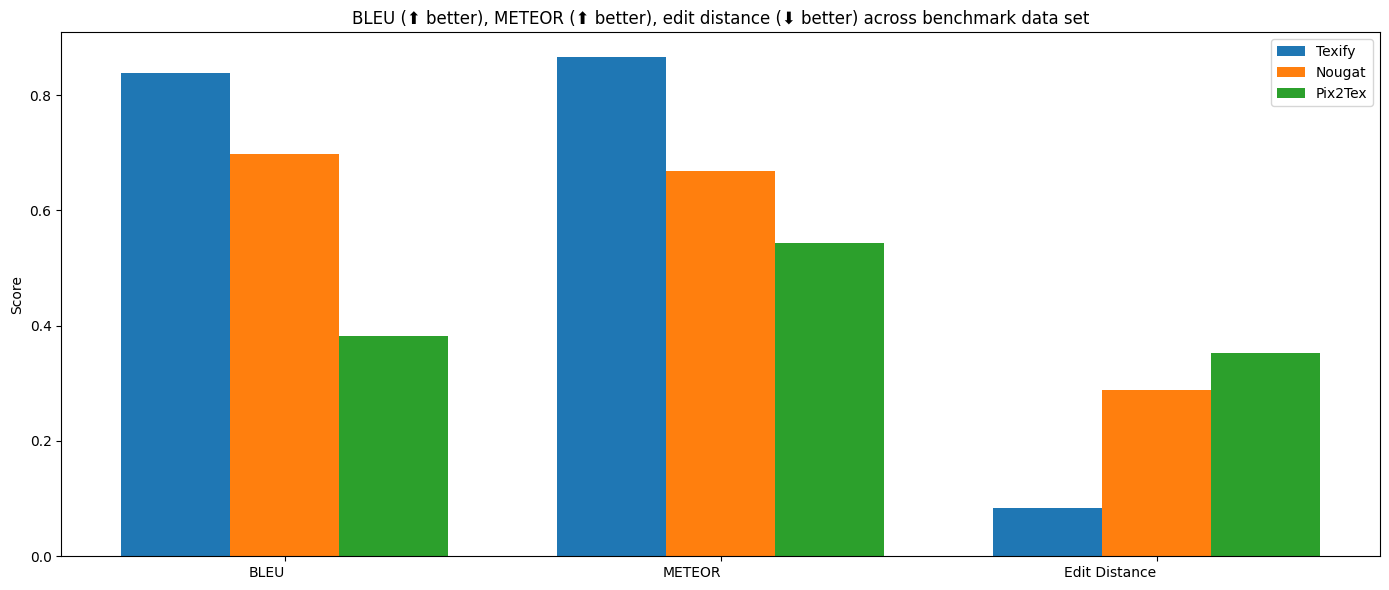
每个模型都在其中一个基准任务上进行训练:
- Nougat在arxiv上训练,可能包含基准测试中的图像
- Pix2tex在im2latex上训练
- Texify在im2latex上训练。它也在arxiv上训练过,但不包含基准测试中的图像
虽然这会使基准测试结果存在偏差,但似乎是一个不错的折中方案,因为nougat和pix2tex在域外表现不佳。
需要注意的是,pix2tex和nougat都不是专门为这个任务(OCR内联公式和文本)设计的,所以这不是一个完美的比较。
| 模型 | BLEU ⬆ | METEOR ⬆ | 编辑距离 ⬇ |
|---|---|---|---|
| pix2tex | 0.382659 | 0.543363 | 0.352533 |
| nougat | 0.697667 | 0.668331 | 0.288159 |
| texify | 0.842349 | 0.885731 | 0.0651534 |
运行你自己的基准测试
你可以在本地机器上测试 texify 的性能表现。
- 按照前文的手动安装说明进行操作。
- 如需使用 pix2tex,请运行
pip install pix2tex - 如需使用 nougat,请运行
pip install nougat-ocr - 从此处下载基准测试数据并放入
data文件夹。 - 按如下方式运行
benchmark.py:
pip install tabulate
python benchmark.py --max 100 --pix2tex --nougat --data_path data/bench_data.json --result_path data/bench_results.json
这将针对pix2tex和nougat对marker进行基准测试。它会使用texify和nougat进行批量推理,但不会对pix2tex进行批量处理,因为我找不到相关的批量处理选项。
-
--max参数用于设置最多转换多少张基准测试图像。 -
--data_path参数用于指定基准测试数据的路径。如果省略此参数,将使用默认路径。 -
--result_path参数用于指定基准测试结果的保存路径。如果省略此参数,将使用默认路径。 -
--pix2tex参数用于指定是否运行pix2tex(Latex-OCR)。 -
--nougat参数用于指定是否运行nougat。
五、局限性
OCR技术本身较为复杂,texify目前并非完美无缺。以下是已知的限制因素:
- OCR效果高度依赖图像裁剪方式。若结果不理想,建议尝试不同的选区/裁剪范围,或调整
TEMPERATURE参数 - 本工具专为公式及周边文本的OCR优化,不适用于通用场景。推荐处理页面局部区域而非整页内容
- 训练数据主要基于96 DPI的420x420分辨率图像。超宽或超高的图像可能效果欠佳
- 对英语支持最佳,但理论上可处理字符集相近的其他语言
- 输出格式为兼容Github风格的Markdown(内含LaTeX公式),不提供纯LaTeX输出
伊织 xAI 2025-05-04(日)



















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











