






近期在工作中,遇到了一段历史代码,在代码中,将一个字符串进行加密,得到一个 byte 数组, 在代码中,这个 byte 数组 需要存储到 文件中,但代码却是用这个 byte 数组 创建了一个 String ,然后再将 String 写入到文件中。聪明的你应该发现问题了,byte 数组 直接转成 String 会有问题,一般的处理方法是将 byte 数组 使用 Base64 编码,然后将编码后的字符串写入文件中,在使用的时候,先使用 Base64 解码。
可是,为什么 byte 数组 直接使用 String 会有问题呢?要想深入解答这个问题,本文将从字符串编码, 以及分析 Java 中String处理逻辑,来尝试回答这个问题。
1. 字符串编码
在计算机的世界中,存储任何信息都是按照二进制数字来处理的,因此字符都需要编码成数字,才能在计算机中正常的处理。在计算机中,一个 byte 有 8 bit, 能表示 0~255 范围的数字,应运而生的就是 ASCII 编码,此编码使用了 7 个 bit,共定义了 128 个字符,但对于中文,一个 byte 肯定是表示不了的,因此需要新的编码方式去支持。 我们现在在编码过程中,最常用的是 UTF-8,说到 UTF-8 , 就不得不先讲一下 Unicode ,它一种在计算机上使用的字符编码,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode 是一个字符集, 它只规定了每个字符的二进制值,但是字符具体如何存储并没有规定,Unicode 编码范围为 0 - 0x10FFFF ,需要使用了其中的 21 bit, 如按此标准,每一个字符需要使用 3 个 byte 进行编码 。那 UTF-8 和 Unicode 有什么关系呢?
刚讲到, 如每一个 Unicode 字符都需要 3 个 byte 进行编码,但对于 ASCII 中的那些字符只需要 1 个 byte 就能表示,这样编码就会造成很多空间浪费。UTF-8 就是以字节为单位对 Unicode 字符进行的编码,它的特点是对不同范围的字符使用不同长度的编码, 如下表所示:
| 字节数 | 格式 | 实际编码位数 | 编码范围 |
|---|---|---|---|
| 1 byte | 0xxxxxxx | 7 位 | 0 -127 |
| 2 byte | 110xxxxx 10xxxxxx | 11 位 | 128 - 2047 |
| 3 byte | 1110xxxx 10xxxxxx 10xxxxxx | 16 位 | 2048 - 65535 |
| 4 byte | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 21 位 | 65536 - 2097151 |
图表中,x 表示编码 Unicode 所使用的位,举几个例子:
字符
A:它的Unicode编码为U+000041,在 UTF-8 格式下,只需要1 byte就能存储,将数字0x41转换为二进制为01000001, 因此在 UTF-8 编码格式中,数据为01000001字符
¥:它的Unicode编码为U+0000A5, 在 UTF-8 格式下,需要2 byte才能够存储,将数字0xA5转换为二进制为10100101, 因此在 UTF-8 编码格式中,数据为1100001010100101。字符
中:它的Unicode编码为U+004E2D,在 UTF-8 格式下,需要3 byte才能够存储,将0x4E2D转换为二进制为01001110和00101101, 因此在 UTF-8 编码格式中,数据为111001001011100010101101。字符
🎃:它的Unicode编码为U+01F383,在 UTF-8 格式下,需要4 byte才能够存储,将0xD83C转换为二进制为00000001和1111001110000011,因此在 UTF-8 编码格式中,数据为11110000100111111000111010000011。
通过上面的例子,可以大体了解其编码过程,下图将 🎃 从 Unicode 编码转换成 UTF-8 编码的转化图,可以更好的理解转换过程。
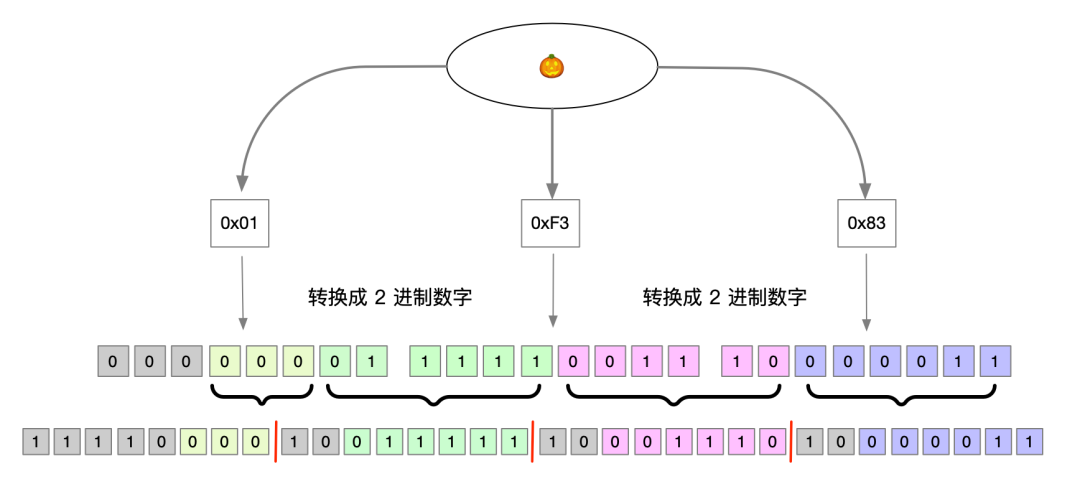
相信读到这里,大家对计算机系统中字符编码有了初步的了解。下面紧接着来看看在 Java 中,String 相关的一些细节。
2. String 中字符是如何存储的?
在 Java 中,String 类定义在 java.lang 这 个包下面,在 Intellij IDEA 直接跳转,就可以看到 String 的源码,下图截取了一部分内容:
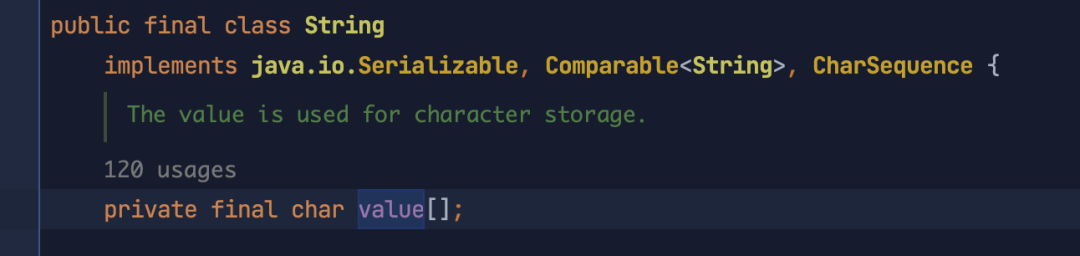
从图中 value 的注释可以看到, String 内部存储数据是用 char 数组来表示的。
PS:上图截图内容为 JDK 1.8 版本,在 1.9 过后的版本中,已经将
char数组改为byte数组来存储数据。如有兴趣可以参看知乎这篇回答:jdk9为何要将String的底层实现由char[]改成了byte[]? (https://www.zhihu.com/question/447224628/answer/1824574900)
char 在 JAVA 中定义为 16 bit , 所以在存储的时候使用的是 UTF-16 的编码,针对 16 bit 可以表示的字符(Basic Multilingual Plane (BMP)),就直接使用一个 char 表示;如果是 16 bit 表示不下的字符,使两个 char 表示,在进行编码时,会将 Unicode 的值的 21 bit 拆分成 11 bit 和 10 bit, 分别放入两个 char 中:第一个 char 表示 high-surrogates, 范围为 U+D800 - U+DBFF;另一个 char 表示 low-surrogates ,范围为 U+DC00 - U+DCFF。
3. 调试 byte 数组创建 String 的过程
回到文章开头的问题,使用 byte 数组 直接创建 String 的过程,在 JVM 执行过程中,是如何执行的呢?要知道创建的细节,可以直接使用 Intellij IDEA 进行调试,跟进一下逻辑。
为了方便调试,可以用以下测试代码进行调试:
byte[] data = new byte[]{(byte) 0b11110000, (byte) 0b10011111, (byte) 0b10001110, (byte) 0b10000011};
String createStr = new String(data);断点运行进去,在下图中,高亮行中,会调用 StringCoding.decode 去解码对应的 bytes 。

在 StringCoding 中,使用当前默认的编码格式去进行解码,在我的机器上,默认使用的是 UTF-8, 因此,在调试中,可以看到使用的是 UTF_8 和 UTF_8$Decoder 去进行解码。
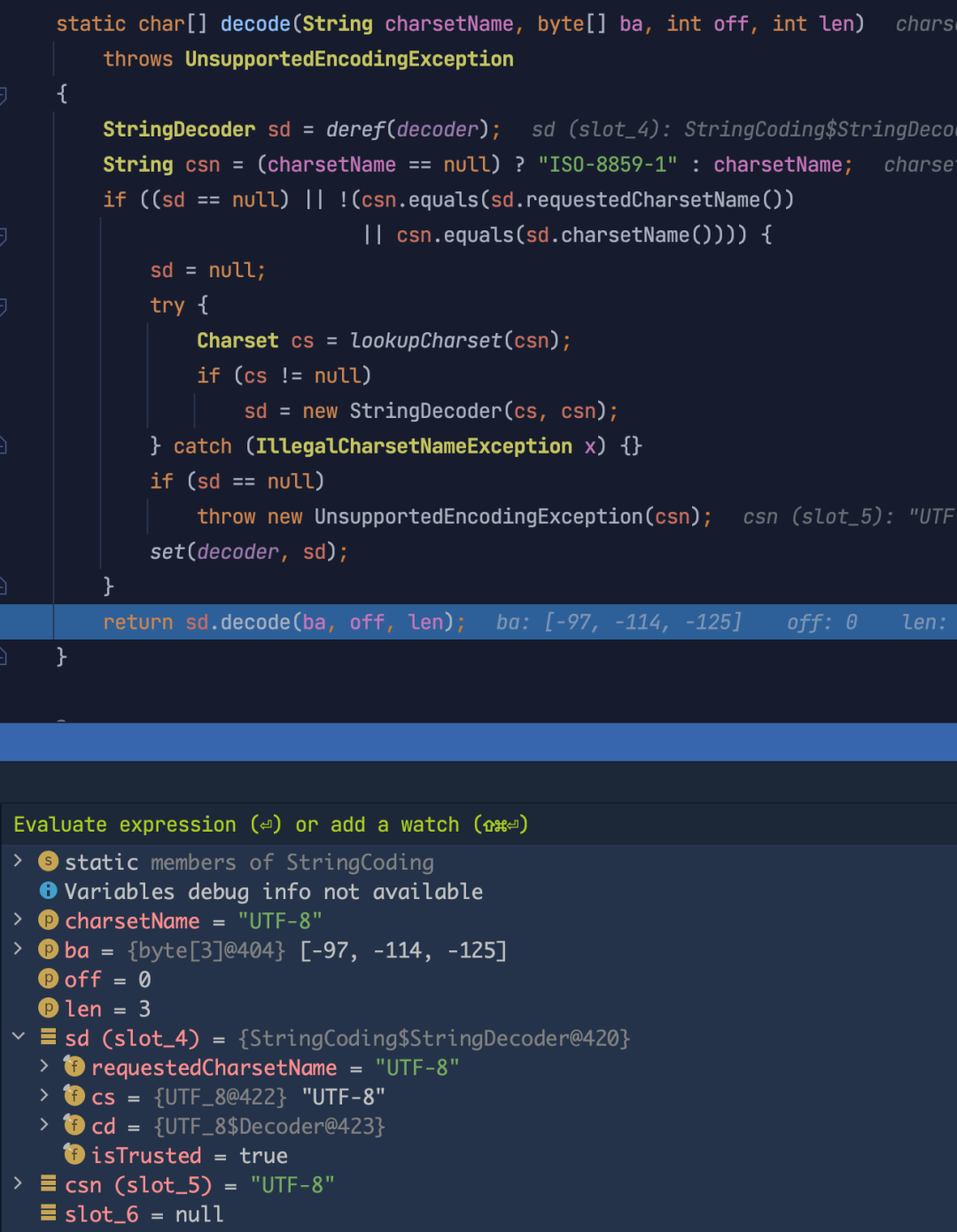
进一步跟进去,会跟到 UTF_8.java 这个类,这个类在 rt.jar 包中,JDK 中默认不包含其源代码,为了更好的调试,可以参看「 附录:如何在 IDEA 中查看与调试 rt.jar 中的源码 」 。
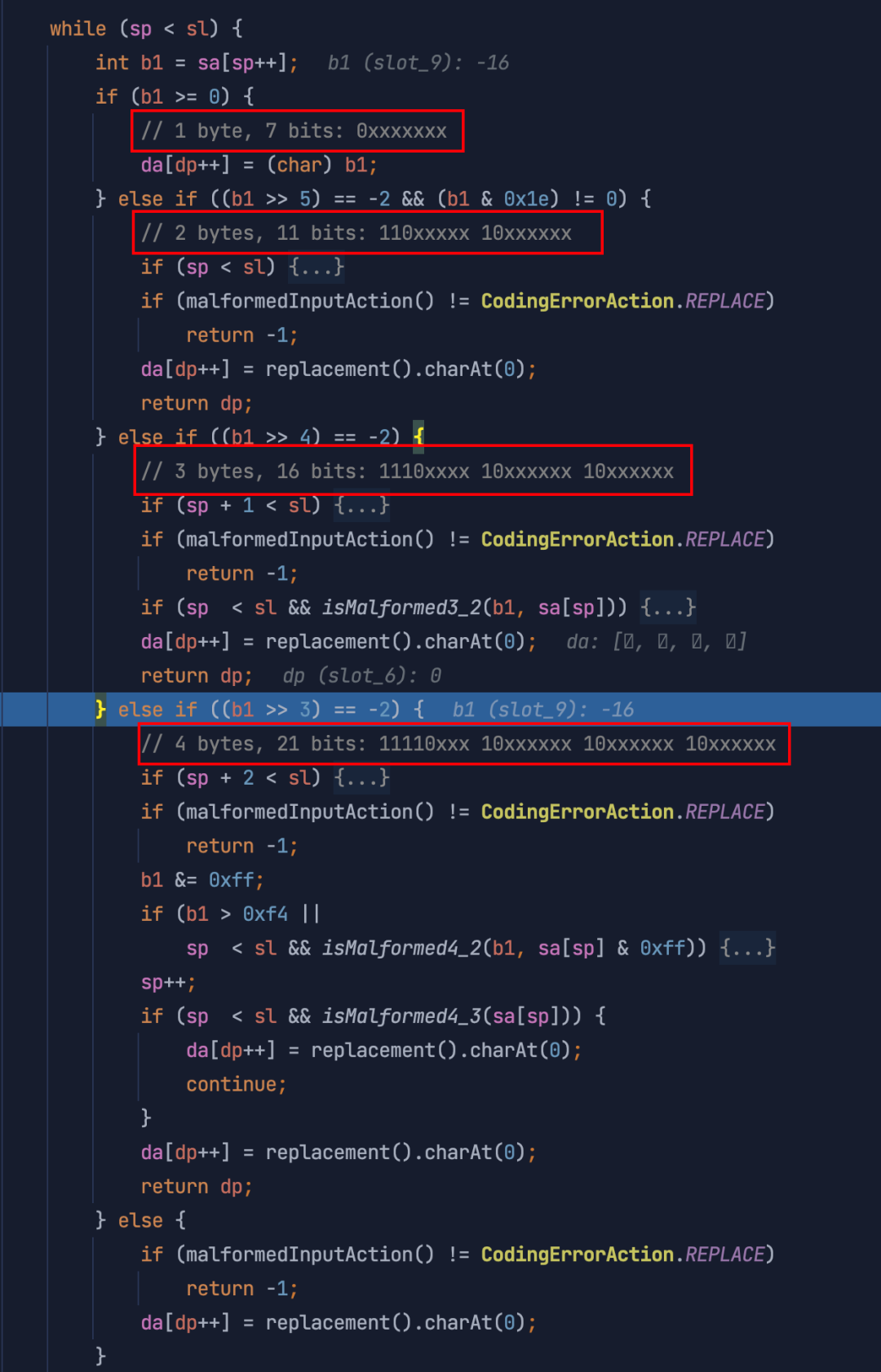
从代码中可以看到, UTF-8 的解码过程,按照一个byte、两个byte、三个byte、四个byte 分别去计算,此计算方式与「 字符串编码 」中讲到的映射关系一致。到此,基本了解 byte 数组 到 String 的过程。也可以清晰的理解到,在创建 String 的过程中,传过来的 byte 数组 就是对应编码的二进制数据。
重点来了,如果传过来的 byte 数组 中的编码并不是按照 UTF-8 编码规则来的数组,会是什么样的结果呢?我也做了一个测试,测试代码如下:
byte[] data = new byte[]{(byte) 0b10011111, (byte) 0b10001110, (byte) 0b10000011};
String createStr = new String(data);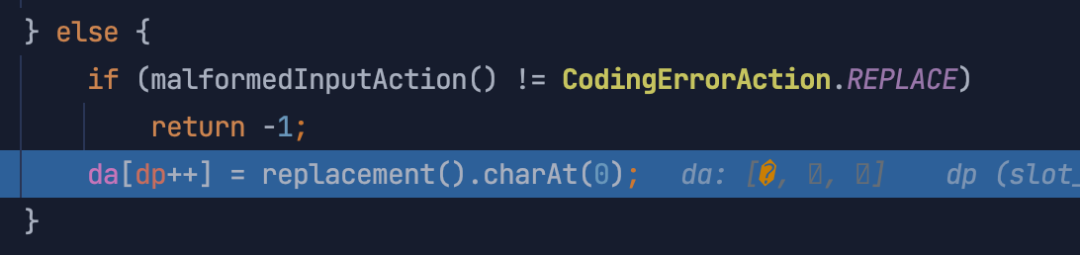
代码中,第一个 byte 为 0b10011111 ,这个数不满足前面的判断规则, 会直接进入 else 中,就将直接将当前字符设置成 65533 这个字符,从而丢掉了真实的 byte 数据。当然,除了第一个 byte 有问题,其它 byte 有问题时,也会使用 65533 来进行替换,有兴趣的同学可以去尝试看看对应的代码。
最后,在回到文章开始的那个问题,byte 数组 在创建 String 时,如果 byte 中的数据不符合 UTF-8 的规则,原始数据会被丢掉,也就导致 new String(data) 中传入的 data 与 getBytes() 拿到的二进制不一致,因此,在处理 byte 数组 数据时,需要先进行 Base64 编码处理。
总结
初入计算机行业时,也曾被各种不同的编码格式搞得头大,但也从未去了解过其底层设计原理。本文以 UTF-8 以及 Java 内部 String 处理的机制着手,对计算机中编解码的细节作了一定的了解,希望给读者朋友们带来一定的启发,如果有什么新奇的想法,也欢迎与我沟通交流。
附录:如何在 IDEA 中查看与调试 rt.jar 中的源码
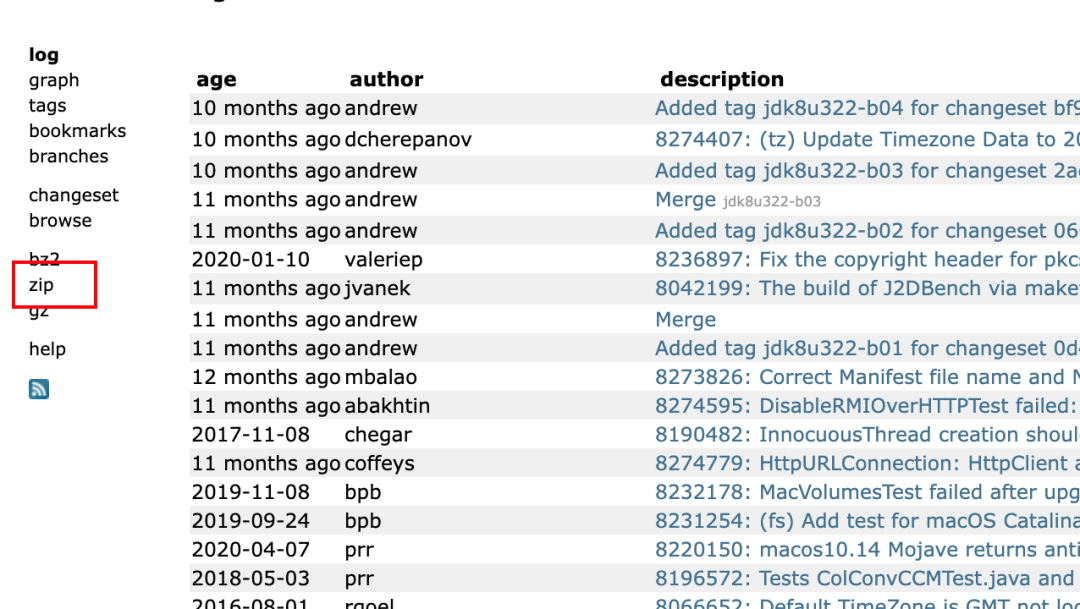
前面所提到的字符串编码,在 Java 中,用于实现编码是 Charset 相关的类, 其源代码在 rt.jar 中。JDK 中默认不包含对应的源码,在调试的时候,可以去 openjdk 中去把下载下来,我当前使用的版本为 JDK 8,下载地址为:http://hg.openjdk.java.net/jdk8u/jdk8u-dev/jdk/ , 点击下图中的 zip ,即可下载。
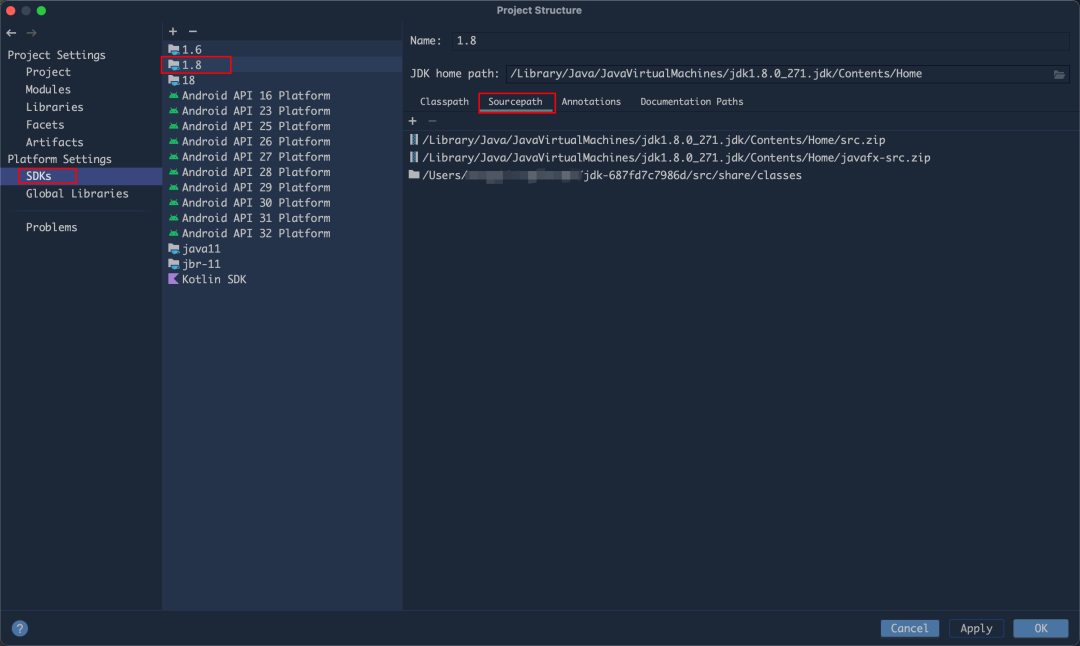
下载完成后,在 Intellij IDEA 中为 JDK 添加 sourcepath 后,就可以非常愉快的调试看代码了,具体设置步骤可以看下图红框圈出来的部分。















 259
259











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









