







养成习惯,先赞后看!!!
1.前言
UP之前都是在自己的阿里云服务器和腾讯云服务器上测试的ES,之前的关于ES以及Kibana的操作都是可以正常的执行的,但是这次在配置ES集群的时候问题却是一直有问题.虽然两者的ES都能够正常启动,但是双方节点都显示找不到对方节点,一直处于ping对方节点的状态.并且由于双方节点都处于这种状态,导致两台服务器的Kibana都无法正常连接到相应的ES,导致后续的操作都无法正常执行.

在请教了我们技术主管之后,说是具体原因可能是由于不在同一个局域网里面的原因,或者因为是在广域网的原因,建议先尝试在本机的VMware上开两个虚拟机先测试一下,看看在本机内是否能够正常启动,如果正常启动的话,后面再分析是不是因为阿里云与腾讯云之间通讯障碍的原因.
于是我今天就先尝试在本机上测试一下,看看是不是我之前配置的问题,在本机测试之后发现,本机上面ES的集群是能够正常配置以及启动的:
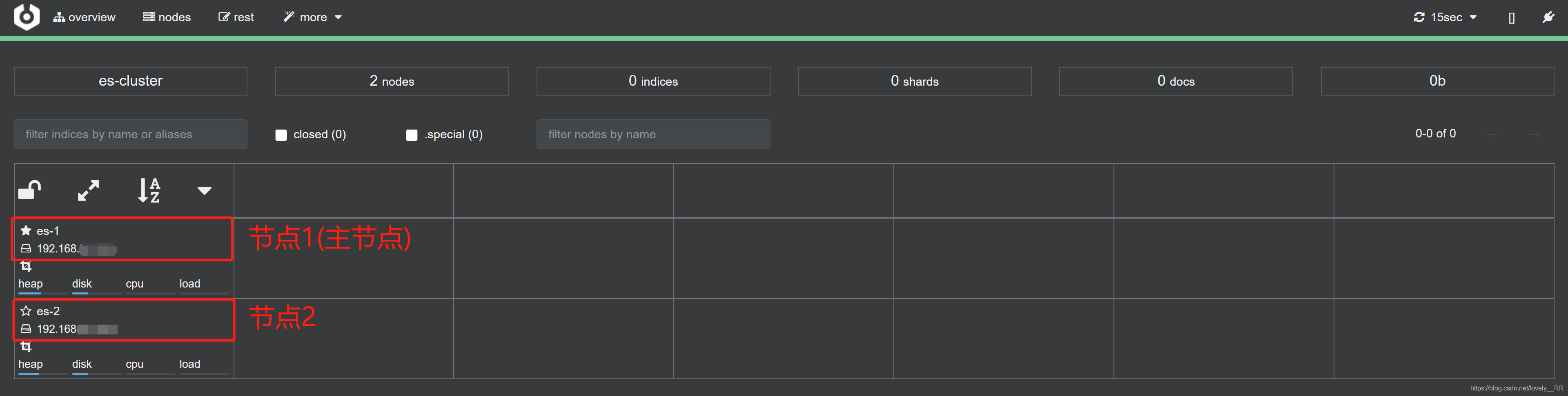
所以原因基本可以锁定在了就是阿里云服务器和腾讯云服务器之间通讯的问题,这个之后再说.
其次讲一下本片文章主要有下面几个内容:
- 了解一下RS集群中的一些基本概念
- ES是如何搭建集群的并且是如何设置开机自启动的
- ES集群工作的主要原理是什么,这里我会拿ES集群和Mysql集群对比,这样能够更好的理解ES集群为什么这么做
2.集群的基本概念
了解完ES集群如何配置之后,我们就需要顺便了解一下集群中的一些概念,这些概念其实之前就已经提到了,但是我们都没有深入的讲解,今天我们刚好再细致的讲解一下.
集群
集群就是由两个及以上节点构成的一个节点群,在集群中只会有一个主节点,其他的节点都是听从主节点的安排,并且所有的节点一起来存储ES的数据,并且这些数据都是分散的存储在这些节点之中.节点
节点就是安装了ES的虚拟机,每个节点都能够存储数据.节点分为主节点以及从节点,主节点控制所有的从节点,并且索引
索引这个概念我们之前就已经讲过了,在ES中的索引就相当于数据库的概念.但是呢这个又不完全一样.因为在ES中的索引只是一个单纯的逻辑存储单位,并不是真正的物理存储单位,真正的物理存储单位就是我们下面要说的一个概念即分片.分片
分片这个概念我们之前就已经讲过了,我们所有的数据都是存储在分片里面的,这里我们就需要和上面的索引联合起来讲一下了.一般的我们是先创建索引也就是我们的index,创建完索引之后,我们就会往索引里面添加数据,这时候这些数据就是存储在分片里面的,并且添加的数据可能是存储在多个分片里面.这就使得索引和分片的关系入下图所示:
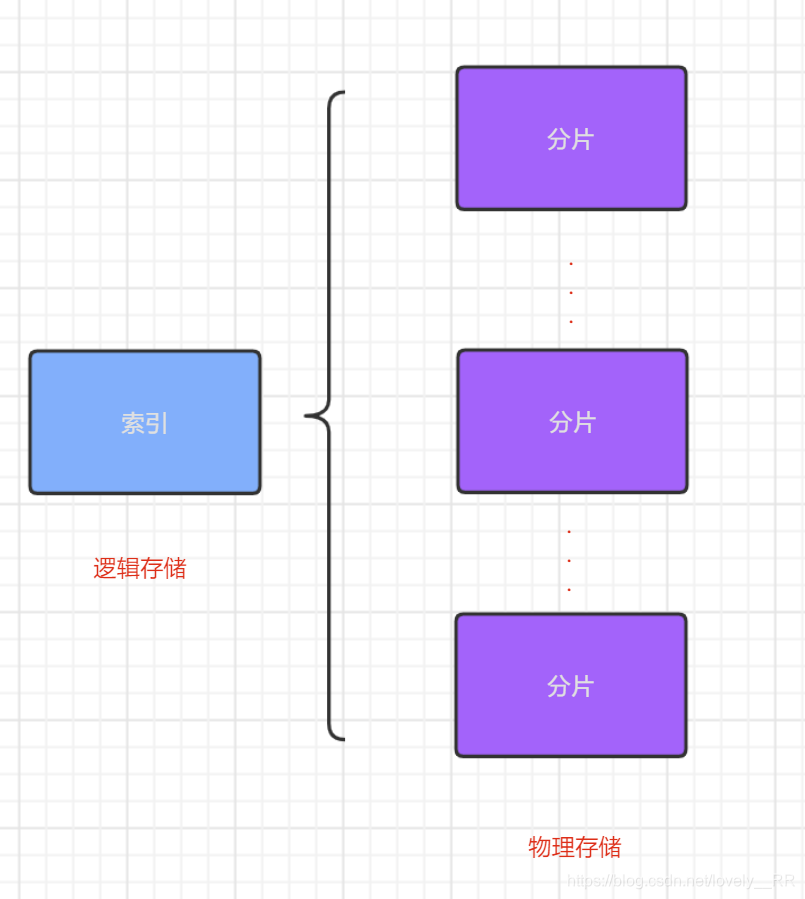
副本
最后我们需要了解一下副本的概念.其实大家看到就知道是什么意思.在ES集群里面,他是 默认会给每个分片在除该分片所在的节点以外的其它的节点上面创建该分片的一个副本.但是并不是所有其它的节点都会创建副本,ES集群默认的是在其它的3个节点上创建副本. 这样做既能保证数据的容错性,又能够有效的降低数据的存储压力,如果其它节点都创建该分片的副本的话,虽然容错性更够进一步的提高,但是每个节点的存储的数据就会大幅度增加.
3.如何搭建ES集群
如何不会VMware安装虚拟机的小伙伴,可以看我的这片博客: VMware中如何安装虚拟机 并且软件以及linux系统我都已经通过百度网盘链接的方式分享出来了
ES集群的搭建非常的简单,只需要简单配置一下config目录下的elasticsearch.yml文件即可.
这里主要就是配置一下的信息:
#集群的名称
cluster.name: es-cluster
#节点的名称
node.name: es-1
#是否是主节点
node.master: true
#是否是数据节点
node.data: true
#数据存储的目录
path.data: /opt/es/data
#日志存储的目录
path.logs: /opt/es/logs
#本机的ip
network.host: 本机ip
#es对方访问的端口号
http.port: 9200
#es集群内部通信的端口号
transport.tcp.port: 9300
集群中其他机器的IP地址
discovery.zen.ping.unicast.hosts: ["IP地址"]
#避免脑裂,设置集群中能够作为主节点机器的最小个数
discovery.zen.minimum_master_nodes: 2
稍微了解了这些之后,我们再来详细讲解一下他们的概念.
-
cluster.name: es-cluster
这个主要就是定义我们ES集群的名字,并且这个名称必须要统一,否则无法当成是同一个集群 -
node.name: es-1
这个就是节点的名称,每个节点的名称必须不一样,否则无法分辨各个节点 -
node.master: true
定义该节点是否可以成为主节点,一般每个节点都添加这段代码,因为我们这里定义之后,该节点不一定就是主节点,主节点是在启动之后集群自己从所有的主节点组里面挑选一个最为适合的节点为主节点. -
node.data: true
定义该节点是否需要存储数据,这个要看具体的情况,一般公司就是直接ES和存储服务器是同一台,那么就需要设置,如果是ES服务器和存储服务器是不在同一台的,那么就可以不添加,具体看自己的需求. -
path.data: /opt/es/data
这个大家看名字就能看出来就是定义ES数据的存储目录 -
path.logs: /opt/es/logs
这个大家看名字也能看出来就是定义ES日志的存储目录 -
network.host: 本机ip
这个定义的就是我们的ES最后是通过哪个IP访问 -
http.port: 9200
这个定义的就是我们的ES最后是通过哪个端口访问,这个主要指的是我们在浏览器中如何访问ES的端口 -
transport.tcp.port: 9300
这个定义的则是ES集群内部各个节点之间通讯的端口号 -
discovery.zen.ping.unicast.hosts: ["IP地址"]
这个就类似于我们的通讯录,主要就是将集群中除当前节点的ip外,填写其他节点的ip,这样每个节点才能知道其他节点的信息. -
discovery.zen.minimum_master_nodes: 2
在了解这个属性之前,我们需要先了解一下脑裂这个概念.从字面意思来理解就是脑子分裂了,从原来的一个脑子分裂成了两个及以上的脑子.一般情况下集群是能够正常工作的,但是大家知道,世界上就是存在很多不正常的情况.
如果集群正常工作的话,那么工作的流程应该是这样的:
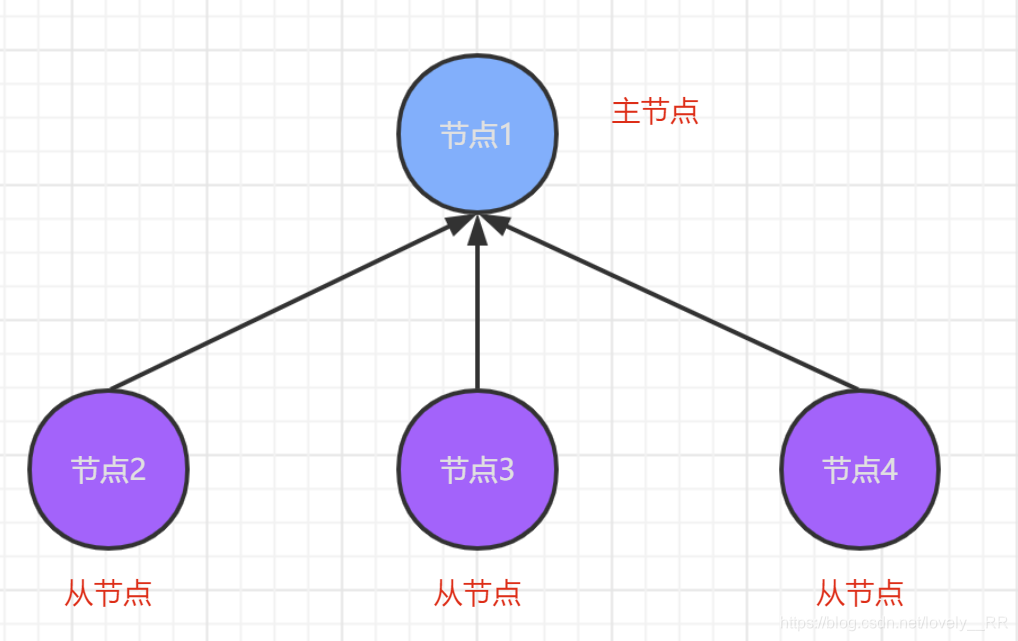
但是假设由于网络或者其他的一些原因导致节点3与节点4与主节点的通信断掉了,就会变成下面这个样子:
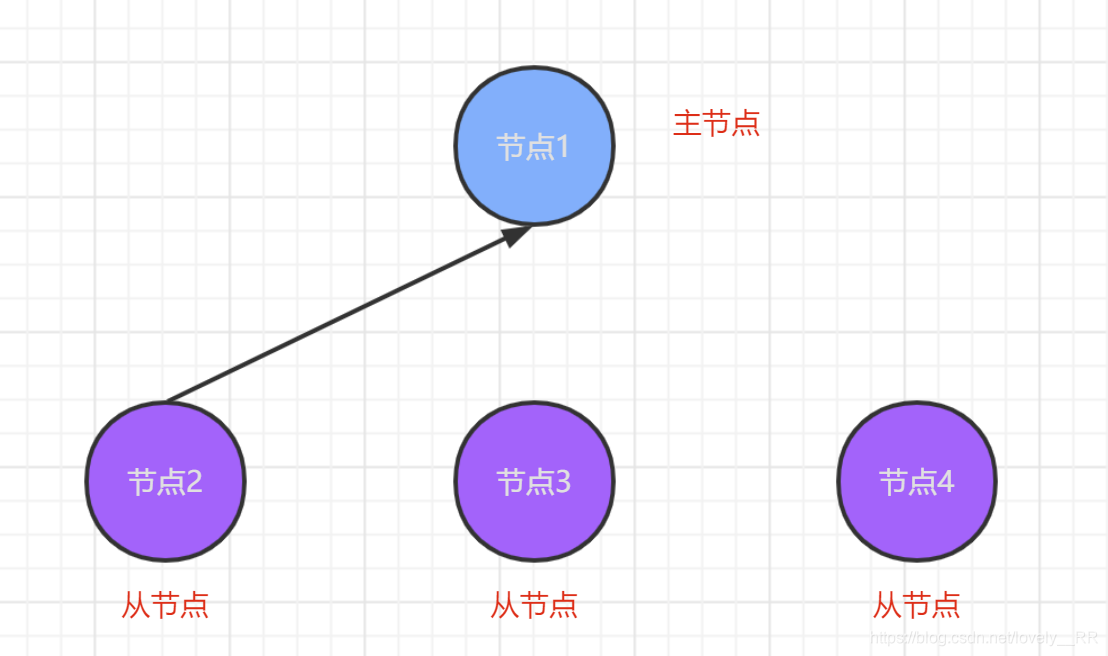
在这种情况下,节点3和节点4就会理所应当的认为是主节点挂掉了,那么这时候他们就会从他们俩中再选出一个主节点,就会出现下面的情况:
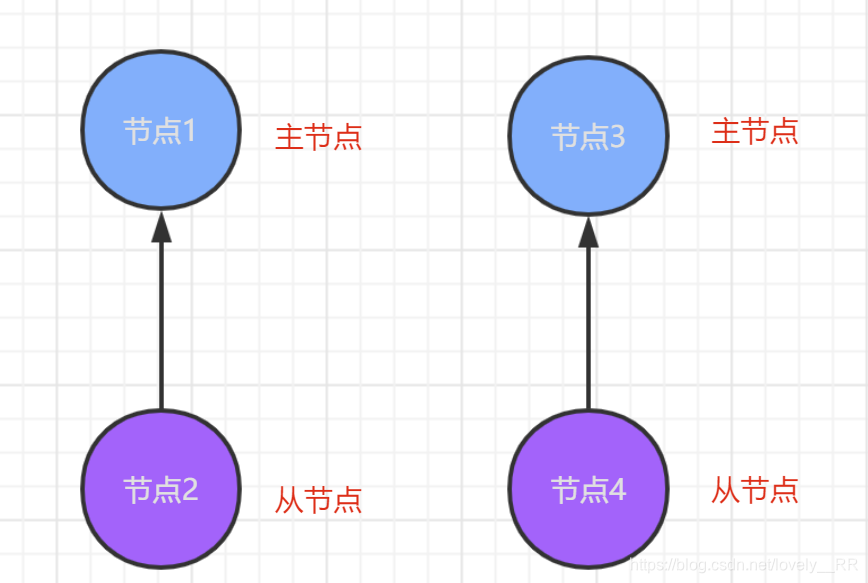
这样集群中就会出现两个主节点,并且每个主节点还都认为没有其他主节点.自己和自己的从节点玩.不仅是内部,外部肯定也是不知道的,这就会导致下面这种情况:
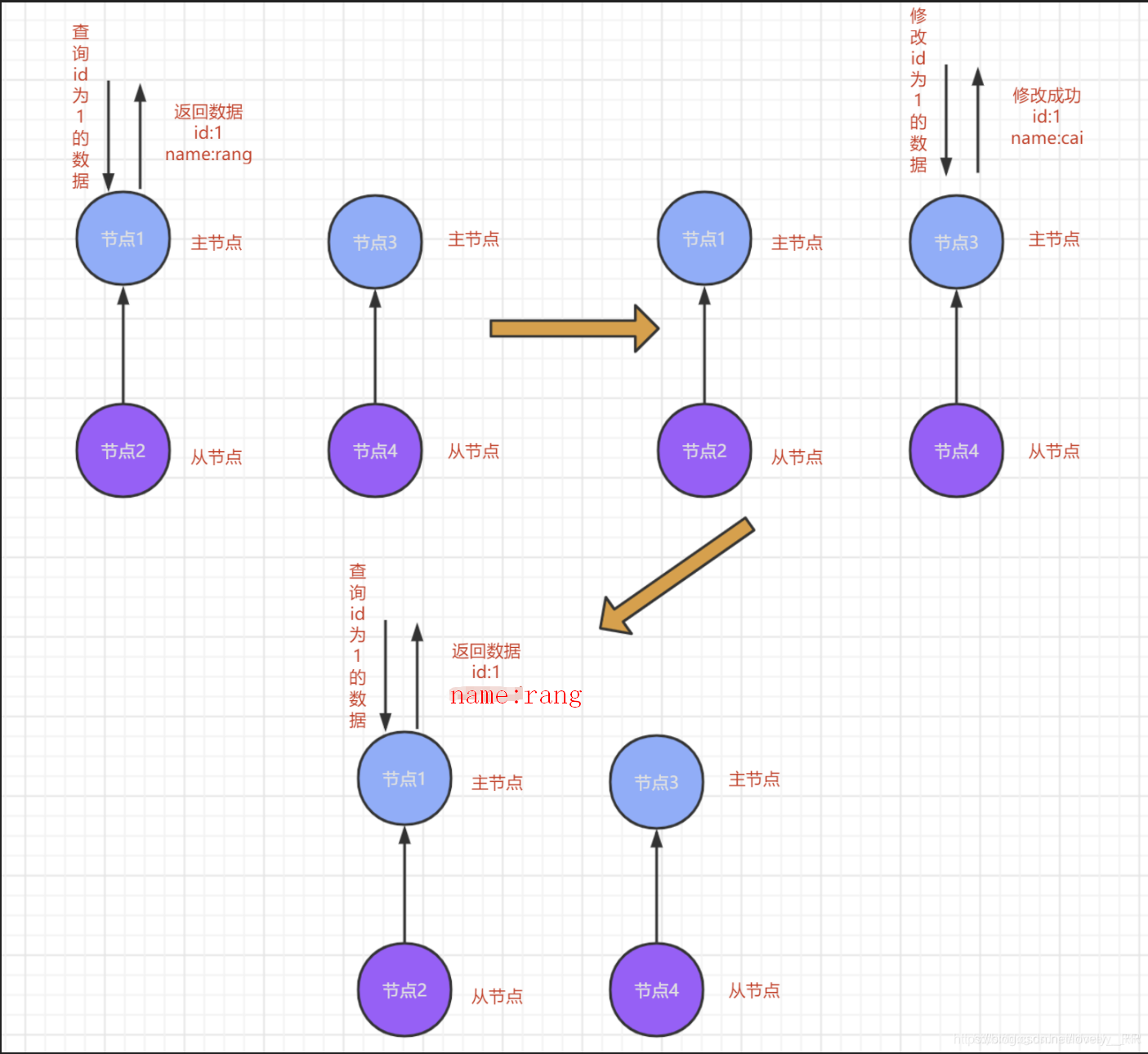
进行第一次请求的时候被分发到节点1,因为此时ES集群内部认为节点1是主节点,所以就在节点1处进行了操作.当二次请求到达时,ES集群又将节点3认为是主节点于是就是节点3处进行了修改操作.
关键是如果刚好这时第三次请求到达后刚好ES集群又将节点1当成是主节点,那么这样就歇逼了,可以看到
数据是没有发生改变的.所以就这就脑裂之后会产生的问题.客户端的请求可能是分发到了多个主节点上,但是主节点之间已经失去了通信,那么这样重复几次请求之后就会导致节点之间的数据不统一.所以我们就需要解决脑裂这个问题,这里我们设置的这个属性就能在极大程度上帮助我们解决这个问题,注意这里只是极大程度上,并不能完全解决这个问题.
这里我们设置的属性意思就是集群中可以设置为主节点机器的
最小数目,并且这个数目的值是这样定义的,是机器总数的半值+1.一旦ES检测到所有的节点数<这个值就说明ES集群已经发生脑裂了,就会停止服务.这里和大家举个例子来说明一下,大家就能理解了.这里我们还是拿上面的例子来讲解:
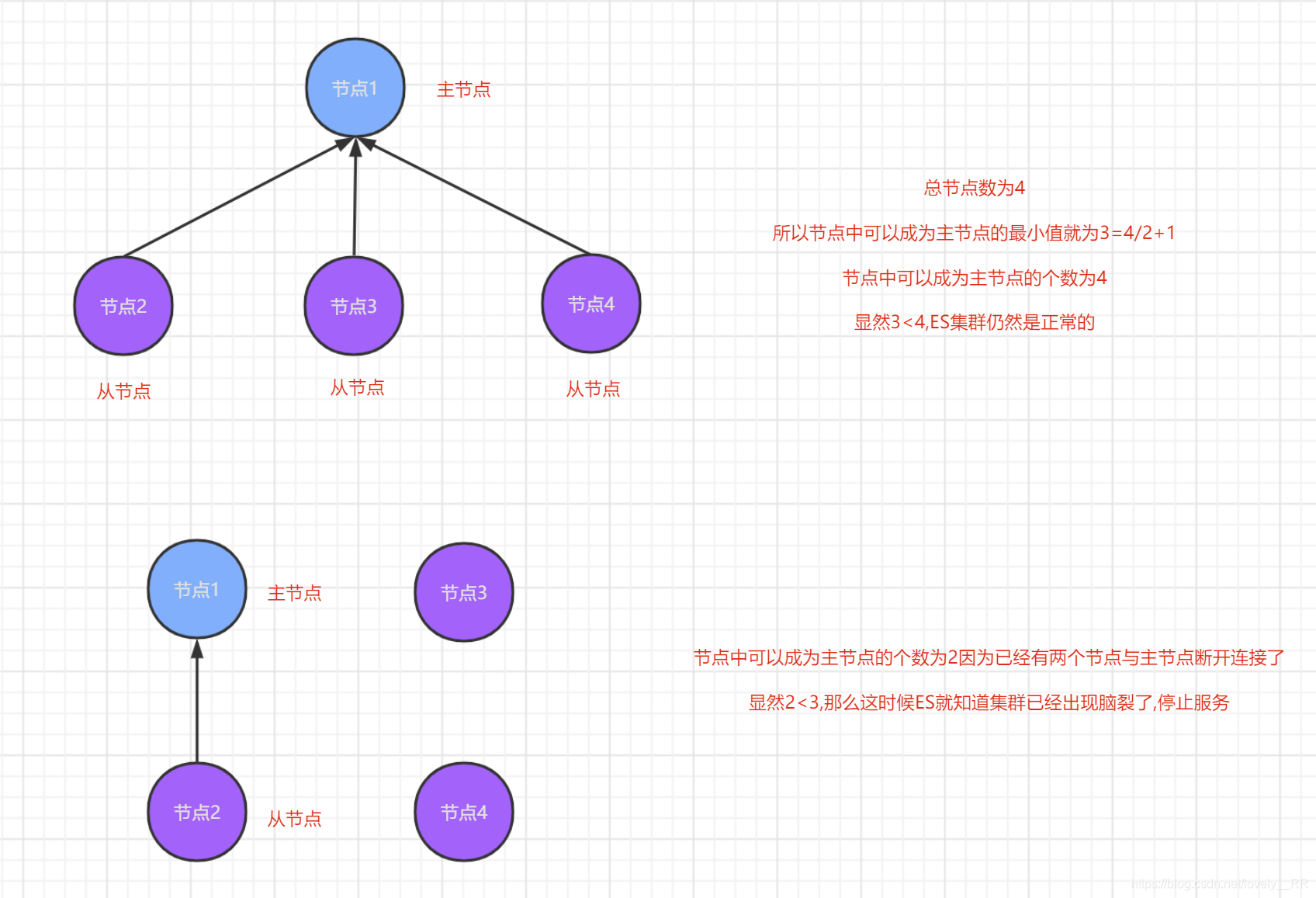
上面的例子就已经很好的讲解了这个过程.
讲解完上面属性的概念之后,这时候我们就来实际操作一下,分别给两台机器配置一下ES集群的配置.
这里我选择的是直接Clone我的另一台机器,大家可以选择直接配置两台虚拟机,也可以像我这样值配置一台虚拟机,另一台机器直接通过Clone这一台机器即可.
Clone的过程如下:
- 给虚拟机创建快照

-
通过快照来Clone虚拟机

-
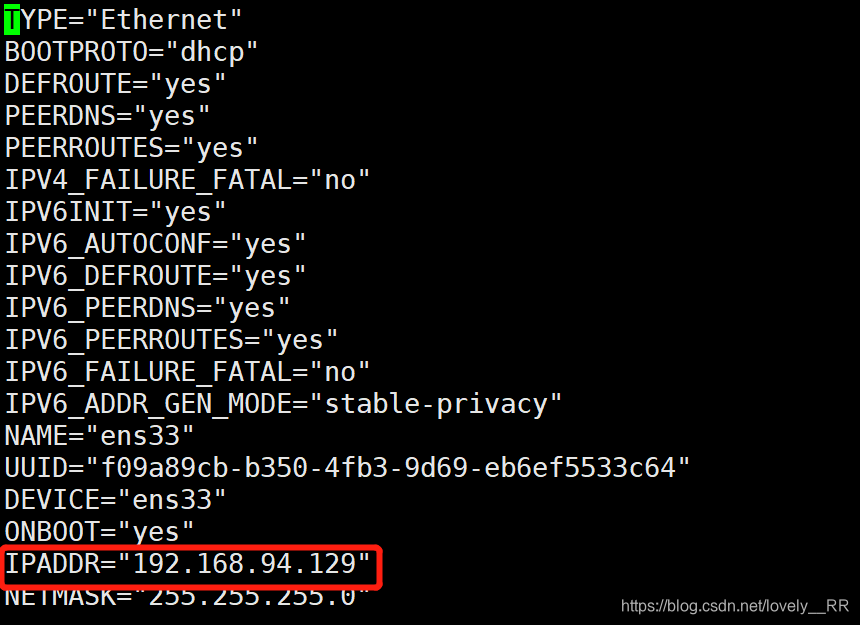
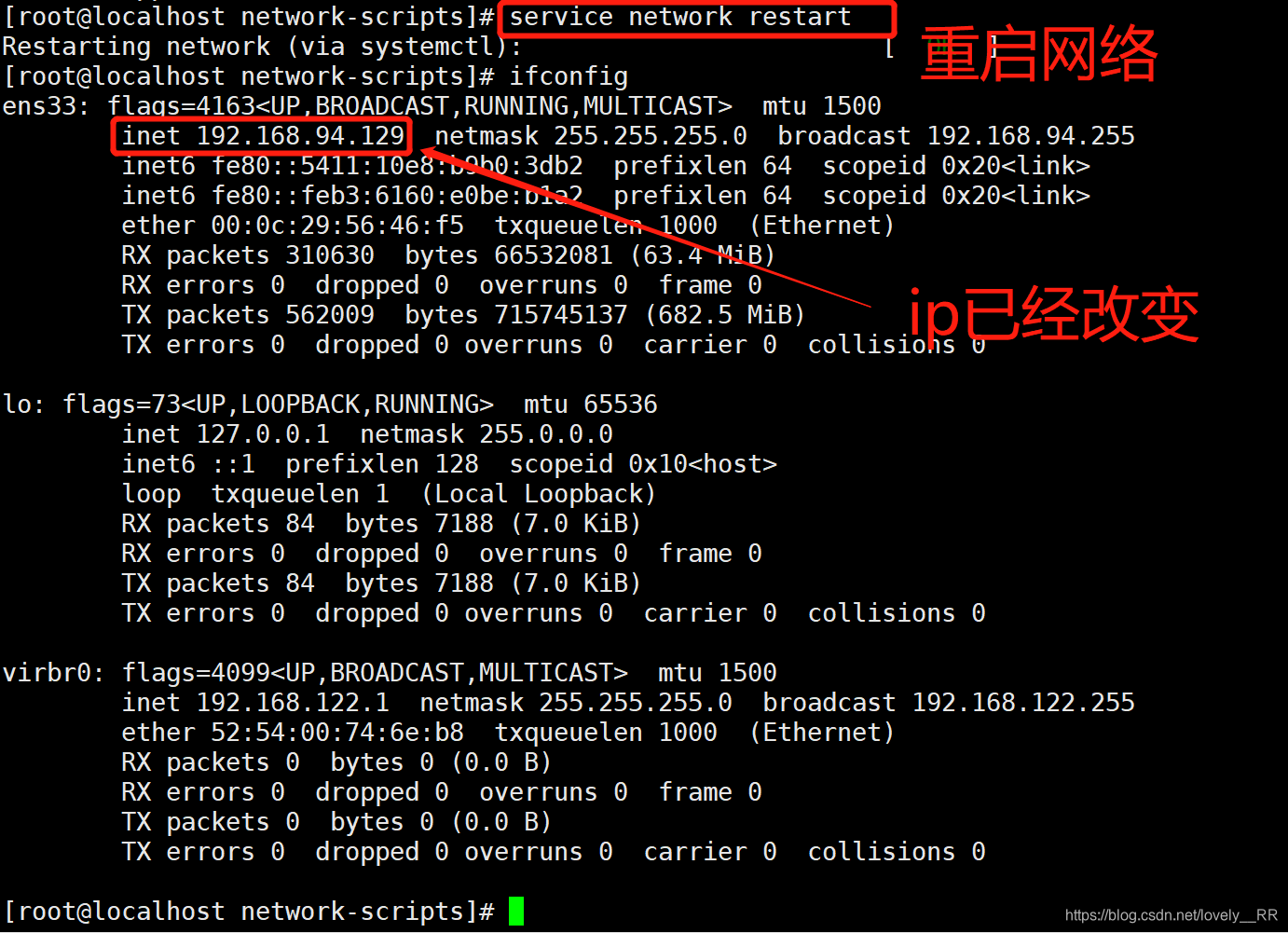
修改Clone机器的ip并重启网络
因为我们是Clone的,所以两台机器的IP地址是一样的,所以我们需要修改

然后修改IPADDR这个参数即可
重启网络
之后我们就只需要分别取配置一下我们两台虚拟机中ES的elasticsearch.yml文件即可.
192.168.94.128:

192.168.94.129:

这里面还有一个主意点就是需要 打开我们刚才创建的数据以及日志目录的权限,否则是不能用的
切换到root用户执行下面的命令即可:
chmod 777 /opt/es/data #这个目录需要匹配你自己定义的数据目录
chmod 777 /opt/es/logs #这个目录需要匹配你自己定义的日志目录
之后我们重新启动我们的ES即可.
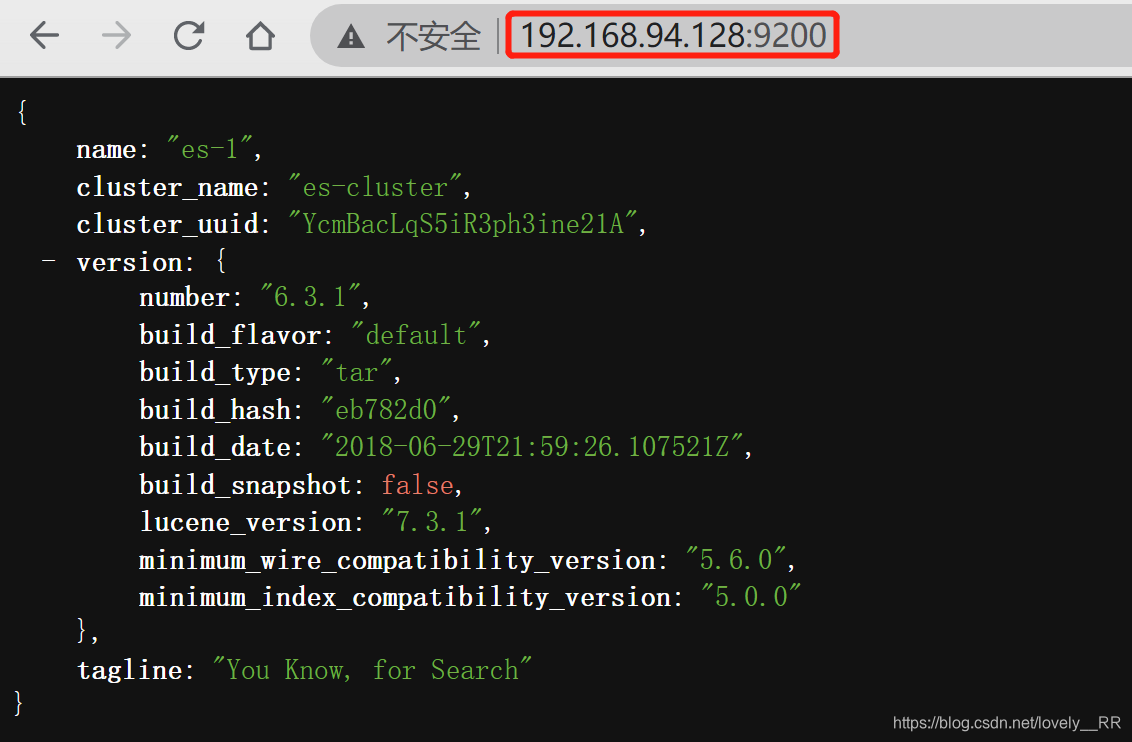
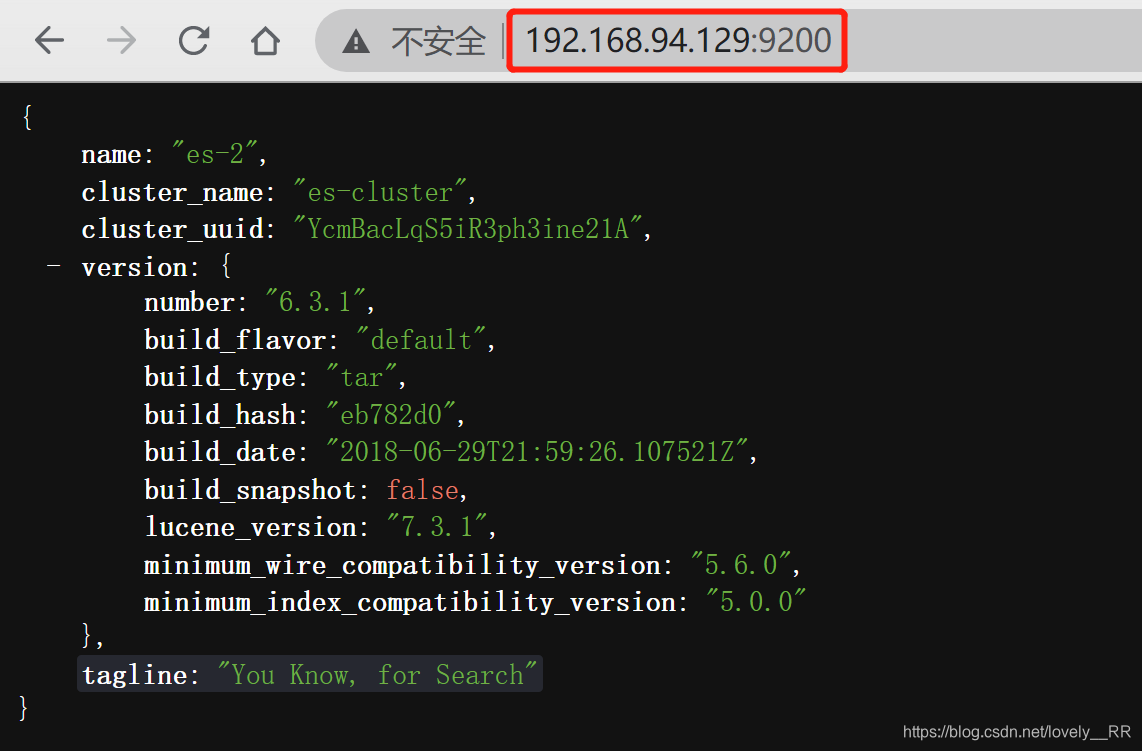
两台机器的ES都已经成功启动,但是这不能证明这两台机器就真的就已经在一个集群里面了,这时候我们还需要通过一个管理ES节点的工具Cerebro来检测,这个东西能帮助我们检查节点是否真的已经在一个集群里面了.软件我也分享出来
链接:https://pan.baidu.com/s/1QdQrcD19EfHm6esLWXYzJw
提取码:qilh
下载之后解压,以管理员身份运行该文件即可.

运行完成之后我们便可以看到这样一个界面:

之后我们访问该地址:http://localhost:9000/
之后填写我们的ES地址就可以管理我们的ES集群了:
可以看到的确已经构成了集群,并且es-1即为我们的主节点.
4.ES设置开机自启动
因为这里我这里并不是在云服务器上面搭建的ES集群,所以每次都需要我自己打开虚拟机之后自己手动开启elasticSearch,试了几天之后发现,这样太烦了,还是配置一下elasticSearch的开机自启动吧.
设置开机自启动的步骤之前我们在讲分布式文件系统的时候就已经讲过了,主要就是下面这几个步骤:
编写开机自启动脚本
我们在/etc/init.d目录下面添加elasticSearch的开机脚本
cd /etc/init.d
vi elasticsearch
之后粘贴这段脚本即可,但是要 注意下面我注释标注的三个地方!!!!!
#chkconfig: 345 63 37
#description: elasticsearch
#processname: elasticsearch-6.3.1
#这里需要填写你自己ES的安装目录,不一样的话记得修改
export ES_HOME=/opt/es/elasticsearch-6.3.1
case $1 in
start)
#这里的用户需要填写你自己的ES启动用户,不是es的话,需要修改
su es<<!
cd $ES_HOME
./bin/elasticsearch -d -p pid
exit
!
echo "elasticsearch is started"
;;
stop)
pid=`cat $ES_HOME/pid`
kill -9 $pid
echo "elasticsearch is stopped"
;;
restart)
pid=`cat $ES_HOME/pid`
kill -9 $pid
echo "elasticsearch is stopped"
sleep 1
#这里的用户需要填写你自己的ES启动用户,不是es的话,需要修改
su es<<!
cd $ES_HOME
./bin/elasticsearch -d -p pid
exit
!
echo "elasticsearch is started"
;;
*)
echo "start|stop|restart"
;;
esac
exit 0
赋予开机脚本权限
保存退出之后,我们需要输入下面的命令:
chmod 777 elasticsearch
添加到开机服务里面同时开启开机自启
chkconfig --add elasticsearch
chkconfig elasticsearch on
这样我们关于ES的开机自启动就已经完成了.不仅如此,我们还可以直接通过下面的命令启动,重启,关闭es服务
#启动es服务
service elasticsearch start
#关闭es服务
service elasticsearch stop
#重启es服务
service elasticsearch restart
5.ES集群工作原理(对比Mysql集群)
在说ES集群的工作原理之前,我们先来了解一下Mysql集群的工作原理.
Mysql集群的工作原理主要就是 主从复制,意思就是主数据库发生改变,从数据库就会想应该的发生改变.并且当主数据库崩溃之后会由从数据库代替主数据库,继续承担责任.
可以看到Mysql的解决方案主要就是采用了复制的概念,但是这有几个问题,一旦几台机器出了问题,那么很显然就是直接几台机器的数据完全就没了,导致后续所有数据的并发量全部都打到剩下的机器上.如下图所示:
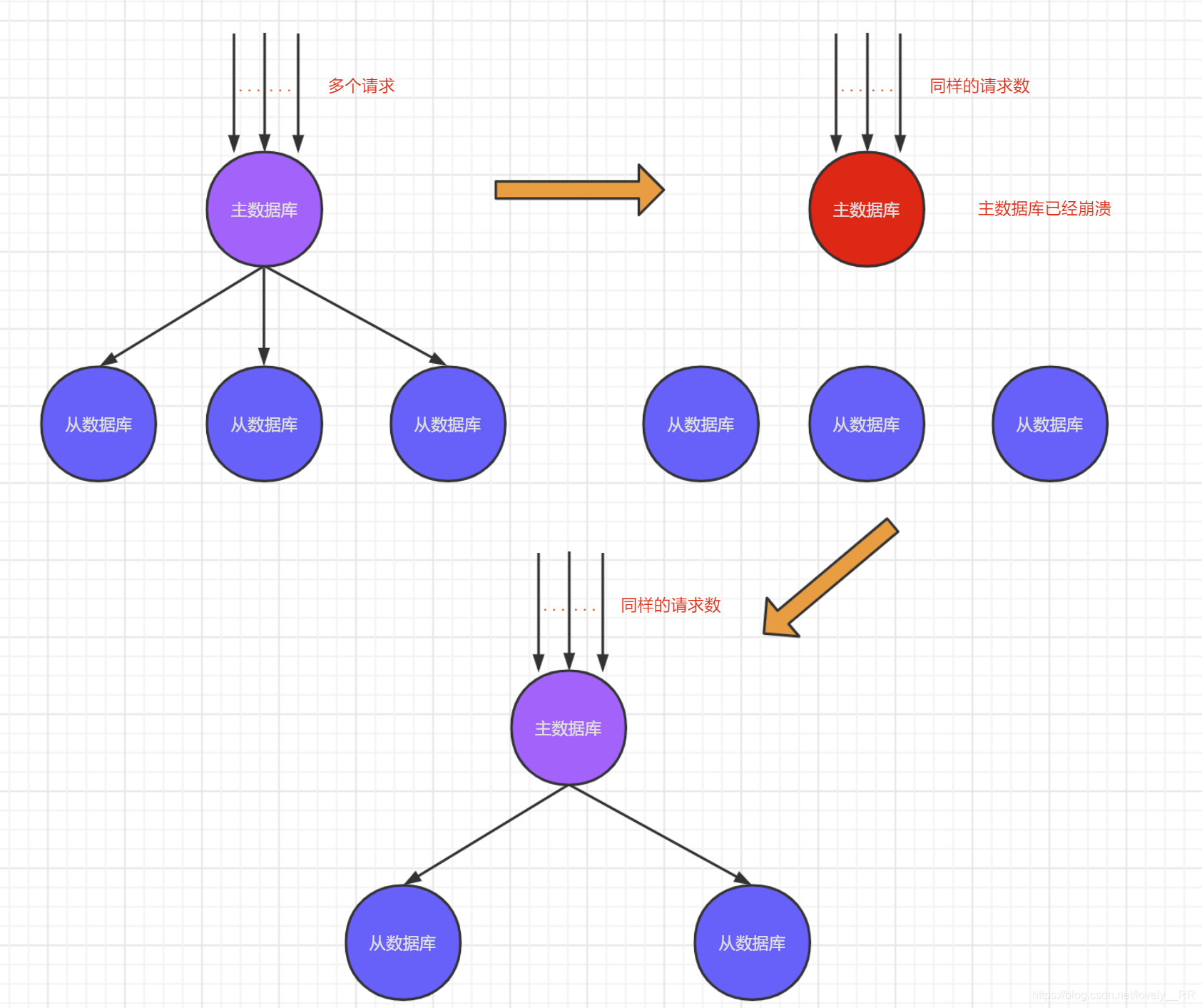
性能肯定会有所降低.
其次就是可能还有一种情况就是在其它几台主数据库崩溃之前正在执行多次的查询,修改的操作,假设刚好这些操作从数据库还没有执行完毕即复制过程还没有结束,主数据库就突然崩溃了,那么很显然这部分的数据就没有同步号,那么很显然之后的数据就会产生差异,就如下图所示:
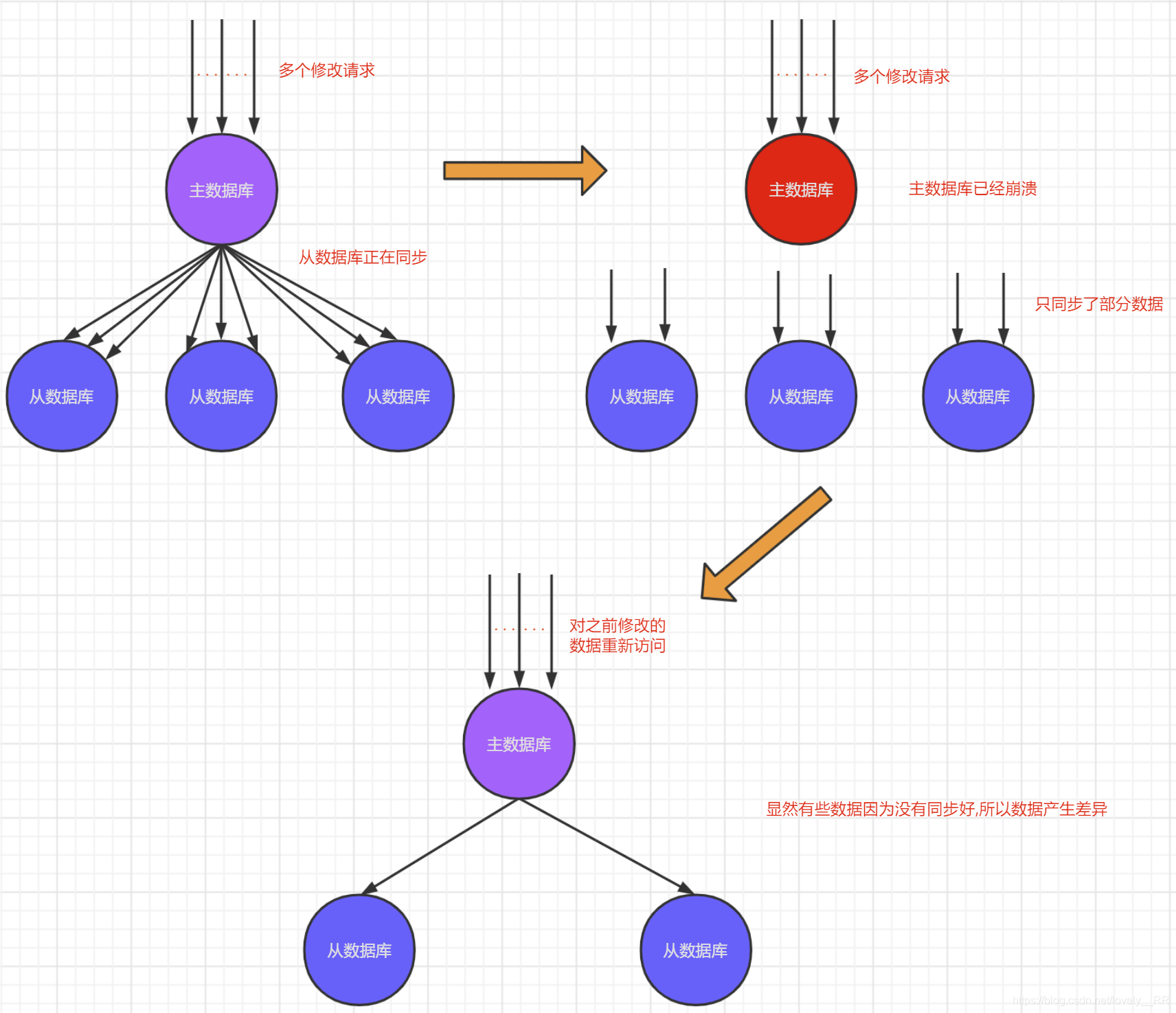
这个主要就是造成了 数据的不统一.
既然这样,我们再来看看ES集群是怎么做的?
ES集群所采用的的方案则是这样的 分片+复制,
其实分片+复制的概念我们已经在上面分片+副本的集群基本概念里面讲过了.
主要就是ES集群并不像Mysql集群一样一开始就是将数据存储在一台服务器上的,相反的他是将所有的数据存储在多个分片上,并且这些分片是分散的存储在所有的节点上面的.
并且他的复制过程就和我们上面所说的副本的概念是一样的.他并不像Mysql集群一样,所有从数据库都需要与主数据库进行通信,每台从数据库都需要复制主数据库的数据.ES集群则是这样,只需要每个分片与他的副本之间进行复制即可.
正是因为上述两点原因使得 ES的数据容错性非常高 ,注意虽然是非常高,但是仍然还是会出现瘫痪的.
到这里,本文所有讲解的内容就都已经讲完了,原创不易,码字不易!!
如果觉得文章质量可以或者对你有帮助的话,可以关注我的公众号,新人up需要你的支持!!!

不点在看,你也好看!
点点在看,你更好看!














 9680
9680











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









