







在文本挖掘和自然语言处理方面,tf-idf是非常重要也非常常用的算法。
tf:词频,是指某个词在某篇文章中出现的频率。比如,某篇文章共1000个词汇,其中hello出现5次,那么其tf=5/1000。tf最直观的理解就是,当一个词在本文中出现的频率越高,则这篇文章的主题和这个词的相关可能性越大。
这种直观理解是否准确呢?可以说相当不准确。举例来说,一篇文章中出现最多的字词可能是你、我、他、的、是、这、那等等。通过这些词来分析一篇文章的内涵几乎是不可能的。所以人们又做了进一步处理。就是把这些在每篇文章里都可能大量出现又和文章意义关联不大的词都去掉。这类词也有了一个专有名称:停用词。所以文本处理的前几步通常都包括这一步:去停用词,既能减少词汇处理量,又能有效减少歧义。属于重要的预处理步骤。
去掉停用词之后的词频是否就能比较准确的表达文章含义了呢?还是不够的。设想一下,如果一篇文章是描述一份国内专利的。文章里反复提到了“中国”两个字。中国这、中国那,结果中国这个词的词频最高,那么这个词和实际要说的专利有多大关联呢?基本没有。但是我们又不能把中国加到停用词里,否则停用词列表就太多了,而且去掉也不合理,万一某篇文章就是介绍中国的呢。这个时候就又发明另外一个算法:idf。
idf叫做反文档频率:目的就是针对刚才说的这种情况进行识别。还以上面为例,这篇文章中“中国”这个词的词频最高,却不能反应真实的文章内涵,这是为什么呢?很大程度是因为“中国”这个词太常见了,不仅在这篇文章里出现次数多,在其他文章里出现的次数也很多。这么一来,说明这个词不足以描述文章“特征”。于是评价某个词的“独特性”的公式idf就这样设计出来:语料库文章总数/包含某个词的文章数。意味着,如果一个词在越多的文章中出现过,那么其“独特性”就越低。出现的文章数越少,idf值越大,其独特性越高。整体思路就是这样,后续再加上一点数学上的处理:如果一个词在所有语料库的文章中都没出现过。那么分母就是0了,这在计算中会发生错误,所以往往把分母+1,保证其至少不会是0。虽然缺失了一点点精确性,但保证计算过程不至于出错。而且在语料库文章数量很大时,对结果的影响是微乎其微的。另外,这个除法除出来的结果可能差别很大,有的接近1(几乎每篇文章都出现这个词)、有的非常大(极少出现),这时候看起来值的差距太悬殊,不易计算也不易比较。于是再取一下对数。所以整个公式就是:
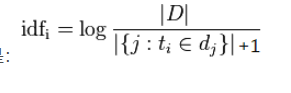
最后,再把tf和idf相乘,这个得出来的值就很能反映文章的主题了。举个例子,现有文章库100万篇。当对一篇新来的文章进行分析时,发现其tf排名第一的是“中国”,30/1000(假定去掉停用词之后还有1000个词汇)=0.03,tf排名第二的是“青蒿素”,20/1000=0.02,再继续计算idf,发现包含“中国”的文章有10万篇,其idf=log(1000000/100000)=1;含有“青蒿素”的文章只有1000篇,其idf=log(1000000/1000)=3,最后“中国”的tf-idf值为0.03,“青蒿素”的tf-idf值为0.06。这样,如果按tf-idf值排序,尽管“中国”出现的次数多,但仍被排到“青蒿素”之后。说明这篇文章和青蒿素相关的可能性较大。当我们选取tf-idf值排名前若干的词汇作为一篇文章的主旨,可靠性就相对准确多了。
————————————————
版权声明:本文为CSDN博主「1501220038」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zjc/article/details/78772396














 2256
2256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









