







文章目录
AQE(Adaptive Query Execution,自适应查询执行)是一个运行时SQL优化框架,旨在解决由于优化器统计信息不足、不准确或过时而导致的查询执行计划的低效和缺乏灵活性的问题。
优化Shuffle
我们知道Shuffle是Spark任务中的瓶颈,但要给Spark任务分配一个合适的shuffle分区数并不容易,这是因为不同任务处理的数据量是不一样的,甚至同一个任务中不同stage所处理的数据量也是不相同的,如果使用相同的shuffle分区数就会导致小任务不能高效地利用资源,或者大任务导致过多的GC和磁盘溢出。
而现在,AQE会根据map端的shuffle输出大小,在查询的每个stage自动调整shuffle分区数的大小。这样,在不同stage处理的数据增大或减小的情况下,任务的大小依然能保持大致相同,既不会太大也不会太小。
但是,有一点需要注意的是,AQE并不会自动设置map端的分区数,这意味着,为了使AQE特性完美的启用,建议用户通过配置spark.sql.shuffle.partitions(默认分区数为200)来设置一个相对较大的初始shuffle分区数。
选择Join策略
在Spark优化器中,其中一个最重要的基于代价的决策就是对join策略的选择,这是对join操作两边表大小的估算。但是这种估算可能是不准确的,它可能会因为估算过高而导致选择的join策略的效率较低,或者估算的更低而导致内存不足的错误,例如,将broadcast join判断为Hash Shuffle join导致产生shuffle,又或者是将Sort merge join判断为broadcast join导致join的一端发送到每个节点导致撑爆内存。
AQE通过在执行时切换到更高效的broadcast join提供了一个无故障的解决方案。
处理数据倾斜
数据倾斜是一个很常见的问题,因为数据的分布不均匀,导致瓶颈和性能显著降低,尤其是对于sort merge join。整个job的耗时是由耗时最长的task决定的,而且数据倾斜的情况下,哪些倾斜的数据还可能从内存溢出到磁盘,这就进一步加剧了任务的耗时。
数据倾斜的不可预测性常常使静态优化器难以自动处理倾斜,甚至无法通过查询hint来处理。而现在,通过手机运行时统计信息,AQE可以在运行时检查倾斜的join,并将倾斜的分区拆分为更小的子分区,从而消除了倾斜对查询性能的负面影响。
AQE查询计划分析
AQE查询计划的一个主要区别是它通常会随着执行的变化而变化,它并不是一层不变的。AQE计划引入了几个特定的node,以提供关于执行的更多细节。此外,AQE使用了一种新的查询计划字符串格式,可以显示初始和最终的查询执行计划。
下面将分析AQE查询计划,并展示如何识别AQE对查询的影响。
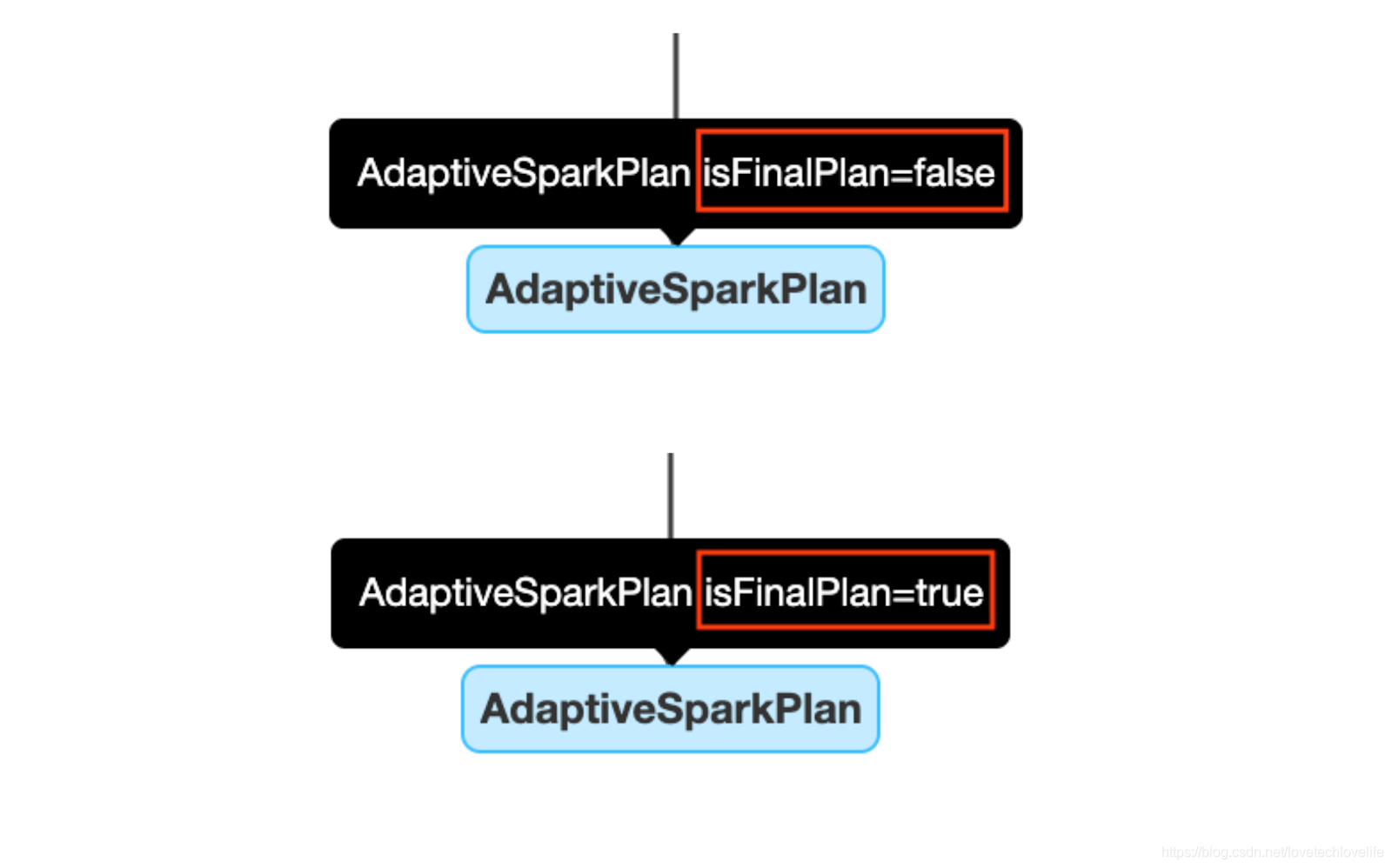
1. AdaptiveSparkPlan Node
应用了AQE的查询通常有一个或多个AdaptiveSparkPlan节点作为每个查询或子查询的根节点。在执行之前或执行期间,‘isFinalPlan’标志显示为false,查询完成后,该标志会变成true,与此同时,AdaptiveSparkPlan节点下的计划将不再改变。
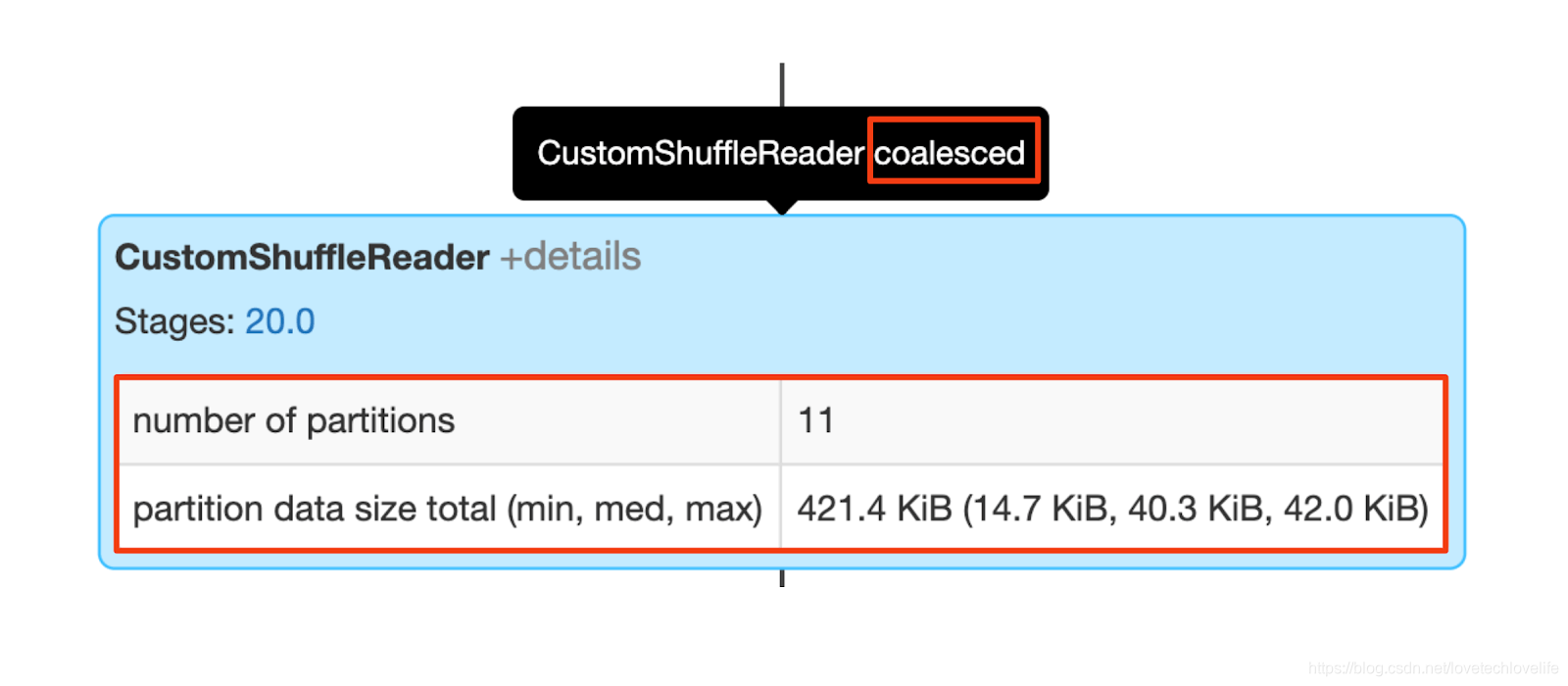
2. CustomShuffleReader Node
CustomShuffleReader节点是AQE优化的关键,它可以根据shuffle map stage阶段的统计信息动态调整shuffle分区数。在Spark WebUI中,用户可以将数据悬停在这个节点上,查看它应用在shuffle分区的优化。
当CustomShuffleReader的标志位"coalesced"时,这意味着AQE已经根据目标分区的大小检测并合并了shuffle后的小分区。
该节点的相信信息展示了合并后的shuffle分区数和分区大小。
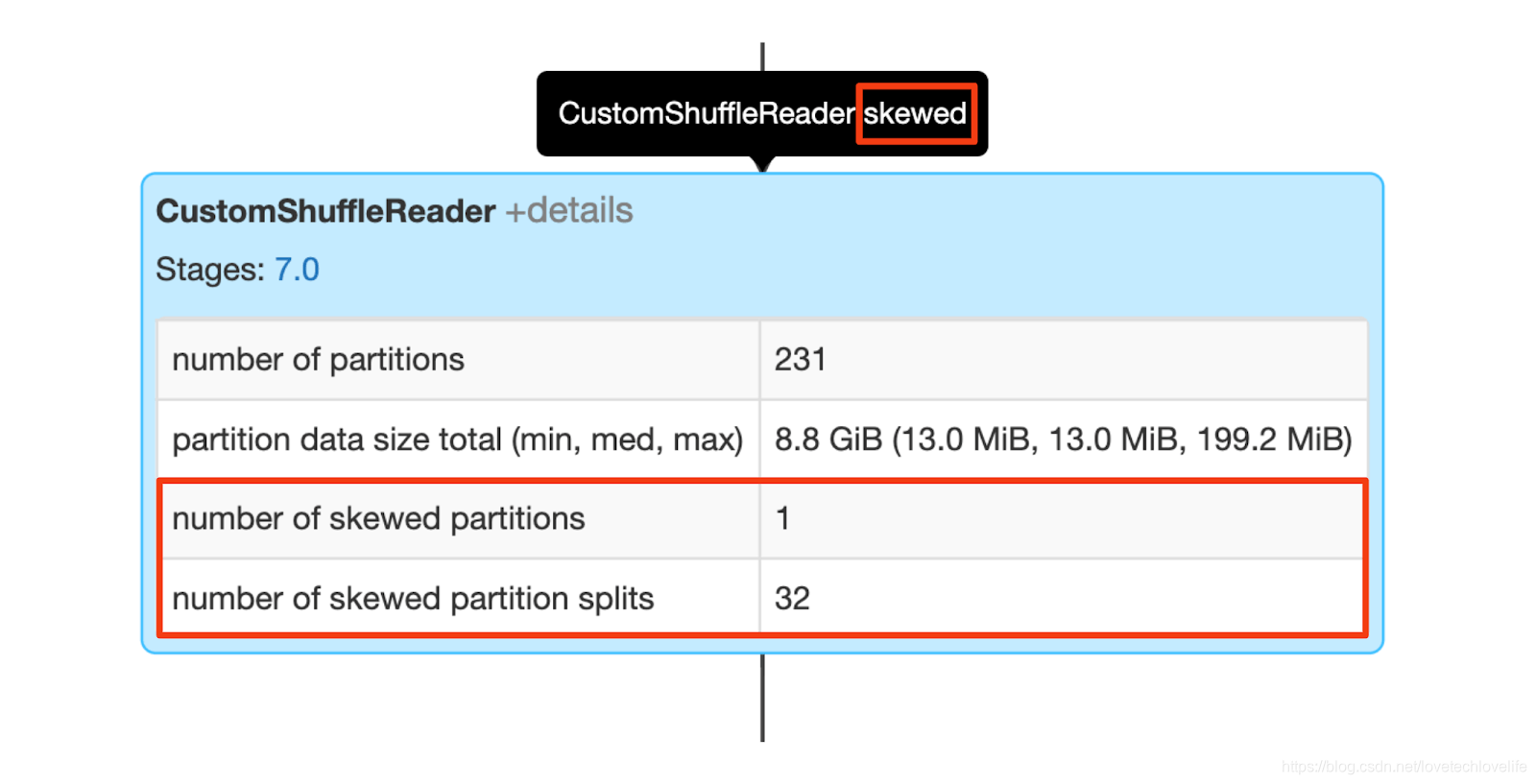
当CustomShuffleReader的标志为“skewed”时,这意味着AQE在一个sort-merge join操作之前检测到一个或多个分区中存在数据倾斜。
该节点的详细信息展示了倾斜分区的数量和将倾斜分区进行切分之后的分区数。
上面的两种情况也可以同时发生:

3. 检测Join策略的变化
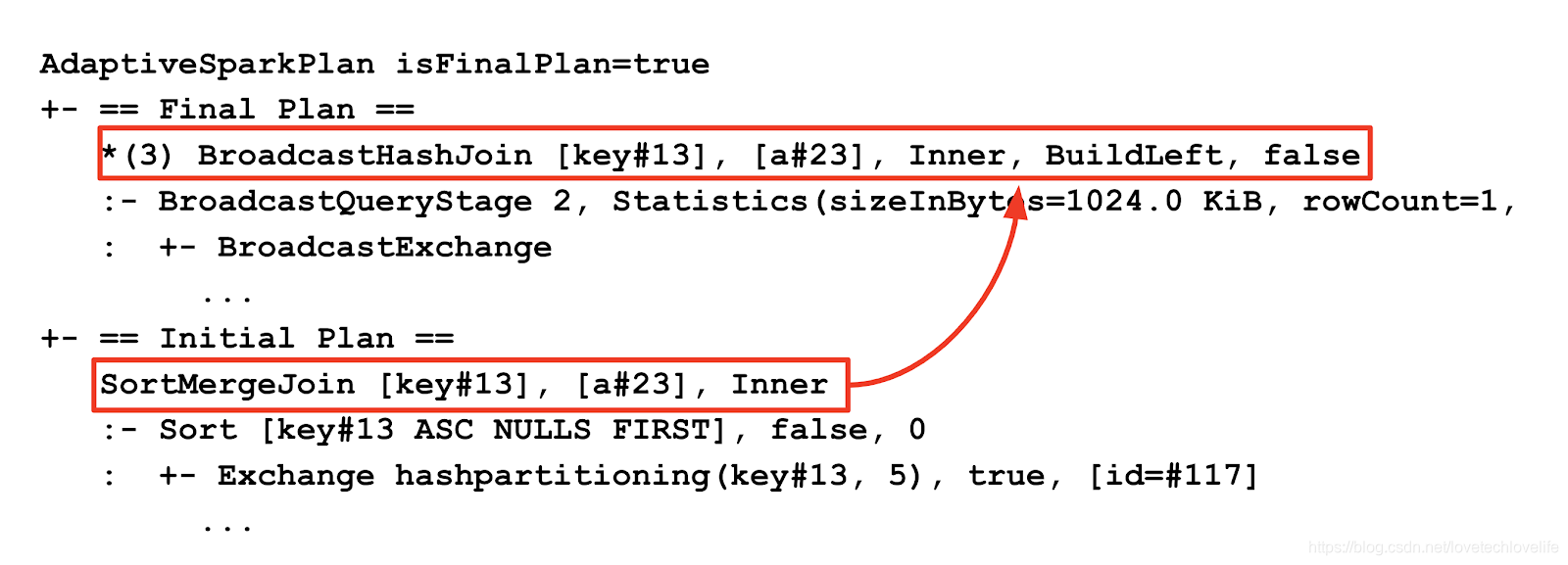
AQE可以通过比较查询计划join节点在AQE优化前后的变化,来确定join策略的更改。
在DataBrick中,AQE查询计划字符串包括初始计划和当前计划或最终计划。下面是一个broadcast-hash join被转成sort-merge join的例子:
而Spark UI只展示了当前的执行计划,并没有初始计划。如果想要在Spark UI看上AQE产生的影响,用户可以对比执行前后的计划图:
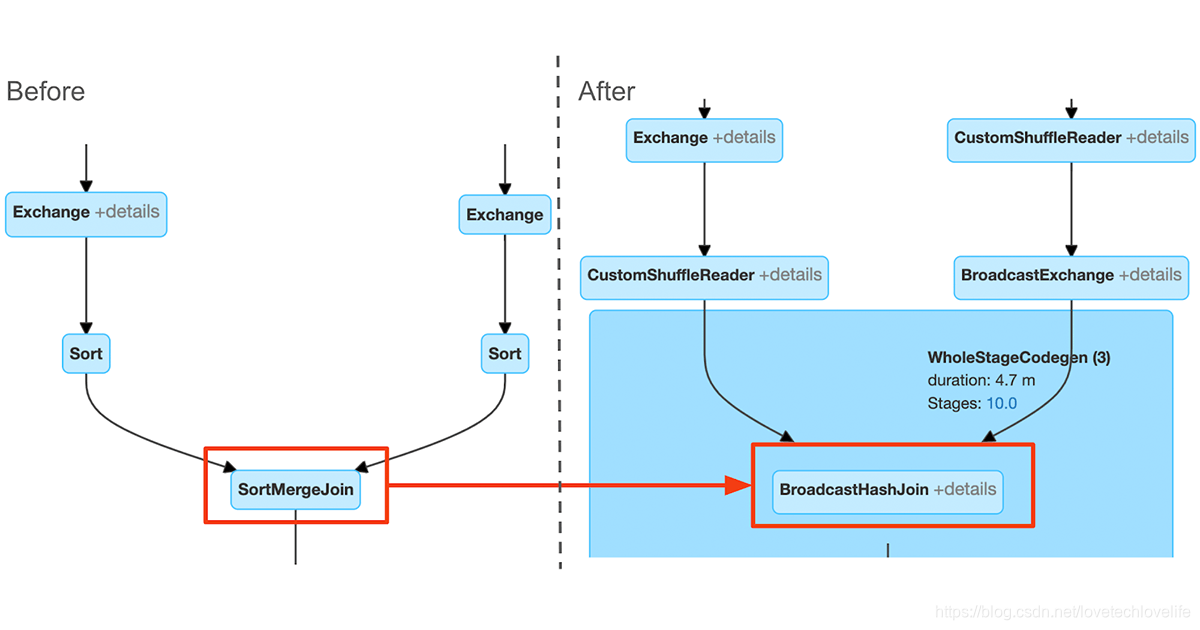
4. 检测数据倾斜
数据倾斜join优化的效果可以在Spark UI上通过join node来查看:
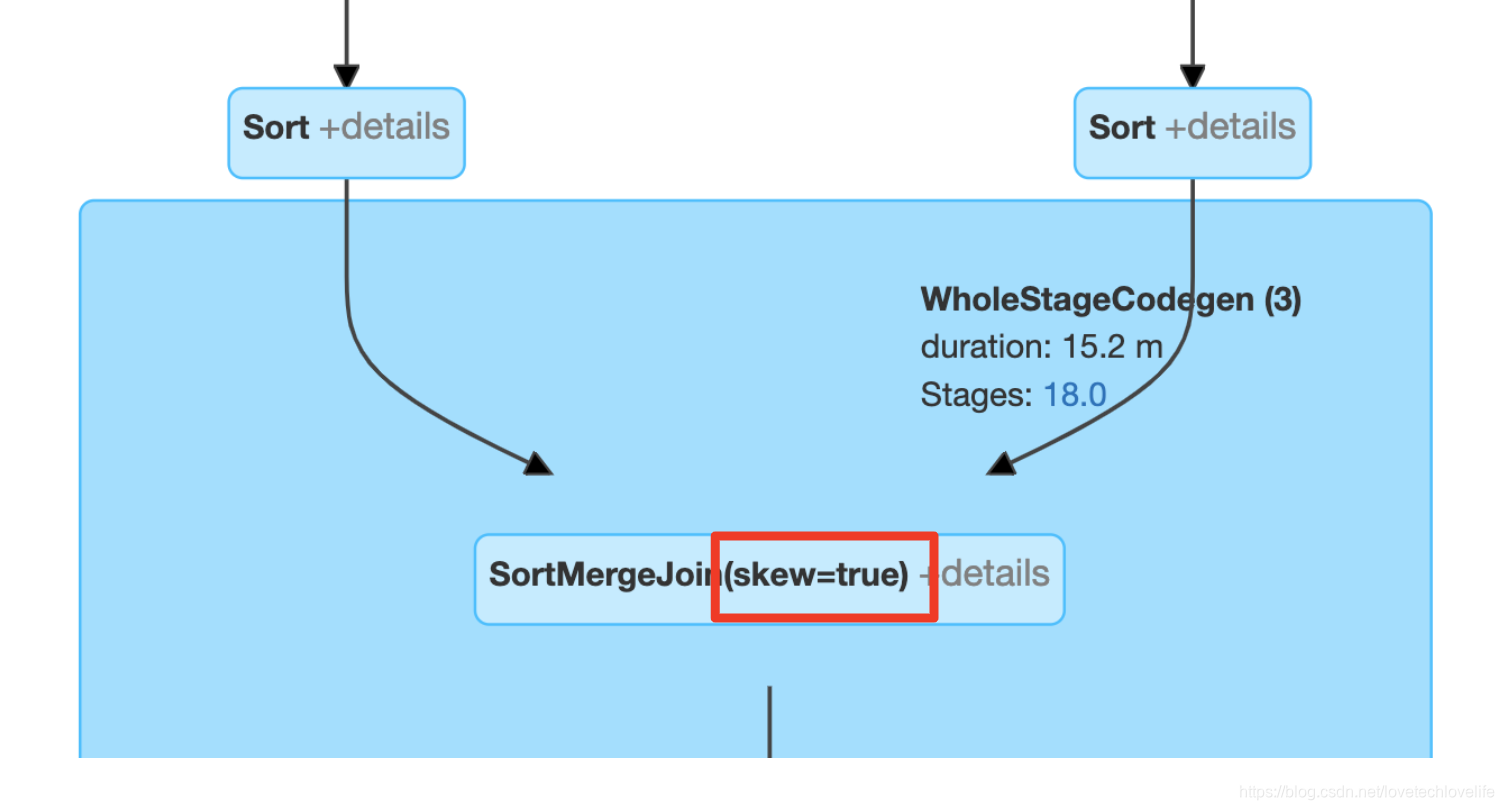
在查询计划中:

总结
AQE合并了运行时统计信息,从而使查询执行更加高效。与其他优化技术不同的是,AQE可以自动选择最佳的shuffle分区大小和数量、切换join策略并处理数据倾斜的join。
注:本篇文章翻译之Databricks Blog中的一篇文章——Faster SQL: Adaptive Query Execution in Databricks

















 1099
1099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









