






 本文分析了分布式数据库的高扩展性、高性能和高可用性,指出超大数据容量和超高并发可能是过度宣传,强调了在实际业务场景中数据库容量、性能优化和业务连续性的重要性。作者质疑100TB以下库是否真的需要分布式架构,并提倡关注数据库内核和业务适应性而非盲目追求分布式特性。
本文分析了分布式数据库的高扩展性、高性能和高可用性,指出超大数据容量和超高并发可能是过度宣传,强调了在实际业务场景中数据库容量、性能优化和业务连续性的重要性。作者质疑100TB以下库是否真的需要分布式架构,并提倡关注数据库内核和业务适应性而非盲目追求分布式特性。
分布式数据库是最近几年比较火的话题,国内的分布式数据库厂商也比较多,同时各种大会宣传的也非常多,以至于如果不会分布式,都不好意思跟客户聊天了。首先我要声明,今天的文章并非吐槽国内分布式数据库。只是我个人的一些意淫观点,大家随便看看就好(各位厂商朋友不喜勿喷)。
实际上各家分布式数据库的主要几个忽悠关键点无非就是这几点:高扩展性、高性能(千万甚至亿级tpmC)以及高可用性,至于其他的基本上不值得一提,那么我们就这3个点来剖析一下。
「高扩展:支持超大数据容量」
国内分布式数据库主要有2种架构,一种是原生分布式,即存算合体,另外一种是存算分离,从目前来看存算分离的数据库厂商更多一些;其中最早兼容MySQL为主的几个分布式数据库数据库厂商都是存算分离,还有一些严格来讲根本就不算是真正的分布式,也就是分库分布解决方案而已。
对于原生分布式,实际上通过添加存储节点即可,确实可以弹性扩容,对应用几乎是无感的;另外一类是存算分离,通过扩容底层的kv节点等等。
实际上说到容量,我们就忽略了一个关键因素。那么就是你的数据库究竟有多大?10T?20T?还是100T?话说有多少企业用户的在线业务库能够达到50Tb甚至100TB的呢?根据我们接触的各行各业的用户来看,TP类型数据库一般在5-10T的较多,大一点也就10-30T之间,运营商的量更大一些,会达到30-50T。对于数据量量大的业务系统,通常是业务要求数据保留得更长,或者应用没有设计良好的数据归档策略。
本人在2022年实施过的一个项目,客户核心业务库Oracle集群,数据量在150TB左右,该业务年数据增长在40-50T左右,实际上就是因为业务没有良好的规划,导致数据无限膨胀。如果不做调整,每年增加50T,那么10年后这个库将超过600TB,三副本的情况下将达到2PB,还不算是其他的空间。那么大家可想而知,这个业务库进行数据库国产化的压力有多大?
实际上我们用于备份的就有一台x86配置了36块7.68T SSD,该机器裸容量在240TB左右,即使做完RAID10,那么还有120TB的空间。请问,这样的高配服务器2台,能抗住多大的业务数据,多大的业务量?
因此,就拿容量来讲,我认为分布式的弹性扩容引以为豪的超大数据容量,可以认为是一个伪命题!
「高性能:支持超高并发」
这可能又是分布式数据库主打的另外一个核心点,那就是可以支持超高并发,机器够多,设计合理,那么跑个千万甚至亿级tpmC也不是难事儿。
那么这里其实又引入了一个问题,如果给你4台2路 64core的机器跑分布式数据库和一台256core的机器跑单机,你认为哪台机器的跑出来的性能可能会更高?毫无疑问,那一定是后者!
最近我们在某客户的国产化项目中,就发现用户采购的是鲲鹏服务器,居然高达256core。老实说,我还是一次见到core这么高的服务器。根据我们以往的经验,单core可以跑1.4万tpmC,以此推算,优化到位的话,那么这个单机可以跑到350万tpmC。大家知道超过300万TPMC是什么概念吗?这意味着你的数据库,单库tps/s 超过10万。
实事求是得讲,搞了16年的Oracle数据库,接触的数据库几乎覆盖了所有行业,也见过数百TB的Oracle集群,但是单库每秒超过10万 tps的单集群(单库),我还真没有见过。。。。
这里我给大家分享一下某xxxx大型系统,这可是一个超过8000kw 人口的大省核心系统,我们来看看这个50TB的库的QPS和TPS:
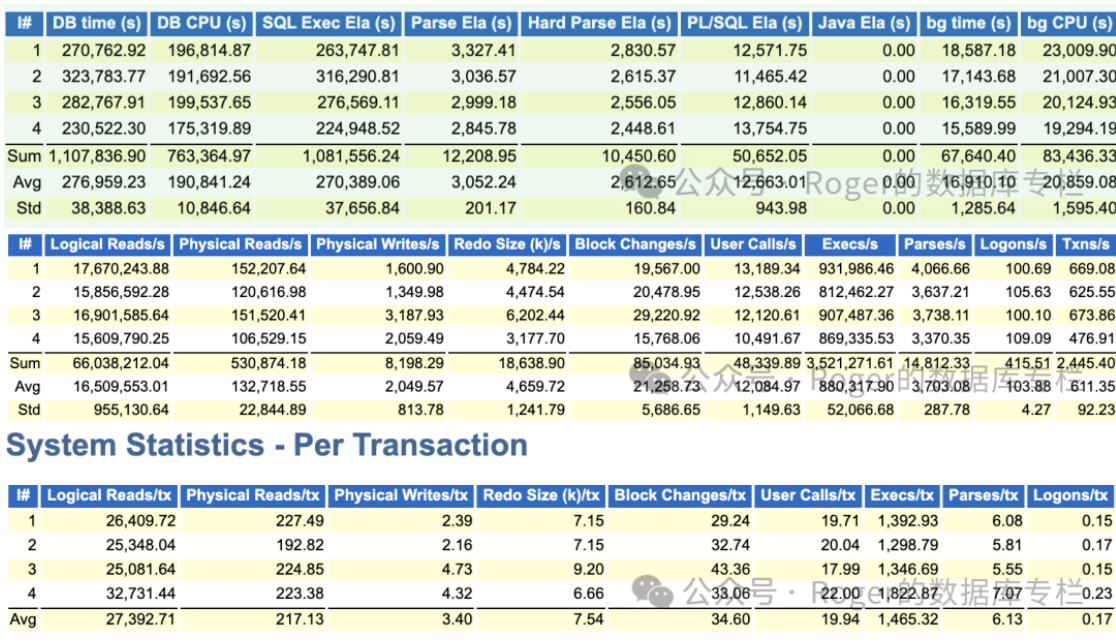
看到这套系统为4节点集群,每秒合计tps在2445左右,按照朋友的说法如果高峰期,那么可能要x2. 那么实际上tps也就5000左右。 但是要注意这个系统每秒执行的SQL数还是比较惊人,每秒SQL执行大概是350万次;;另外还可以看到每个事务的执行次数合计超过5500。为什么会这样?是的,你没看错,这又是一个PL/SQL 重度使用用户。因此不得不说,这是一个非常庞大的系统。
实际上对于此类重要大型核心系统,如果我们在进行国产化的时候,我想不应该去其TPS,更应该关注的是如何最小化业务改造的情况下,存储过程在国产数据库上也能跑的如此高效,更应该去关注数据库的内核,比如优化器等等。
这或许就是之前某某客户核心库进行实际业务验证,一个Oracle上的业务跑5分,到国产数据库可能要运行30分以上,即使经过各种优化调整仍然需要跑10多分钟。
回到这个话题,所以大家会认为现在的单机或者说主备架构抗不了自家的业务系统压力?我们更应该关注的是什么?
#「高可用性:多副本、多活」
这是分布式数据库架构的又一个特点,可以实现多活,多副本。老实说,我也挺喜欢这个特性的。作为技术人,我们还是从技术层面来说道说道。这里我们来个假设:
方案 A: 以某某分布式为例,假设6台机器(64c/128g),组成3个副本的集群(数据分别存放在3个zone或region);每个副本服务分布到3个不同的IDC机房。
方案 B:3台服务器(64c/128g),部署某国产主备数据库集群,架构为一主两从(一个强同步,一个异步)。
从数据冗余度或者说副本数量来讲,实际上两个方案是一样的,都是存了三份数据,本质上无差异。这里我们不看并发支撑能力,只比RTO的话,那么分布式数据库实际上单节点异常的时候,其他节点接管业务,其RTO也在10~30s左右(个别分布式据了解在一些场景下会超过30s,目前某云原生数据库宣称最快rto是 8s)。我们如果单单看这个RTO,实话实说,并无任何优势。现在主流主从架构的数据库,RTO基本上都能控制在30S以内(而且是有benchmark加压的情况之下).
说到这里,那么一定有人会反驳我,分布式架构可以确保业务连续性啊。是的,没错!
MogDB=# select 365*24*60*(1-0.99999) M;
m
---------
5.25600
(1 row)
MogDB=# select 365*24*60*(1-0.999999) M;
m
----------
0.525600
(1 row)
MogDB=#
衡量业务连续性或者数据库系统的高可用能力,我们通常使用RTO来表示,或者说大家熟悉的几个9. 我们常说某某数据库架构能够实现5个9,或者6个9. 我查阅了国内主流的几家分布式厂商厂商,其官网宣传都是5个9,个别是6个9.
实际上5个9就意味着全年RTO是5分钟左右,6个9难度高,也就大概31s。这应该是金融级核心业务要求的指标了。
如果不考虑其他的因素,我想大部分数据库要实现这个RTO都不是什么难事儿。
这里我要重点补充一下,实际上分布式数据库给很多客户造成了一种错觉,特别是很多不太懂技术只管业务的客户,他们会认为只要上了分布式数据库,就可以确保我的业务全年7x24 不停机。实际上这个理解是有问题的。
假设某银行核心系统有3个核心业务,分别是ABC,那么针对前面提到的方案A,通常分布式数据库场景会建议用户将ABC 3个业务分别运行在3个不同的IDC节点,这样可以避免跨界点查询性能衰减、同时还真能真正实现业务多活,假设我A机房坏了,那么也就最多影响A业务而已,BC集中中的业务是可以正常跑的。从这个角度来讲,确实是传统主备数据库无法做到的。
但实际上大部分用户的业务系统逻辑都是错综复杂,关联甚多,几乎不太可能进行拆分。
就因为业务无法拆分,或者说不好拆分,所以一些用户才选择分布式数据库,这对应用来讲更省事儿,原生分布式架构相比很早之前互联网流行的分开分表方案来说,确实有很大优势(毕竟数据量大了,扩容之后还要去重平衡数据)。然而我们这里忽略了一个关键问题,那就是性能,分布式数据库的缺点我就不再讲了,网上很多材料,前不久国内知名数据库大V 白鳝老师也写了多篇博文,其中有讲到要如何才能用好分布式。
时间有限,就暂时针对上述3个点做一些简单分析!
那么看到最后,你觉得100TB以下的库,还需要分布式吗?请留下你的观点!
如需了解更多详情如白皮书、异构数据迁移方案等请移步www.mogdb.io
如果你是软件开发商申请数据库适配,请联系市场营销marketing@enmotech.com
本文由 mdnice 多平台发布















 2638
2638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









