







1.通过http发送或读取数据(Post,Get)
HttpClient方式已被废弃。
1.1 从指定url获取返回信息(GET/POST)。
private void requestHttpView(final String urlRequest){
new Thread(new Runnable() {
@Override
public void run() {
HttpURLConnection connection=null;
try {
URL url=new URL(urlRequest);
connection=(HttpURLConnection)url.openConnection();
//从指定url建立链接。
connection.setRequestMethod("GET");
//设置连接方式。
/*
connection.setRequestMethod("POST");
//需要发送数据时,将链接方式设置为“POST”
DataOutputStream out = new DataOutputStream(connection.getOutputStream());
//获取连接的输出流(输出流输出流是相对本机而言的)
out.writeBytes("username=admin&password=123456");
//将需要发送的数据送入输出流
*/
connection.setConnectTimeout(5000);
//设置连接超时。
connection.setReadTimeout(5000);
//设置读取超时。
InputStream inputStream=connection.getInputStream();
//获取链接的输入流。
BufferedReader reader=new BufferedReader(new InputStreamReader(inputStream));
//新建BufferedReader对象,读取数据方便
StringBuilder builder=new StringBuilder();
String line;
while((line=reader.readline())!=null){
builder.append(line);
}//输入流读取完毕。
Message message=new Message();
message.what=REQUEST_OK;
message.obj=builder;
handler.sendMessage(message);
//将获取到的数据交给主线程处理。
} catch (IOException e) {
Message message=new Message();
message.what=REQUEST_ERROR;
handler.sendMessage(message);
} finally {
if (connection!=null) {
connection.disconnect();
//关闭链接
}
}
}
}).start();
}1.2 被废弃的HttpClient方式:
private void POSTUrl(String url){
new Thread(new Runnable() {
@Override
public void run() {
Message message=null;
try {
HttpClient client=new DefaultHttpClient();
//新建“客户”对象
HttpPost httpPost=new HttpPost(url);
//新建post请求
List<NameValuePair> pairs=new ArrayList<NameValuePair>();
pairs.add(new BasicNameValuePair("title", "hello"));
UrlEncodedFormEntity entity=new UrlEncodedFormEntity(pairs,"utf-8");
httpPost.setEntity(entity);
//将要发送内容添加到list中,并提交给post对象;
HttpResponse response=client.execute(httpPost);
if(response.getStatusLine().getStatusCode()==200){
//返回值状态为200代表成功
message.what=REQUEST_OK;
HttpEntity httpEntity=response.getEntity();
message.obj= EntityUtils.toString(httpEntity,"utf-8");
//取出访问url返回的内容。
}else{
message.what=REQUEST_ERROR;
message.obj="statusCode not equals 200";
}
} catch (IOException e) {
message.what=REQUEST_ERROR;
message.obj=e.toString();
}finally {
handler.sendMessage(message);
//交给主线程处理
}
}
}).start();
}
//此时方法只供参考,说明http请求的另一种模式。2. 数据解析——xml文档;
访问某个url返回的数据,大都是html语言,例如WebView控件就是将http请求以及获取的数据封装,用浏览器的方式进行查看。
还有些返回的内容只提供数据,不能形成可视化网页,例如xml和json。这些内容大都不要进行解析,从中提取想要的information。
2.1 解析xml文档——pull
Pull解析器提供的事件类型总共有5种,分别如下:
- (1)START_DOCUMENT 文档开始
- (2)START_TAG 开始节点
- (3)TEXT 文本节点
- (4)END_TAG 节点结束
- (5)END_DOCUMENT 文档结束
pull解析原理:从文档头开始,整个文档由节点组成,有些节点中包含属性和文本;
<qq mm="a" nn="b">text</qq>
//<qq ……>表示qq节点的开始
//<qq mm="a" nn="b">text</qq>就是节点。
//qq是节点名字
//mm和nn都是属性名
//a和b是节点对应的值
//text是文本
//遇到</qq>代表节点qq结束pull方式解析,就是新建一个xmlPullParser对象,然后从头开始“推”,开始解析时,将事件设置为START_DOCUMENT,当碰到节点开始标志时,会将事件设置为START_TAG,如此解析下去,直到文档结束,然后将事件为END_DOCUMENT 文档结束;下面介绍解析时用到的方法:
(1)int getAttributeCount(); //获取当前节点的属性个数
(2)String getAttributeValue(int index); //获取属性值,参数表示第index个属性。
(3)int getEventType();//获取事件类型
(4)String getName();//用于START_TAG和END_TAG事件中,获取当前节点的名字
(5)int next();//处理下一个节点
(6)String nextText();//用于START_TAG事件中,获得下一个TEXT类型的节点(就是文本)pull解析代码:
private String[] analyzeXML(String xml,String[] names){
String[] values=new String[names.length];
try {
XmlPullParserFactory factory=XmlPullParserFactory.newInstance();
XmlPullParser parser=factory.newPullParser();
//利用“工厂”生产一个进行pull解析的对象。
parser.setInput(new StringReader(xml));
//设置进行pull解析的内容或输入流
int type=parser.getEventType();
//获取当前的事件类型。
while(type!=XmlPullParser.END_DOCUMENT){
//不断的读取下一个节点,直到文档结束。
String nodeName=parser.getName();
switch (type){
case XmlPullParser.START_TAG:{
for(int i=0;i<names.length;i++){
if(names[i].equals(nodeName)){
values[i]=parser.nextText();
//nodeName为当前节点名
break;
}
}
break;
}
case XmlPullParser.END_TAG:{
break;
}
default:{
break;
}
}
type=parser.next();
}
} catch (Exception e) {
}
return values;
//返回获取到的对应节点的文本
}2.2 解析xml文档——sax
sax解析原理:sax解析方式与pull有些类似,都是一边读取一边解析,不过sax将解析以类的形式封装起来,只需要重写方法就可以了。
sax属于事件驱动,每当遇到一定的标志就执行特定的方法;pull像是”手动“驱动,需要代码显示控制读取,判断,取值,再读取……
sax解析代码:
SAXParserFactory factory=SAXParserFactory.newInstance();
XMLReader xmlReader=factory.newSAXParser().getXMLReader();
MyHandler handler = new MyHandler();
xmlReader.setContentHandler(handler);
// 将ContentHandler的实例设置到XMLReader
//(setContentHandler方法需要接收一个处理解析事件的类参数)
xmlReader.parse(new InputSource(new StringReader(xmlData)));
// 开始执行解析myHandler类一般继承DefaultHandler类,然后重写其中的事件方法。
MyHandler代码:
public class MyHandler extends DefaultHandler {
@Override
public void startDocument() throws SAXException {
//开始解析文档时调用,进行初始化的工作。
}
@Override
public void startElement(String uri, String localName, String qName,Attributes attributes) throws SAXException {
//开始某节点时候调用
/*uri - 名称空间 URI,如果节点没有任何名称空间 URI,或者没有正在执行名称空间处理,则为空字符串。
*localName - 本地名称(不带前缀),如果没有正在执行名称空间处理,则为空字符串。
*qName - 限定的名称(带有前缀),如果限定的名称不可用,则为空字符串。(节点名,一般读取数据时比较qName是否是自己想要的内容名称,然后提取数据)
*attributes - 附加到节点的属性。如果没有属性,则它将是空的 Attributes 对象。
*/
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
//获取文本时候调用,准确的说应该是在读取某节点中内容时候调用。
/*ch - 字符。
*length - 从字符数组中使用的字符数。
*start - 字符数组中的开始位置
*/
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
//节点结束时调用
//与startElement参数基本相同
}
@Override
public void endDocument() throws SAXException {
//文档结束时调用
}
}
//从解析方法中也可以看出,xml格式非常重要,不规范的书写方式会导致解析失败。这样看起来是不是发现sax除了比较”自动化“之外,跟pull解析没有多大的区别。
2.3 解析xml文档——DOM
js中,dom指的是文档对象模型,也是操作页面最基本最常用的方法。
DOM原理: pull与sax解析都是无”记忆”的,即对整个文档而言,只能在触发事件时进行内容的读取,不可能依靠前两种解析方式理清文档结构。DOM则是先将文档 ”通读“,以节点建立”树“的模型,在想要获取内容时只要知道在”树“中的位置,就可以随时读取,不过因为要建立模型,因此会占用较大的内存空间。
DocumentBuilderFactory factory=DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document doc = builder.parse(file);
//其实解析xml文档方法步骤都差不多,先构建出解析器,再传入需要解析的内容,然后对内容进行分析。此时获得的doc包含整个文档中的节点。直观来看:
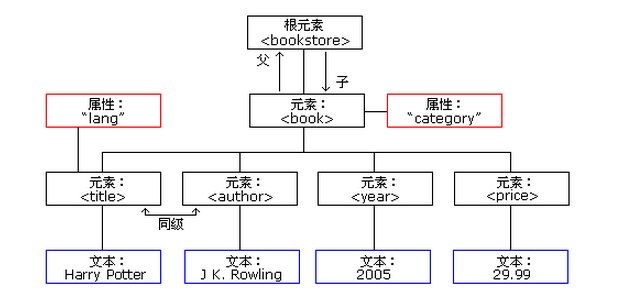
(随便找了个xml的dom树)
//可以看到,dom“树”的节点是由节点(非TEXT类型)和文本组成的(文本总是没有子节点的子节点,属性相当于节点的“附加"信息。我们获取的内容就是指文本)
//系统不可能将”树“形象的映射到内存里,因此dom解析是通过栈来实现的,因为xml文档的规范性,通过查看栈的数据,就可以”立体化“dom树。
//需要注意的是,dom解析类似于引用,如果改变生成的doc,那么实际的文档将会被改变。
//dom查找数据可以通过根节点不停的查找子节点,直至定位到想要的节点,然后获取内容。节点——Node:节点本来是数据结构中tree的组成部分,不过在xml文档中,所有的内容都可以称为节点。在Dom中,节点分为十二总,涵盖了文档中所有部分,我们上面说的”文本“,其实只是TEXTNODE类型的节点,不过为了直观,把两者区分开来。
元素——Element:元素和节点很相似,事实上,看源码的话可以发现Element继承自Node,Element相当于Node的扩展,不过使用起来较为方便一些。
Node与Element的区别
例:
private String xmlAnalize(String xml){
/*xml字符串内容:
*<?version="1.0" encoding="utf-8"?>
*<html title="title">
* <head>head</head>
* <!--reliase-->
* <body>body</body>
*</html>
*/
try {
DocumentBuilder documentBuilder=DocumentBuilderFactory.newInstance().newDocumentBuilder();
Document document=documentBuilder.parse(new ByteArrayInputStream(xml.getBytes("UTF-8")));
NodeList childs=document.getChildNodes();
Node node1;
if(childs.getLength()>0){
for(int i=0;i<childs.getLength();i++){
node1=childs.item(i);
Log.i("java","……………………"+node1.getNodeType()+"&"+node1.getNodeName()+"&"+node1.getNodeValue());
}
}
/*控制台输出:
*……………………7&version="1.0"&encoding="utf-8"
* ……………………1&html&null
*/
//由此可见document相当于整个文档,getChildNodes方法可以获得“根目录”下所有子节点,此处7表示文档编码版本等信息。
Element element=document.getDocumentElement();//xml规范,xml文档除了开头的编码等说明外,其他内容必须包含在同一个根节点下。getDocumentElement()方法便是获取该根目录节点(此节点也是Element)。
Log.i("java","……………………"+element.getNodeType()+"&"+element.getNodeName()+"&"+element.getNodeValue());
/*控制台输出:
* ……………………1&html&null
*/
return getElements(element);
} catch (Exception e) {
Log.i("java",e.toString());
return null;
}
}
private String getElements(Node node){
//获取html节点下所有子节点的类型,名字,和值。
StringBuilder builder=new StringBuilder();
NodeList nodeList=node.getChildNodes();
Node node1;
if(nodeList.getLength()>0){
for(int i=0;i<nodeList.getLength();i++){
node1=nodeList.item(i);
builder.append(node1.getNodeType()+"&"+node1.getNodeName()+"&"+node1.getNodeValue()+"\n");
Log.i("java",node1.getNodeType()+"&"+node1.getNodeName()+"&"+node1.getNodeValue());
//获取结点对应的类型,name,以及value
}
}//判断属性结点会不会在节点树中。
/*控制台输出:
* 1&head&null
* 8&#comment&reliase
* 1&body&null
*/
//可以看到,dom解析还可以获取到注释信息,而html节点下的属性信息不能通过getChildNodes方法获得。
return builder.toString();
}
3. 数据解析——json
假如json数据以“组”的形式存在,如数组,list(map除外)。
private Vector<String[]> analyzeJSON(String jsonData,String[]names) {
Vector<String[]> vector=new Vector<String[]>();
try {
JSONArray jsonArray = new JSONArray(jsonData);
for (int i = 0; i < jsonArray.length(); i++) {
JSONObject jsonObject = jsonArray.getJSONObject(i);
String[]values=new String[names.length];
for(int j=0;j<values.length;j++){
values[j]=jsonObject.getString(names[j]);
}
vector.add(values);
}
} catch (Exception e) {
}
return vector;
}jsonArray可以存储“组”,jsonObject提取组中的”单“个信息。















 2878
2878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









