






1.数据库
1.1count(1),count(*)和count(列名)的区别
一、从执行效果来看
-
count(1) and count(*):
基本没差别,都是求表的总行数
count(*)包括了所有的列,相当于求记录总行数,在统计结果的时候,不会忽略NULL -
count(1) and count(列名):
(1) count(1) 会统计表中的所有的记录数,不会忽略NULL,包含字段为null 的记录。
(2) count(列名) 会统计该列字段在表中出现的次数,会忽略字段为null 的情况,即不统计字段为null 的记录。
二、从执行效率来看
若列名为主键,count(列名)会比count(1)快
若列名不为主键,count(1)会比count(列名)快
若表多个列并且没有主键,则 count(1) 的执行效率优于 count(*)
若表有主键,则 select count(主键)的执行效率是最优的
若表只有一个字段,则 select count(*)最优。
所以实际业务中一般用count(1)比较普遍,但是如果需要聚合多个列,则用count(列名)比较合适。
————————————————
版权声明:本文为CSDN博主「攻城狮Kevin」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wx1528159409/article/details/95643499
补充关于count(1)count(*)原理 引用百度知道专业回答
count(1),其实就是计算一共有多少符合条件的行。
1并不是表示第一个字段,而是表示一个固定值。
其实就可以想成表中有这么一个字段,这个字段就是固定值1,count(1),就是计算一共有多少个1。
count(*),执行时会把星号翻译成字段的具体名字,效果也是一样的,不过多了一个翻译的动作,比固定值的方式效率稍微低一些。
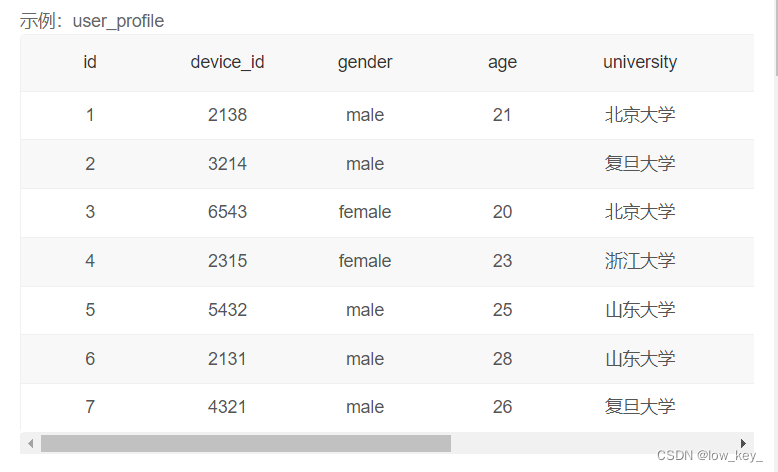
1.2牛客SQL入门26计算25岁以上和以下的用户数量
1.2.1题目
题目:现在运营想要将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量
1.2.2 题解
将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量
问题分解:
限定条件:无;
年龄划分为两段:if(age>=25, “25岁及以上”, “25岁以下”)
统计用户数量:count,每个段分别统计,用group by age_cut分组
当然本题也可以用union all解决,不过用if更直观
细节问题:
表头重命名
注意题目描述的示例和testcase结果不一致!!(已修复)
针对年龄为空的记录,需要明确是划分到哪边
不同段的释义要根据testcase调整
1.2.3 SQL语句
select写法
select
if(age>=25,"25岁及以上","25岁以下") as age_cut,count(1) as number
from user_profile
group by age_cut;
case写法
select
(case
when age>=25 then '25岁及以上'
else '25岁以下' end) as age_cut,
count(*) as number
from user_profile
group by age_cut
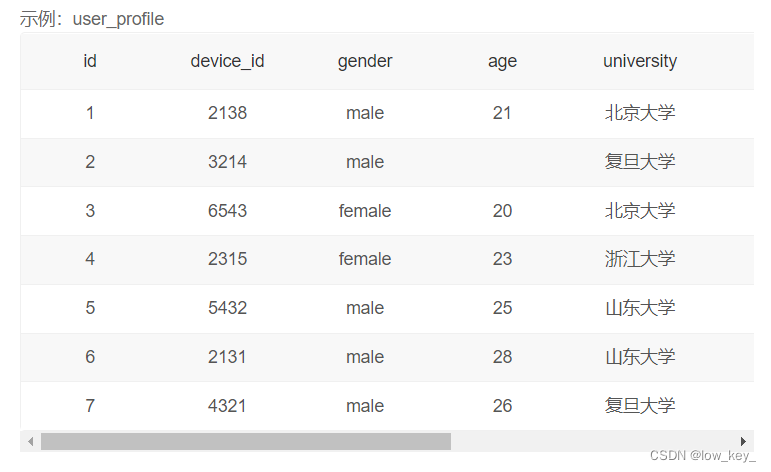
1.3牛客SQL入门27查看不同年龄段的用户明细
1.3.1 题目
题目:现在运营想要将用户划分为20岁以下,20-24岁,25岁及以上三个年龄段,分别查看不同年龄段用户的明细情况,请取出相应数据。(注:若年龄为空请返回其他。)
1.3.2 题解
问题分解:
限定条件:无;
划分年龄段:数值条件判断,可以用多重if,不过更方便的是用case when [expr] then [result1]…else [default] end
附:case when用法
细节问题:
表头重命名:as
输出的段明文在题目描述和输出示例中不一致,以输出示例为准
1.3.3 SQL语句
select
device_id,gender,
CASE
when age<20 then "20岁以下"
when (age>=20 and age<=24) then "20-24岁"
when age>24 then "25岁及以上"
else "其他" end as age_cut
from user_profile
1.4MySQL中的only_full_group_by模式
对于 GROUP BY 聚合操作,如果在 SELECT 中的列,没有在 GROUP BY 中出现,那么这个 SQL 是不合法的,因为列不在 GROUP BY 句中,所以对于设置了这个 mode 的数据库,在使用 GROUP BY 的时候,就要用 MAX(),SUM(),ANT_VALUE() 这种聚合函数,才能完成 GROUP BY 的聚合操作。
————————————————
版权声明:本文为CSDN博主「Asurplus」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40065776/article/details/108747528
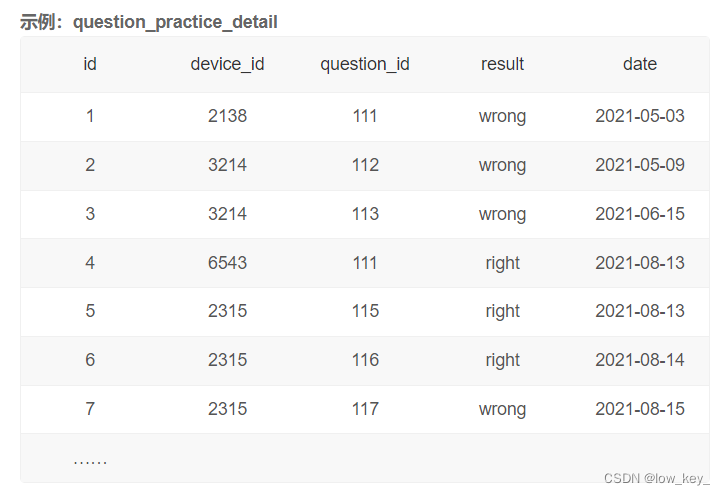
1.5牛客入门28计算用户8月每天的练题数量
1.5.1 题目
题目:现在运营想要计算出2021年8月每天用户练习题目的数量,请取出相应数据。
1.5.2 题解
题意明确:
2021年8月每天用户练习题目的数量
问题分解:
限定条件:2021年8月,写法有很多种,比如用year/month函数的year(date)=2021 and month(date)=8,比如用date_format函数的date_format(date, “%Y-%m”)=“202108”
每天:按天分组group by date
题目数量:count(question_id)
细节问题:
表头重命名:as
输出示例中每天的字段只取了几号,要去掉年月,用day函数即可
1.5.3 SQL语句
select
day(date) as day,
count(question_id) as question_cnt
from question_practice_detail
where month(date)=8 and year(date)=2021
group by date
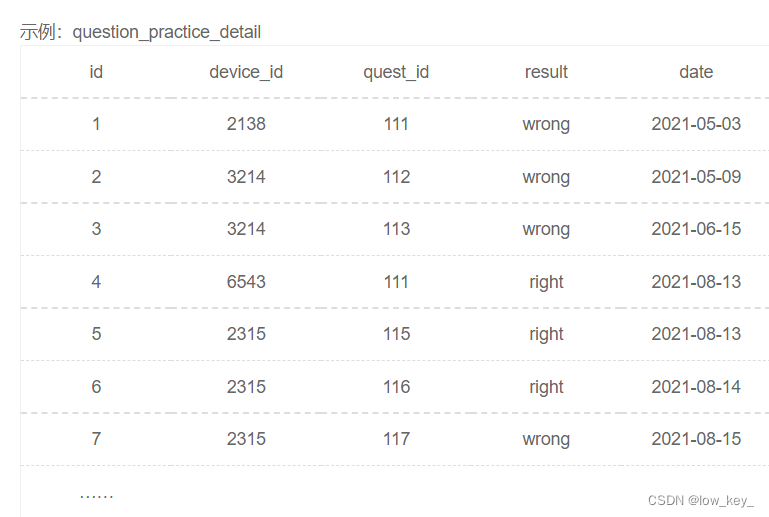
1.6牛客入门SQL29计算用户的平均次日留存率
1.6.1题目
题目:现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。请你取出相应数据。

1.6.2 题解
题意明确:
用户在某天刷题后第二天再来刷题的平均概率
问题分解:
限定条件:第二天再来。
解法1:表里的数据可以看作是全部第一天来刷题了的,那么我们需要构造出第二天来了的字段,因此可以考虑用left join把第二天来了的拼起来,限定第二天来了的可以用date_add(date1, interval 1 day)=date2筛选,并用device_id限定是同一个用户。
解法2:用lead函数将同一用户连续两天的记录拼接起来。先按用户分组partition by device_id,再按日期升序排序order by date,再两两拼接(最后一个默认和null拼接),即lead(date) over (partition by device_id order by date)
平均概率:
解法1:可以count(date1)得到左表全部的date记录数作为分母,count(date2)得到右表关联上了的date记录数作为分子,相除即可得到平均概率
解法2:检查date2和date1的日期差是不是为1,是则为1(次日留存了),否则为0(次日未留存),取avg即可得平均概率。
细节问题:
表头重命名:as
去重:需要按照devece_id,date去重,因为一个人一天可能来多次
子查询必须全部有重命名
1.6.3SQL语句
解法1:
select count(date2) / count(date1) as avg_ret
from
(
select
distinct qpd.device_id,
qpd.date as date1,
uniq_id_date.date as date2
from question_practice_detail as qpd
left join
(
select distinct device_id, date
from question_practice_detail
) as uniq_id_date
on qpd.device_id=uniq_id_date.device_id
and date_add(qpd.date, interval 1 day)=uniq_id_date.date
) as id_last_next_date
解法2:
select avg(if(datediff(date2, date1)=1, 1, 0)) as avg_ret
from (
select
distinct device_id,
date as date1,
lead(date) over (partition by device_id order by date) as date2
from (
select distinct device_id, date
from question_practice_detail
) as uniq_id_date
) as id_last_next_date
2.算法
2.1动态规划
在我看来,动态规划就是暴力递归+记忆化
2.1.1动态规划的三大步骤
动态规划,无非就是利用历史记录,来避免我们的重复计算。而这些历史记录,我们得需要一些变量来保存,一般是用一维数组或者二维数组来保存。下面我们先来讲下做动态规划题很重要的三个步骤,
第一步骤:定义数组元素的含义,上面说了,我们会用一个数组,来保存历史数组,假设用一维数组 dp[] 吧。这个时候有一个非常非常重要的点,就是规定你这个数组元素的含义,例如你的 dp[i] 是代表什么意思?
第二步骤:找出数组元素之间的关系式,我觉得动态规划,还是有一点类似于我们高中学习时的归纳法的,当我们要计算 dp[n] 时,是可以利用 dp[n-1],dp[n-2]……dp[1],来推出 dp[n] 的,也就是可以利用历史数据来推出新的元素值,所以我们要找出数组元素之间的关系式,例如 dp[n] = dp[n-1] + dp[n-2],这个就是他们的关系式了。
学过动态规划的可能都经常听到最优子结构,把大的问题拆分成小的问题,说时候,最开始的时候,我是对最优子结构一梦懵逼的。估计你们也听多了,所以这一次,我将换一种形式来讲,不再是各种子问题,各种最优子结构。
第三步骤:找出初始值。学过数学归纳法的都知道,虽然我们知道了数组元素之间的关系式,例如 dp[n] = dp[n-1] + dp[n-2],我们可以通过 dp[n-1] 和 dp[n-2] 来计算 dp[n],但是,我们得知道初始值啊,例如一直推下去的话,会由 dp[3] = dp[2] + dp[1]。而 dp[2] 和 dp[1] 是不能再分解的了,所以我们必须要能够直接获得 dp[2] 和 dp[1] 的值,而这,就是所谓的初始值。
由了初始值,并且有了数组元素之间的关系式,那么我们就可以得到 dp[n] 的值了,而 dp[n] 的含义是由你来定义的,你想求什么,就定义它是什么,这样,这道题也就解出来了。















 484
484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









