







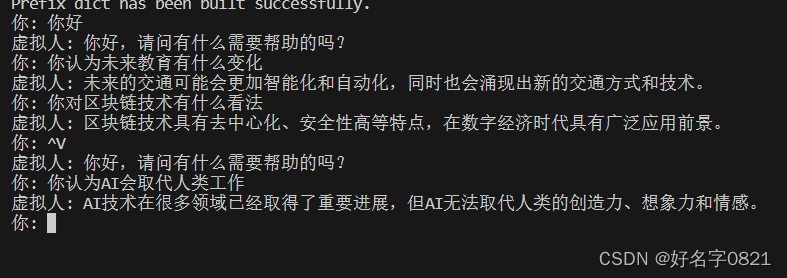
实现效果
实现效果图如下:
准备工作
一个文件夹,里面装一个python文件,一个questions.txt文件,一个answers.txt文件,下载所需要的库。
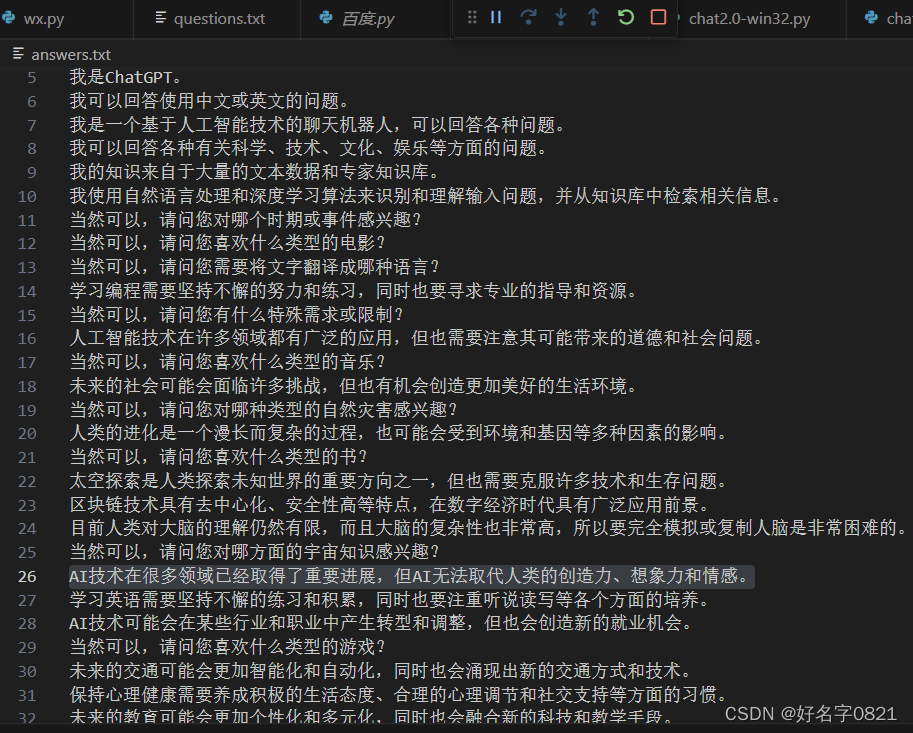
在question和answers设置对应的问题和答案。
如:

然后导入代码即可使用。
import jieba
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
# 问题和回答数据文件
questionTXT = 'questions.txt'
answerTXT = 'answers.txt'
# 数据预处理
questions = []
# 读入问题数据
with open(questionTXT, "r", encoding="utf-8") as f:
for line in f:
questions.append(line.strip())
questions = [jieba.lcut(q) for q in questions]
questions = [' '.join(q) for q in questions]
answers = []
# 读入回答数据
with open(answerTXT, "r", encoding="utf-8") as f:
for line in f:
answers.append(line.strip())
# 特征提取
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(questions)
# 聊天循环
while True:
# 读入用户输入
user_input = input('你: ').strip()
if not user_input:
continue
# 预处理用户输入
user_input = jieba.lcut(user_input)
user_input = ' '.join(user_input)
# 匹配最相似的问题
test_X = vectorizer.transform([user_input])
sims = np.dot(test_X[0], X.T)
index = sims.argmax()
# 输出回答
print('虚拟人:', answers[index])
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











