






啊,网传不到 24 小时《黑神话:悟空》速通结局已经释出,天命人最终戴上金箍拜入佛门,被规则和金箍所操控,等待下一个天命人来继续轮回。
但有的网友不干了,表示速通就注定只能坏结局,天命人哪是那么容易屈服的;
有网友表示不能接受,猜测应该会有好几个结局吧,毕竟他还只打到黑熊那儿。。。
无论怎么样,最近广大网友投入了上班做真马喽,下班做黑马喽的热血生活~

在屏幕前的你是否也在好奇,九九八十一难,最大的那个boss到底长啥样?Neolink.AI 的小伙伴用 AI 预测一波最终boss形态:
 本文手把手教学如何实现预测教程~
本文手把手教学如何实现预测教程~
本文字数:7000字+
阅读时间:8分钟+Part 1
预热
-
在https://neolink-ai.com/ 上挑选服务器并配置远程登录;
-
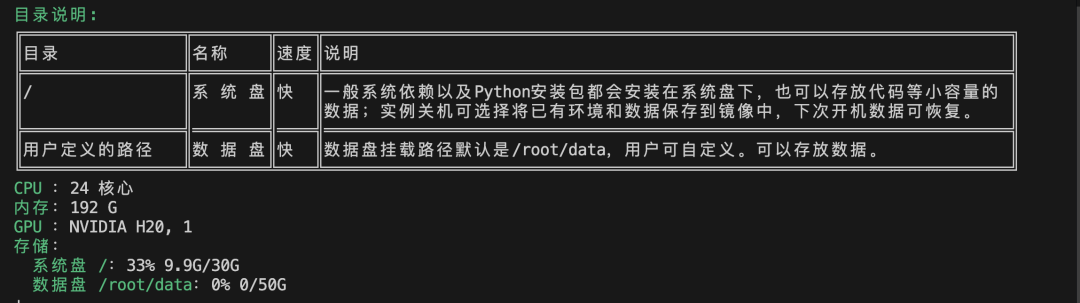
下载代码,创建 conda 虚拟环境并安装相关依赖。注册并登录后,进入控制台,选择创建实例:
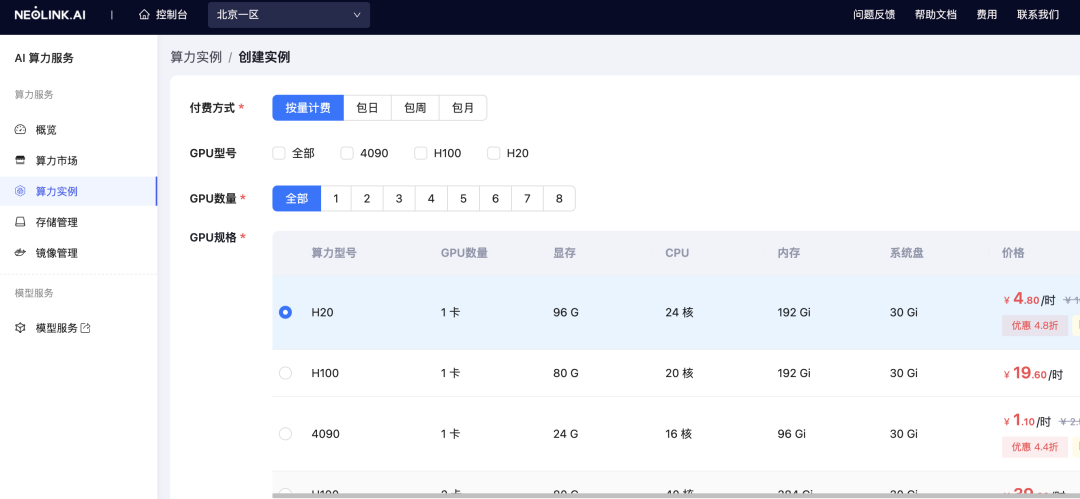
根据您的需求,选择相应的显卡:
在这里我们为了庆祝《黑神话悟空》的发布,选择了超强的显卡H20!
全网最低价!https://neolink-ai.com/ H20 只要 4.8元/小时,4090低至 1.1元/小时
Part 2
ComfyUI安装
此步需要你将 ComfyUI 代码拉到我们的服务器上。如果你会 Git 请在 Terminal 运行以下代码,即可完成此步骤git clone:
https://github.com/comfyanonymous/ComfyUI。
具体步骤可参考以下简单通用教程:
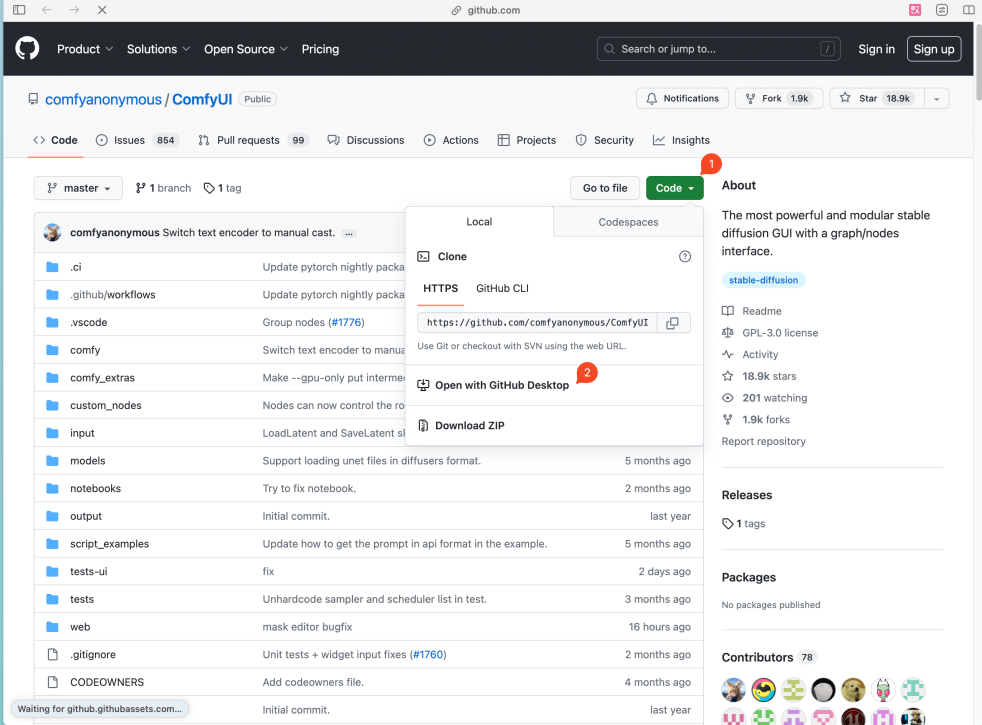
1. 打开 ComfyUI 项目 & 下载
打开 ComfyUI 的Github页面[https://github.com/comfyanonymous/ComfyUI],点击右上角的绿色按钮(下图1),并点击菜单里的「Open with GitHub Desktop」(下图2),此时浏览器会弹出你是否要打开 GitHub Desktop,点击「是」。
2. 安装依赖
下载好代码后,需要安装依赖。
2.1 打开项目文件夹
2.2 打开终端
2.3 输入命令
最后一步你需要在底部 Terminal 输入以下命令,并点击回车:
# 如果遇到网络问题看后面的 Q&Apip install -r requirements.txt3. 启动服务
不管你在上一步是用 VS Code 运行,还是在 Terminal 里运行,你都可以继续输入以下代码:
python main.py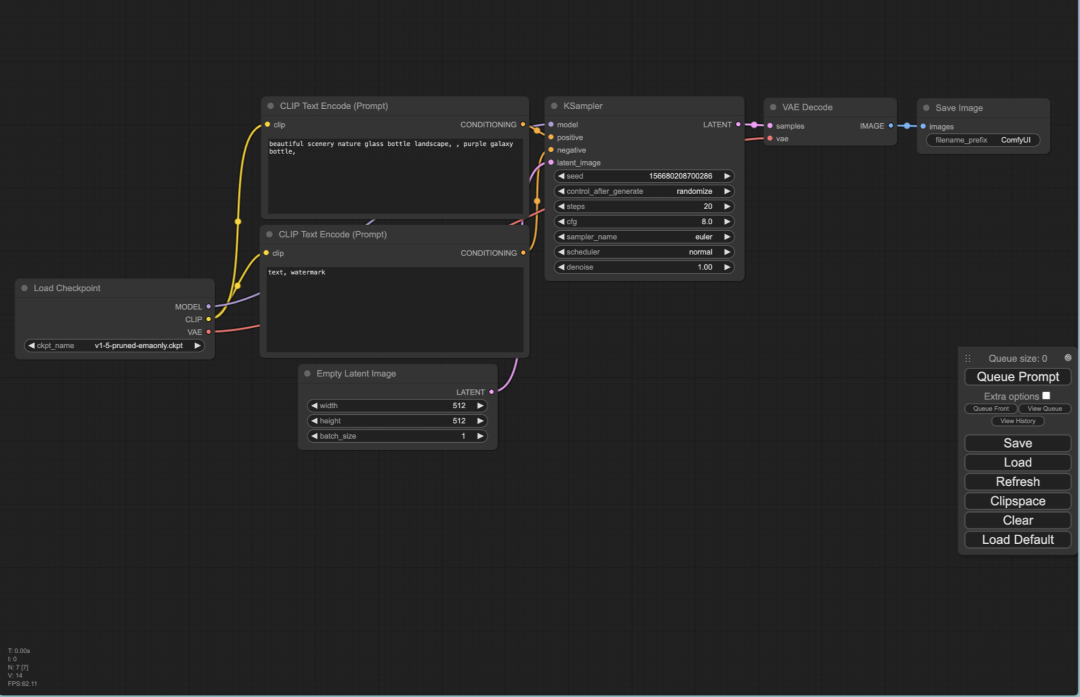
你应该能看到以下界面。恭喜你,ComfyUI 已经安装好了。但此时还没法运行 Stable DIffusion 生图。你还需要下载关键的模型,在下一章我会教大家如何下载并安装所需的模型。
4. 将模型添加到对应的文件夹
进入到 Model 文件夹后,你会看到很多个文件夹,这些文件夹分别对应着不同的模型,你需要将你下载的模型放到对应的文件夹下。比如我们刚刚下载的是 Stable Diffusion v1.5 模型,属于 checkpoints 就需要将该模型放到 checkpoints 文件夹下。
4.1 打开 ComfyUI 项目文件夹
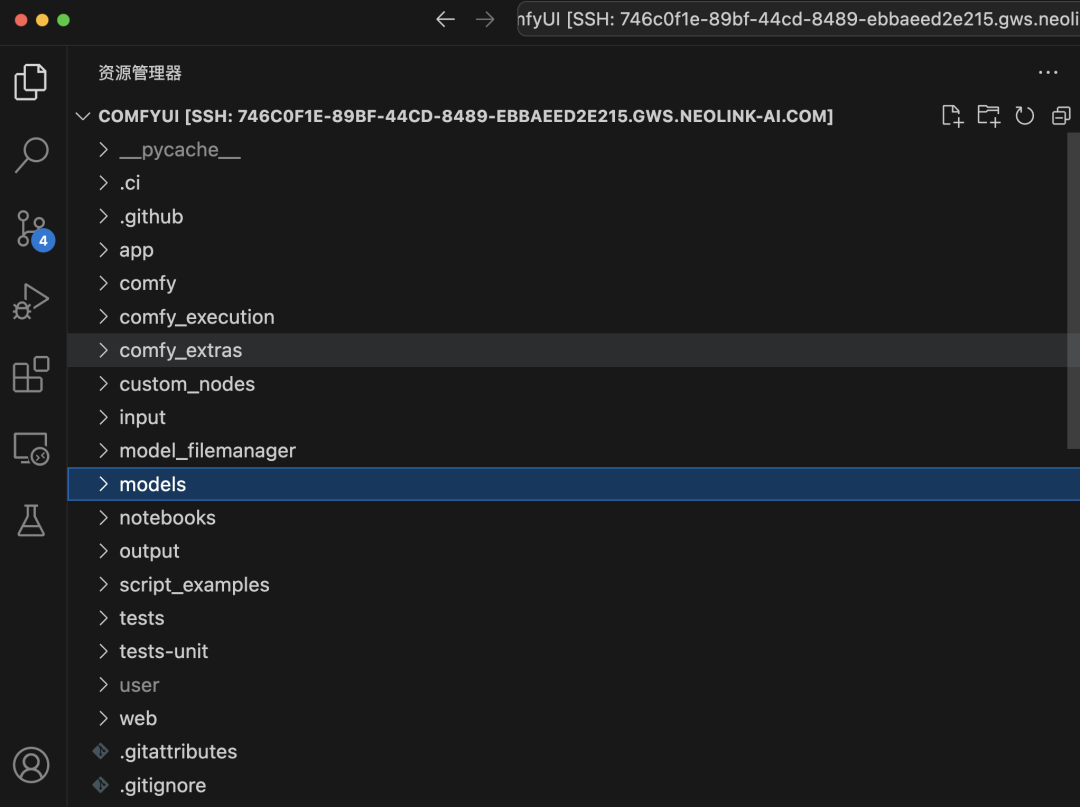
4.2 将模型添加到对应的文件夹
进入 Model 文件夹后,你会看到多个文件夹,这些文件夹分别对应不同的模型类型。你需要将下载的模型放入相应的文件夹中。例如,刚才下载的 Stable Diffusion v1.5 模型属于 checkpoints 文件夹,因此应将其放入该文件夹中。接下来我们会介绍其他类型的模型,你需要将它们放入对应的文件夹中,例如CLIP-ViT-H-14-laion2B-s32B-b79K的clip模型放在clip中。
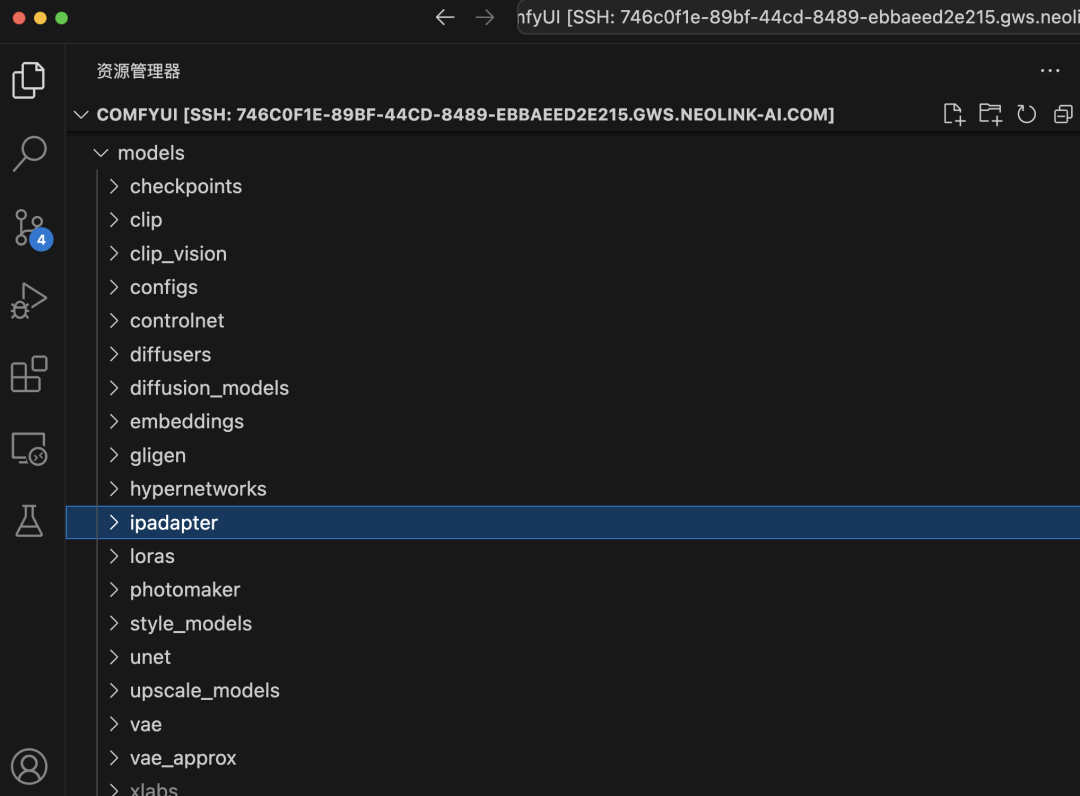
🎉 恭喜你,又完成了一个重要的步骤,接下来我们就可以正式进入 ComfyUI 基础篇的学习了。
5. ComfyUI - IPAdapter (SDv1.5 Version)
我们选择使用IPAdapter 做我们这期课的教程,IPAdapter 接受一张图像作为输入,将其编码为Token,并和标准的提示词输入混合作用于图像的生成。
5.1 安装插件 ComfyUI_IPAdapter_plus
https://github.com/cubiq/ComfyUI_IPAdapter_plus.git
将该仓库下载或通过 git clone 到 ComfyUI/custom_nodes/ 目录下,或者使用管理工具。请确保 IPAdapter 始终使用最新版本的 ComfyUI。
目前该插件支持的模型有以下:
-
clip_vision 视觉模型:即图像编码器,下载完后需要放在 ComfyUI /models/clip_vision 目录下;
-
P-Adapter 模型:下载完后需要放在/ComfyUl/models/ipadapter 目录下;
-
Clip 模型:下载完后需要放在 /ComfyUI/models/clip 目录下;
-
Lora 模型:下载完后需要放在 /ComfyUI/models/loras 目录下。
请注意版本哦,其中名字带有 sd15 适用于 sd15 大模型,带有 sdxl 的适用于 sdxl 大模型;其中名字带有 vit-h 的使用 ViT-H 视觉编码器,名字带有 vit-G 的使用 ViT-G 视觉编码器;SDXL 大模型默认使用 ViT-G,SD15 大模型默认使用 ViT-H。
5.2 基础工作流
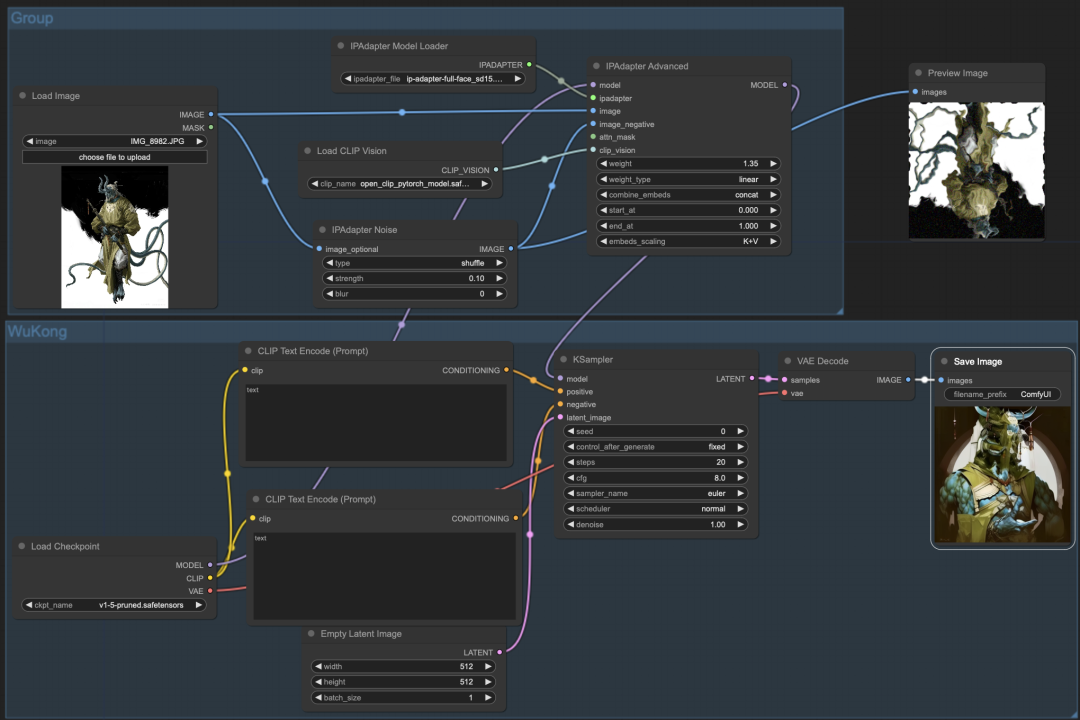
我们先从基础工作流开始,我们只使用 IPAdapter 引导图像扩散,而不使用提示词。
5.2.1 节点介绍
其主要在文生图的工作流上添加了以下几个节点:
#1. IPAdapter Advanced(应用IPAdapter(高级))
作用:读取并转换图像特征。
输入:
-
model:接受 Unet 模型的输入;
-
ipadapter:接受 ipadapter 模型;
-
image:接受图像的输入;
-
image_negative:接受负面图像输入,简单说就是传入不想要的元素。比如说我们不想要参考图的某种颜色,我们就可以将有该颜色的图片传入到 image_negative 中;
-
attn_mask:接受图像遮罩,收到后,只会识别图像遮罩的部分;
-
clip_vision:接受视觉编码器模型输入。
参数:
-
weight:参考权重;
-
weigth_type:IPA的权重类型;
-
combine_embeds:图像特征和其他问题提示词的组合方式;
-
start_at:作用开始时间;
-
end_at:作用结束时间;
-
emdeds_scaling:;
输出:
-
model:输出经过 ipadapter 引导的大模型。
#2. IPadpter Model Loader
作用:IPadpter模型加载器。
#3. Load CLIP Vision
作用:CLIP视觉模型加载器。
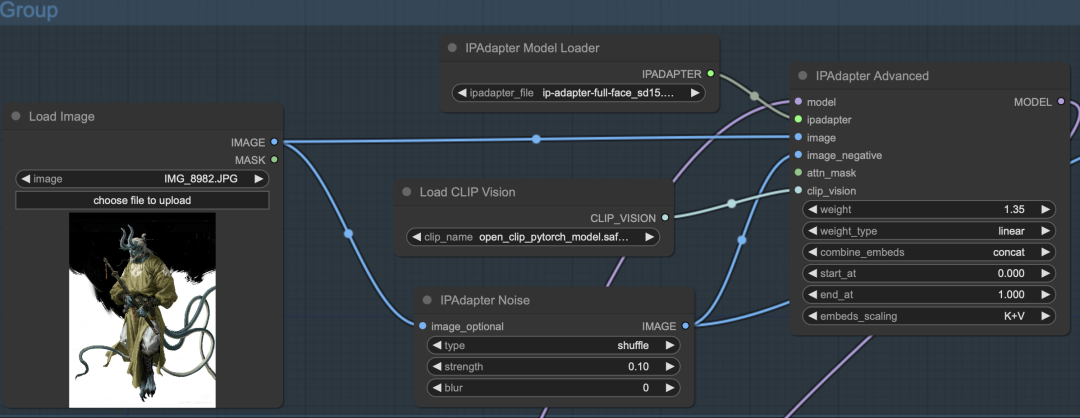
#4. Image_negative 插件
当然,我们还可以通过使⽤ image_negative 输⼊图像,以减少过拟合并使画⾯更加平滑。我们需要在原有的⼯作流中添加⼀个 IPAdapter Noise 节点,该节点会接收原始图像,将其翻转并添加噪声,然后将处理后的图像输⼊到 image_negative 中,从⽽对图像进⾏进⼀步的去噪和重绘。
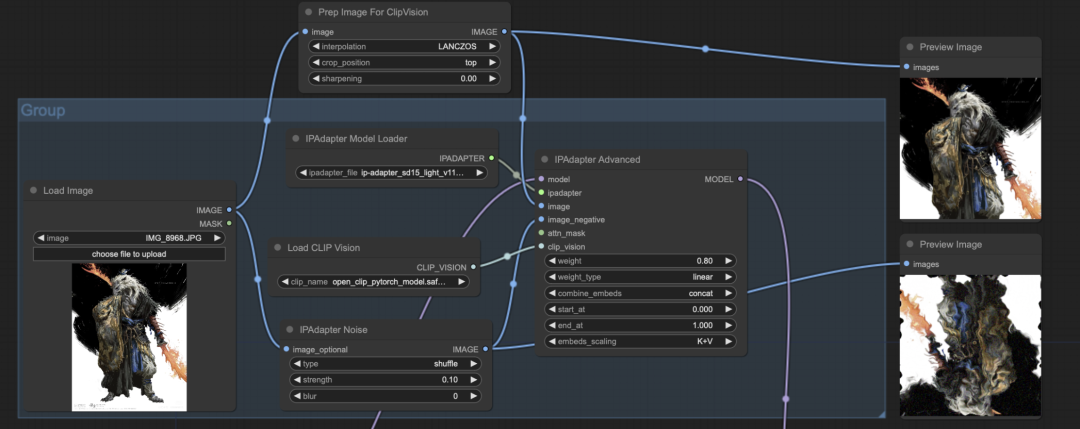
输入:
-
image_optional:接受原始图像输⼊。
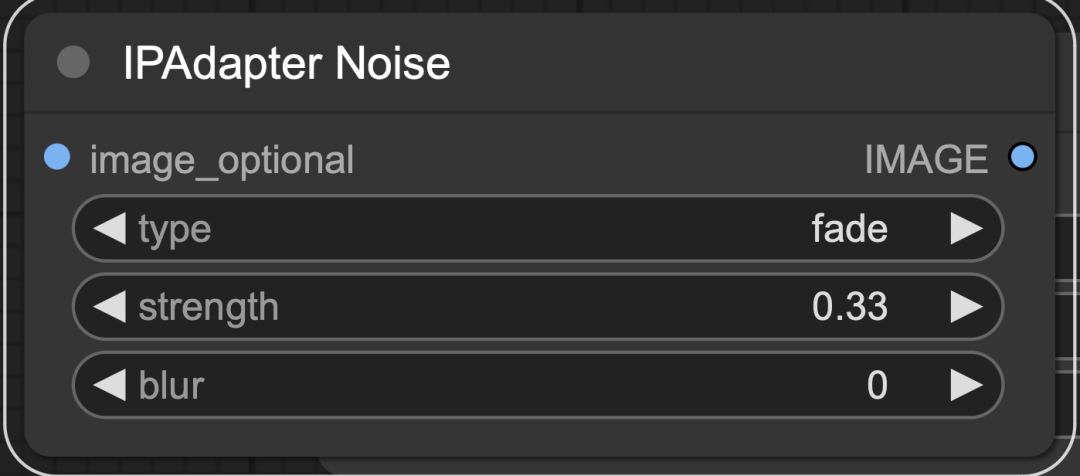
参数:
-
type:原始图像的类型;
-
strength:添加的噪波强度;
-
blur:输⼊图⽚的模糊程度。
输出:
-
image:添加噪波的图像。
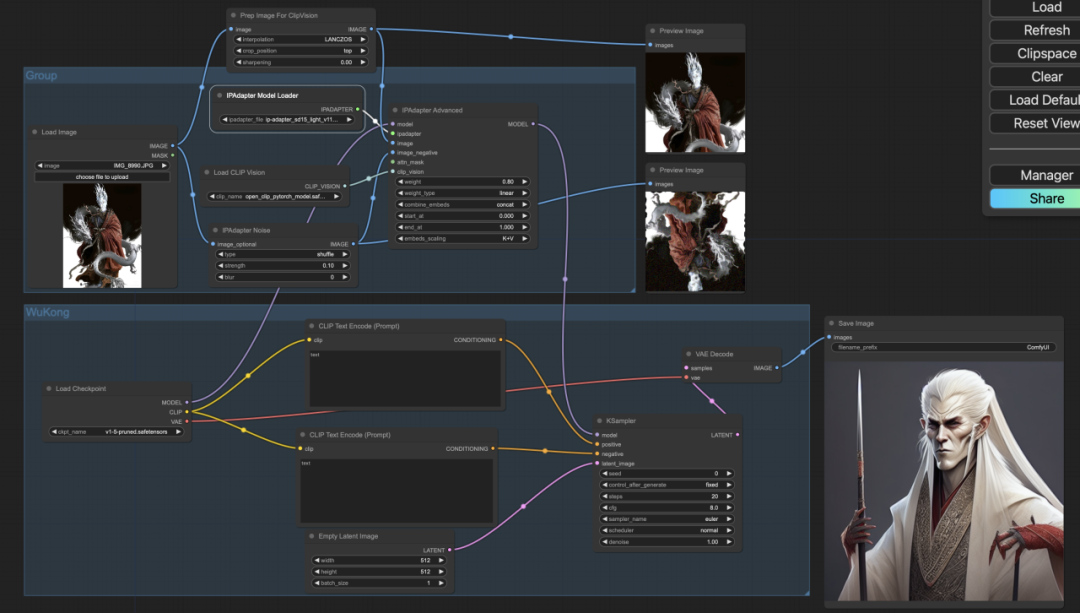
#5. 多张输⼊图像的参考
IPAdapter 能够同时参考多张图⽚的⻛格。借助 Batch Images(图像组合批次)节点输⼊多张参考图。我们以六个⼩boss为元素,想着合成⼀个具有它们六个邪恶属性的中级boss。
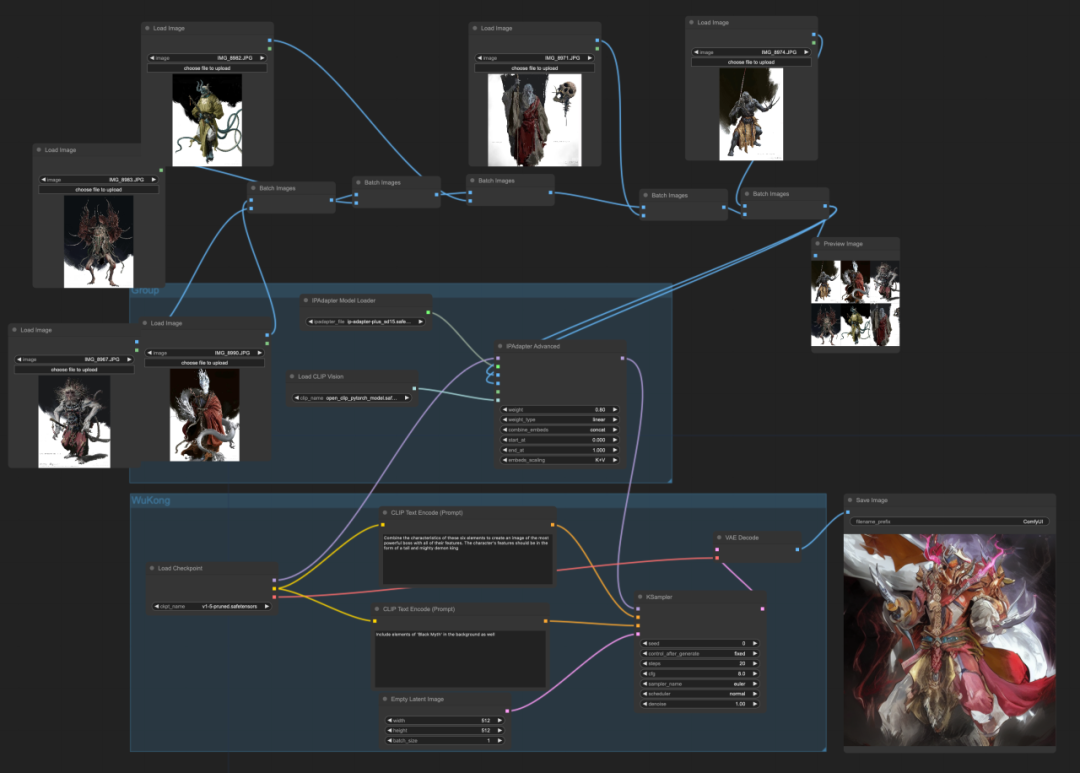
如果想看看所有boss 最终会进化成什么boss,欢迎小伙伴们自己动手尝试哦~
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









