







目录
(3)查准率(precision)、查全率(recall)与F1
(1)均方误差(Mean Squared Error, MSE)
前言
深度学习零基础论文看到头秃……因为没有系统学完就要磕论文,所以学得很艰难也很片面,望大佬们多多指教!!!
参考资料:《机器学习》 周志华著
一、神经网络
1、M-P神经元模型
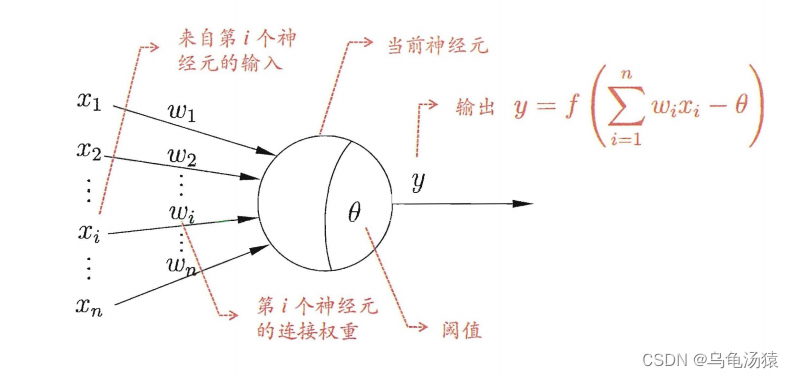
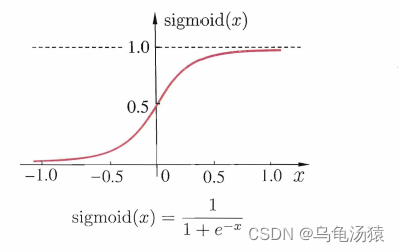
2、激活函数(activation function)
理想中的激活函数只有0和1两个输出值,0代表神经元抑制,1代表神经元兴奋,函数表达式为
二、机器学习
1、概念
2、分类及性能度量
分类(classification)可以理解为通过一个函数判断输入数据所属的类别,其输出值是离散值,是监督学习的代表。如果只涉及两个类别的判断称为“二分类”(binary classification),一般称其中一个类为“正类”(positive class),另一个称为“反类”(negative class);涉及多个类别的判断称为“多分类”(multi-class classification)。分类有以下几种性能度量:
(1)错误率(error rate)
(2)精度(accuracy)
(3)查准率(precision)、查全率(recall)与F1
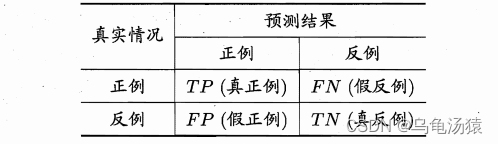
查准率P表示预测结果为正例的样本中真正是正例的样本所占的比例,即;
查全率R表示真正是正例的样本中预测结果为正例的样本所占的比例,即。
“P-R图”可以直观地展现出模型在样本总体上的查准率和查全率,也可以体现模型的性能优劣,具体不展开分析。
F1度量,其定义为: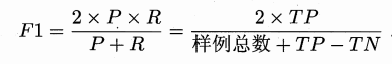
F1度量的一般形式: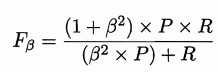
其中β > 0度量了查全率对查准率的相对重要性。 β = 1时退化为标准的 F1; β > 1时查全率有更大影响; β < 1时查准率有更大影响。
很多时候我们有多个二分类混淆矩阵,我们希望在 个二分类混淆矩阵上综合考察查准率和查全率。
一种直接的做法是先在各混淆矩阵上分别计算出查准率和查全率,记为 (P1, R1) ,(P2, R2),… ,(Pn, Rn) 再计算平均值,这样就得到"宏查准率" (macro-P) ,"宏查全率" (macro-R) ,以及相应的"宏F1" (macro-F1):
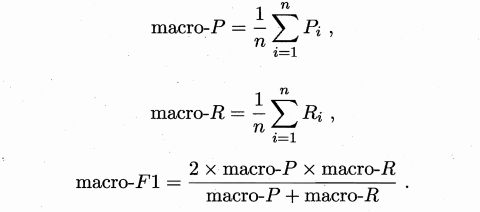
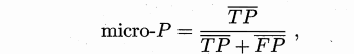

(4)ROC和AUC
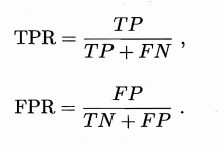
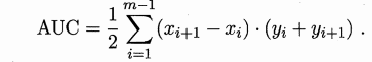
3、聚类及性能度量
聚类(clustering) 试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个"簇" (cluster)。通过这样的划分,每个簇可能对应于一些潜在的概念(类别),也就是就是根据规则划分,把样本相似度高的聚在同一类,把样本相似度低的聚在同一类。聚类结果应"簇内相似度" (intra-cluster similarity) 高且"簇间相似度" (inter-cluster similarity) 低,也就是“高内聚,低耦合”。
详细请参考:机器学习——聚类算法简单汇总_chelsea_tongtong的博客-CSDN博客_聚类模型算法
性能度量——JC、FMI、RI、DBI、DI
聚类性能度量亦称聚类"有效性指标" (validity index)。聚类性能度量大致有两类:一类是将聚类结果与某个"参考模型" (reference model) 进行比较,称为"外部指标" (external index); 另一类是直接考察聚类结果而不利用任何参考模型,称为"内部指标" (internal index)。




我的理解:对于外部指标来说,要想说明自己的模型跟参考模型近似,那么极端情况可以认为在自己的模型中属于一个簇的样本在参考模型中也在一个簇中,在自己的模型中不属于一个簇的样本在参考模型中也不在一个簇中,这种情况基本就是两个模型性能相当,如果认为参考模型近乎完美,那么自己的模型也就可以说近乎完美。所以说a和d值越大说明模型性能越好。
对于内部指标来说,我们追求地结果是“高内聚,低耦合”,所以说,簇内样本间距离要小,簇间样本间距离要大才是最好的。
三、KL散度和交叉熵
KL散度(Kullback-Leibler divergence) ,亦称相对熵(relative entropy) 或信息散度 (information divergence) ,可用于度量两个概率分布之间的差异。给定两个概率分布P和Q,二者之间的KL散度定义为,其中 p(x)和q(x) 分别为P和Q的概率密度函数。将其定义式展开可得
,其中 H(P) 为熵(entropy) ,H(P, Q) 的交叉熵(cross entropy)。 在信息论中,熵H(P) 表示对来自P的随机变量进行编码所需的最小字节数,而交叉熵H(P, Q) 则表示使用基于Q的编码对来自P的变量进行编码所需的字节数。
四、损失函数(loss function)
模型的损失函数(loss function)是用来表示模型预测值和训练样本之间的差异,我们的目的是通过降低这个损失函数来不断改进模型参数,使模型预测越来越准确。当然,不能只降低某个预测值的损失函数,而是应当降低所有样本的总体损失函数(overall loss function),即全部样本上损失函数的平均值或数学期望。
两种损失函数:
(1)均方误差(Mean Squared Error, MSE)
(2)交叉熵损失(cross-entropy loss)
Y表示真实值,y表示预测值。
详细请见原博客:神经网络中的损失函数_Zeii的博客-CSDN博客_神经网络中的损失函数
总结
只能说我看的论文中出现了这些概念就很片面地学习了一下,他们之间的关系如何我也没有细究(也就是标题分的可能比较乱),望大佬们多多指教!!!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









