






Java实现html页面抓取转PDF文档
1.引言:
前段时间公司需要。所以要捕捉页面生成PDF,查了很多资料。利用WkhtmltoPDF插件。环境用的是java 8,Spring Boot,Thymeleaf将页面转为PDF。
2.总纲:
大概总体步骤分为三步。
- 通过浏览器发送一个http请求到后台程序,并设置转PDF的位置及所创建的PDF的名称。
- 通过java代码调用Wkhtmltopd命令,然后读取发来的http的页面转为PDF文档。
- 最终生成后的PDF文档的下载路径。返回浏览器,供用户下载。
3.技术实现步骤
1) 首先需要安装WkhtmltoPDF插件。我们可以去官网下载自己对应的版本
官网下载地址:wkhtmltopdf
如果是给linux下载安装的话则下载linux的版本
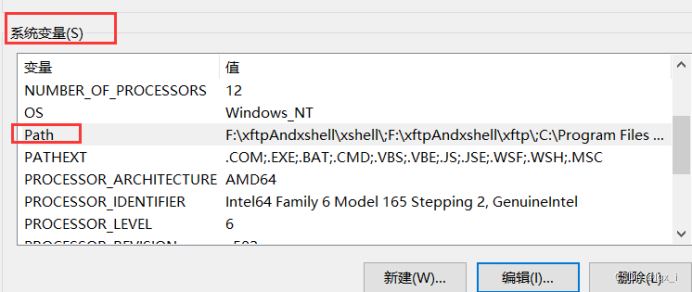
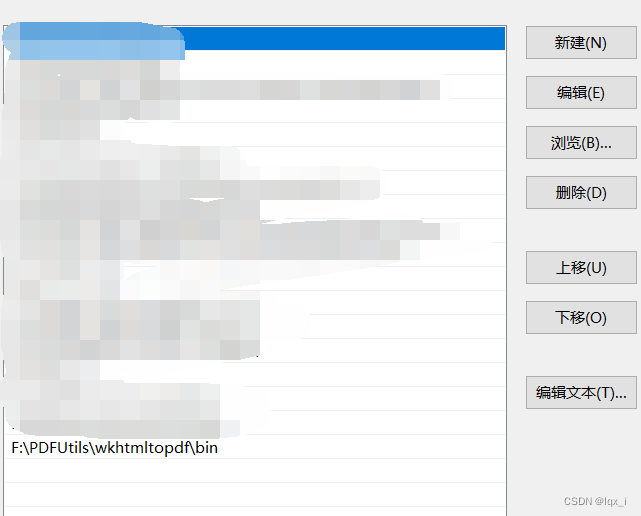
2)随后设置WkhtmltoPDF的环境变量。路径需要设置到安装完的bin文件夹

3)设置到系统变量中的Path中
之后我们就可以开发程序了
3.最后开发,本章用的是idea进行开发。
1)这里首先引入对应的依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.webjars</groupId>
<artifactId>bootstrap</artifactId>
<version>3.3.7</version>
</dependency>
3.1Controller层
package org.thinkingingis.controller;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import javax.servlet.http.HttpServletResponse;
import org.apache.tomcat.util.http.fileupload.IOUtils;
import org.springframework.boot.web.client.RestTemplateBuilder;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.client.RestTemplate;
import org.thinkingingis.model.PdfFileRequest;
import org.thinkingingis.service.PdfFileCreator;
@Controller
@RequestMapping("/print")
public class PrintPdfController {
private final RestTemplate restTemplate;
private final PdfFileCreator pdfFileCreator;
public PrintPdfController(RestTemplateBuilder restTemplateBuilder,PdfFileCreator pdfFileCreator) {
this.restTemplate = restTemplateBuilder.build();
this.pdfFileCreator = pdfFileCreator;
}
@RequestMapping(value = "/pdf", method = RequestMethod.GET)
public void createPdfFromUrl(HttpServletResponse response) {
PdfFileRequest fileRequest = new PdfFileRequest();
fileRequest.setFileName("index.pdf");
fileRequest.setSourceHtmlUrl("http://www.baidu.com");
pdfFileCreator.writePdfToResponse(fileRequest,response);
}
private void writePdfFileToResponse(byte[] pdfFile, String fileName, HttpServletResponse response) {
try (InputStream in = new ByteArrayInputStream(pdfFile)) {
OutputStream out = response.getOutputStream();
IOUtils.copy(in, out);
out.flush();
response.setContentType("application/pdf");
response.setHeader("Content-Disposition", "attachment; filename=\"" + fileName + "\"");
}
catch (IOException ex) {
throw new RuntimeException("PDF文件生成失败", ex);
}
}
}3.2 Service层
package org.thinkingingis.service;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
import java.util.List;
import java.util.concurrent.TimeUnit;
import javax.servlet.http.HttpServletResponse;
import org.apache.tomcat.util.http.fileupload.IOUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import org.thinkingingis.model.PdfFileRequest;
@Service
public class PdfFileCreator {
private static final Logger LOGGER = LoggerFactory.getLogger(PdfFileCreator.class);
public void writePdfToResponse(PdfFileRequest fileRequest, HttpServletResponse response) {
String pdfFileName = fileRequest.getFileName();
requireNotNull(pdfFileName, "The file name of the created PDF must be set");
requireNotEmpty(pdfFileName, "File name of the created PDF cannot be empty");
String sourceHtmlUrl = fileRequest.getSourceHtmlUrl();
requireNotNull(sourceHtmlUrl, "Source HTML url must be set");
requireNotEmpty(sourceHtmlUrl, "Source HTML url cannot be empty");
List<String> pdfCommand = Arrays.asList(
/*安装程序路径的bin文件夹下*/
"F:\\PDFUtils\\wkhtmltopdf\\bin\\wkhtmltopdf",
"--orientation",
"Landscape",
sourceHtmlUrl,
"F:\\公司程序\\测试工具项目\\Html转pdf\\spring-boot-htmltopdf\\"+pdfFileName
);
ProcessBuilder pb = new ProcessBuilder(pdfCommand);
Process pdfProcess;
int status;
try {
pdfProcess = pb.start();
try(BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(pdfProcess.getInputStream(), StandardCharsets.UTF_8))){
while (pdfProcess.isAlive()) {
while (bufferedReader.ready()) {
String s = bufferedReader.readLine();
}
}
status = pdfProcess.waitFor();
}catch (InterruptedException e) {
throw new RuntimeException("PDF generation failed");
}
//检测是否生成成功,如果成功则创建下载pdf的路径
if(status==0) {
File zipfile = new File("F:\\公司程序\\测试工具项目\\Html转pdf\\spring-boot-htmltopdf\\" + pdfFileName);
response.addHeader("Content-Disposition", "attachment;filename=" + new String(zipfile.getName().getBytes("UTF-8"), "ISO8859-1")); //转码之后下载的文件不会出现中文乱码
response.addHeader("Content-Length", "" + zipfile.length());
InputStream fis = new BufferedInputStream(new FileInputStream(zipfile));
byte[] buffer = new byte[fis.available()];
fis.read(buffer);
fis.close();
OutputStream toClient = new BufferedOutputStream(response.getOutputStream());
toClient.write(buffer);
toClient.flush();
toClient.close();
}
}
catch (IOException ex) {
throw new RuntimeException("PDF转化失败");
}
}
private void requireNotNull(String value, String message) {
if (value == null) {
throw new IllegalArgumentException(message);
}
}
private void requireNotEmpty(String value, String message) {
if (value.isEmpty()) {
throw new IllegalArgumentException(message);
}
}
private void writeCreatedPdfFileToResponse(InputStream in, HttpServletResponse response) throws IOException {
OutputStream out = response.getOutputStream();
IOUtils.copy(in, out);
out.flush();
out.close();
}
private void waitForProcessBeforeContinueCurrentThread(Process process) {
try {
process.waitFor(2, TimeUnit.SECONDS);
}
catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
private void requireSuccessfulExitStatus(Process process) {
if (process.exitValue() != 0) {
throw new RuntimeException("PDF生成失败");
}
}
private void setResponseHeaders(HttpServletResponse response, PdfFileRequest fileRequest) {
response.setContentType("application/pdf");
response.setHeader("Content-Disposition", "attachment; filename=\"" + fileRequest.getFileName() + "\"");
}
private void writeErrorMessageToLog(Exception ex, Process pdfProcess) throws IOException {
LOGGER.error("无法创建PDF ", ex);
String errorMessage = getErrorMessageFromProcess(pdfProcess);
LOGGER.error("PDF进程结束错误信息呢: ", errorMessage);
}
private String getErrorMessageFromProcess(Process pdfProcess) {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(pdfProcess.getErrorStream()));
StringWriter writer = new StringWriter();
String line;
while ((line = reader.readLine()) != null) {
writer.append(line);
}
return writer.toString();
}
catch (IOException ex) {
LOGGER.error("无法从进程中提取错误消息", ex);
return "";
}
}
}自此,可以运行项目访问http://localhost:8080/print/pdf路径后,则会返回下载百度的页面的pdf文档。也可以根据自己的项目修改其中部分逻辑。














 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









