







XML处理在GeoTools中的重要性是如此之高,以至于其在文档中专门开辟了一个专门的章节来系统性地解释相关的架构思路和问题。
文章目录
1. 前言
关于XML处理,在GeoTools中的重要性是如此之高,以至于其在文档中专门开辟了一个专门的章节来系统性地解释相关的架构思路和问题。
XML处理相关的理论基础,其实在GeoTools的文档中已经解释地足够清楚了;本文我们将从实践的角度出发,尝试捋清楚GeoTools自创的GTXML技术是如何设计XML处理的。(GTXML: GeoTools XML)
本文也是"GeoServer如何进行返回值处理的技术基础"的基石之一,透彻理解有助于增加我们在进行相关扩展时候的工具箱选项。
2. 概述
抛开GeoTools,在程序语言中对于XML的处理需求无外乎两种:将XML字符转换为对应的内存对象,以及将内存对象转换为XML字符的逆操作。
对于以上两个操作,GTXML给出的解决思路是:基于Java的SAX模式,采用 XML Schema assisted parse 技术,通过引入Binding概念,使得XML处理在性能,可扩展性,代码可读性,开发便捷性等之间找到一个平衡点。具体的技术栈比较读者可以查看官方给出的清单。
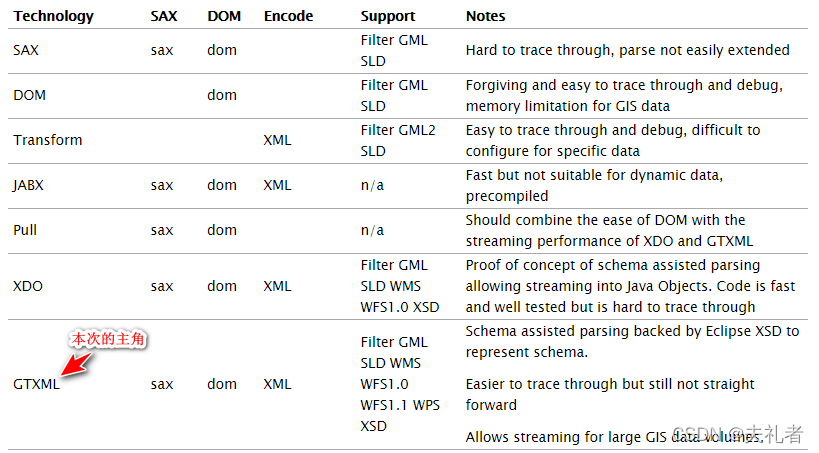
正式开始介绍前,为了给读者一个全面的印象,先给出一份概述性表格:
| 类别 | 关键类 | Binding方法 | SAX | 备注 |
|---|---|---|---|---|
| XML >>> Java Bean | org.geotools.xsd.Parser | parse | javax.xml.parsers.SAXParser | 在SAX事件响应中进行XML解析 |
| Java Bean >>> XML | org.geotools.xsd.Encoder | encode / getProperties / getProperty | javax.xml.transform.sax.TransformerHandler | 需要主动调用对应的SAX方法来写入XML文档内容 |
3. 前置知识
以下这些知识我们先只作概述性介绍,一来它们是理解接下来的解读流程中所必须的,二来避免陷入细节上的误区。更多的细节我们将留待本文最后的专门小节中进行详细解释。
| 概念 | 概述 | 补充 |
|---|---|---|
| XSD | a. XSD全称为"XML Schema Definition",用于描述 XML 文档的结构。 b. 基于XSD特性,GTXML选择使用XML Schema assisted parse 技术,以实现xml文档与Java Bean之间的相互转换。 c. 一份xsd文件中会详细定义和说明旗下所拥有的类型。这样就让xsd所描述的xml节点和相应的java对象作一一对应成为可能。 | w3school - XSD教程 |
| SAX | a. SAX(simple API for XML)是一种XML解析的替代方法。相比于DOM,SAX是一种速度更快,更有效的方法。它逐行扫描文档,一边扫描一边解析。 b. 当解析器发现元素开始、元素结束、文本、文档的开始或结束等时,发送事件,程序员编写响应这些事件的代码,保存数据。 | a. 在java中使用sax解析xml b. Java SAX生成和解析XML(对SAX不熟悉的同学可以用该文的样例代码快速理解SAX执行逻辑) |
| Binding | 基于上述XSD特性,GTXML选择抽象出Binding的概念。而且官方文档中已经解释得很清楚了:“each binding maps an XML elements or XML attributes to Java class.”。大致意思就是每个Binding作为桥梁,将一个XML节点或属性与一个对应的Java类关联起来,它们之间的相互转换逻辑就在对应的Binding实现类中完成。 | GeoTools - bindings |
| EMF | a. Eclipse Modeling Framework (EMF),简单的说,就是Eclipse提供的一 套建模框架,可以用EMF建立自己的UML模型,设计模型的XML格式或编写模型的java代码。 b. EMF提供了方便的机制,实现了功能的相互转换,大大提高了效率。 EMF统一了UML,XML,Java 。 c. 对于初学者,针对EMF的了解到这里就可以了。 | EMF官网 |
4. 用例准备
正式开始我们的解读操作。
首先让我们看看本次的测试用例。为了确保相关用例获取的便捷性,笔者这里直接使用GeoServer源码所提供的相关单元测试用例GetFeatureTest.testPost() 。
5. XML >>> Java Bean
按照用例的执行时序,首先肯定是将前端传递来的xml字符转换为Java Bean对象。
以下是本次传递的XML字符串:
<wfs:GetFeature service='WFS' version='2.0.0'
xmlns:cdf='http://www.opengis.net/cite/data'
xmlns:wfs='http://www.opengis.net/wfs/2.0' >
<wfs:Query typeNames='cdf:Other'>
<wfs:PropertyName>cdf:string2</wfs:PropertyName>
</wfs:Query>
</wfs:GetFeature>
5.1 SAX模式预热
GeoTools基于Java SAX模式来解决XML处理问题的,所以针对上述XML字符串,我们首先看看在SAX模式下的解析顺序:
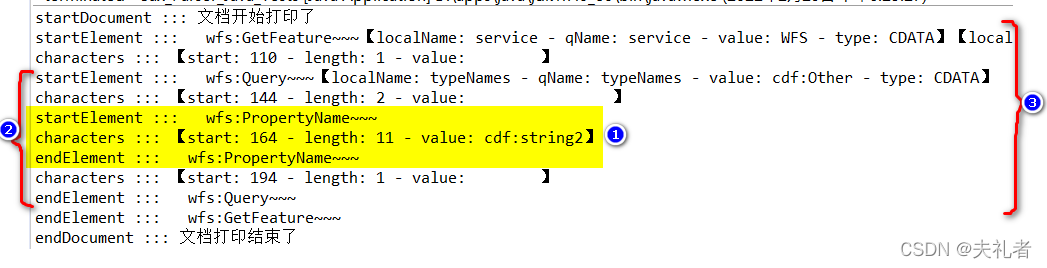
上图中的执行顺序,呈现出非常明显的递归调用:
startDocument
startElement:::wfs:GetFeature
characters:::wfs:GetFeature
startElement:::wfs:Query
characters:::wfs:Query
startElement:::wfs:PropertyName
characters:::wfs:PropertyName
endElement:::wfs:PropertyName
characters:::wfs:Query
endElement:::wfs:Query 生成queryTypeImpl实例
endElement:::wfs:GetFeature 生成getFeatureTypeImpl实例
endDocument
基础性的SAX执行逻辑到此为止,接下来就让我们看看GeoTools是如何基于上述流程来架构自己的XML处理逻辑的。
针对"XML -> Java Bean"的反序列化操作,在GeoTools中对应的处理门面类型是org.geotools.xsd.Parser 。
执行上面的单元测试样例,按照SAX模式原理,我们针对主要解析事件进度对应解读:
5.2 startDocument事件
经过断点调试,我们可以得到以下典型堆栈图:
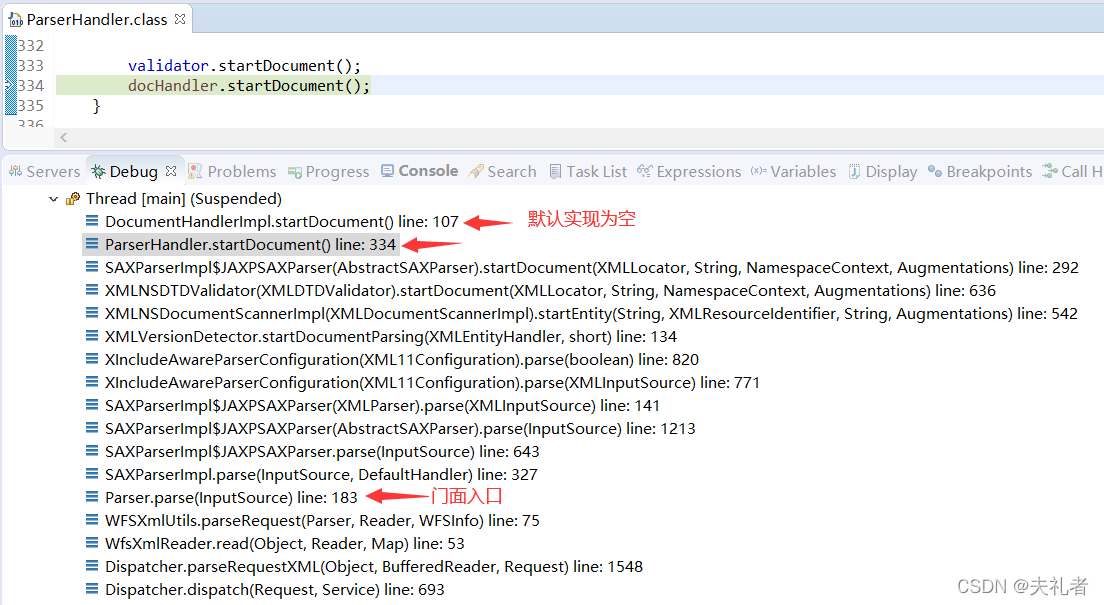
上面堆栈图中的门面类Parser的入口方法parse(InputSource source)如下:
public Object parse(InputSource source)
throws IOException, SAXException, ParserConfigurationException {
// 实例化 javax.xml.parsers.SAXParser, 准备开始使用SAX解析传入的XML源(也就是上面传入的XML字符串)
parser = parser();
// handler也就是上面堆栈图中ParserHandler, 其继承自JDK中的DefaultHandler2类, 在本方法中以ContentHandler角色出现, 所谓的SAX响应事件就是由它来完成的.
// 所以说: Parser作为门面入口, 真正的调度工作其实是在ParserHandler中完成的
parser.parse(source, handler);
// 获取到解析出来的Java Bean
return handler.getValue();
}
大致介绍下在ParserHandler.startDocument()完成的主要操作:
// ParserHandler.java
@Override
public void startDocument() throws SAXException {
// 这个方法中会进行几个重要的初始化操作:
// 1. 从Config中加载出预先定义的bindings集合。(重要)
// 2. 初始化全局字段,handlerFactory,bindingLoader,bindingWalker 。这三个作用名称已经说明得很清楚了。大部分还是和Binding强相关.
// perform the configuration
configure(config);
// create the document handler + root context
DocumentHandler docHandler = handlerFactory.createDocumentHandler(this);
context = new DefaultPicoContainer();
...... 向容器中注入一系列组件, 用作之后的解析操作取用
// 将执行控制权转交给GeoTools自定义的DocumentHandler同名方法`startDocument()`, 实际实现为空
validator.startDocument();
docHandler.startDocument();
}
因此在startDocument事件响应操作中,主要完成的是初始化相关组件,为接下来的解析操作打基础。
涉及到的典型类型:
DocumentHandler。MutablePicoContainer。GeoTools内部使用的容器,类似Spring容器。但看实际应用,感觉上像想要使用jdk Map容器替换掉。ValidatorHandler。 基于SAX模式进行的文档校验。非常好的职责分离设计,将校验逻辑抽取到该专门的类中完成。ContextCustomizer。 留给外部的扩展性接口,用于对上面刚刚提到的MutablePicoContainer容器实例进行扩展。
5.3 startElement 事件
经过断点调试,我们可以得到以下典型堆栈图:
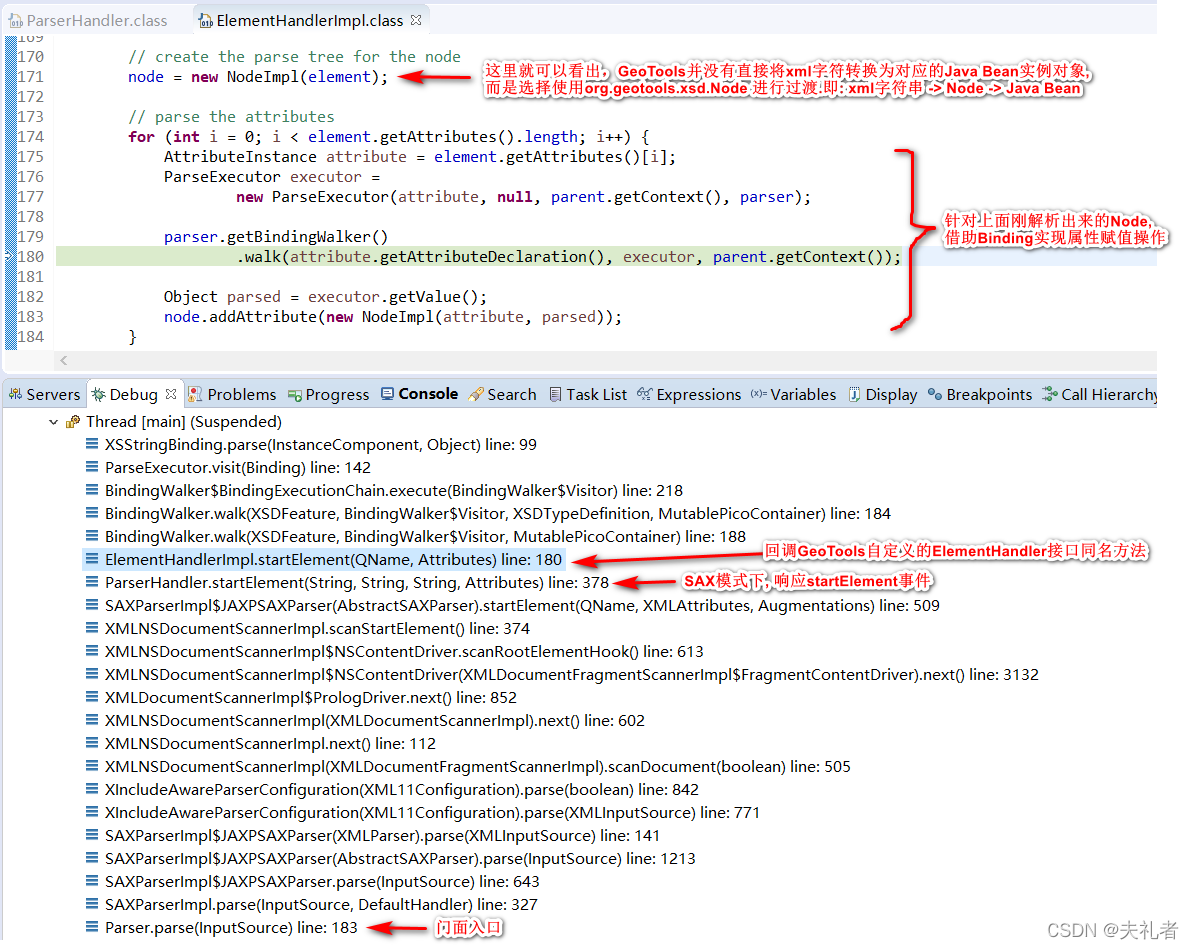
对于以上堆栈图,我们需要分别两大块进行解读:
-
首先是
ParserHandler.startElement()方法,作为startElement事件的直接响应者。// ParserHandler.java @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { // 加载本次xml字符串中声明的, 相关xsd文件 boolean root = loadSchemas(uri, attributes); ...... String prefix = namespaces.getPrefix(uri); QName qualifiedName = prefix != null ? new QName(uri, localName, prefix) : new QName(uri, localName); // 最大可能性地找出处理当前xml node的Handler // get the handler at top of the stack and lookup child ElementHandler handler = getHandler(attributes, root, qualifiedName); if (handler != null) { ...... // 控制权转交给找到的Handler, 实际类型为: ElementHandlerImpl ; 下面会马上介绍到 // signal the handler to start the element, and place it on the stack handler.startElement(qualifiedName, attributes); handlers.push(handler); } else { String msg = "Handler for " + qName + " could not be found."; throw new SAXException(msg); } } -
然后就是
ElementHandler.startElement()方法。// ElementHandlerImpl.java @Override public void startElement(QName qName, Attributes attributes) throws SAXException { // create the attributes List<AttributeInstance> atts = new ArrayList<>(); // attributes实际就是从XSD文件中解析出来的当前element所拥有的Attributes // 接下来我们就依次迭代每个attribute for (int i = 0; i < attributes.getLength(); i++) { String rawAttQName = attributes.getQName(i); ...... String uri = attributes.getURI(i); String name = attributes.getLocalName(i); QName attQName = new QName(uri, name); // content类型为: XSDElementDeclaration // 从XSD文件中读取出当前Attribute的定义 XSDAttributeDeclaration decl = Schemas.getAttributeDeclaration(content, attQName); if (decl != null) { AttributeInstance att = new AttributeImpl(decl); att.setNamespace(decl.getTargetNamespace()); att.setName(decl.getName()); att.setText(attributes.getValue(i)); atts.add(att); } else { parser.getLogger().warning("Could not find attribute declaration: " + attQName); } } // 使用 ElementImpl类型实例 封装上面检索出来的XSDElementDeclaration和XSDAttributeDeclaration // create the element element = new ElementImpl(content); element.setNamespace(qName.getNamespaceURI()); element.setName(qName.getLocalPart()); element.setAttributes(atts.toArray(new AttributeInstance[atts.size()])); // 相较于直接将xml字符串转换为java bean , geotools选择抽象出org.geotools.xsd.Node概念作为中转/缓冲, 这样就形成了 xml string -> Node -> java bean 的转换关系. // 而且注意观察Node接口的定义, GeoTools选择在Node中持有解析完毕的java bean对象的. ( 更具体细节可以查看下方要讲到的 endElement(QName qName) 方法解读 ) // create the parse tree for the node node = new NodeImpl(element); // 使用Binding解析上面从XSD中读取到的各Attribute, 这一步正是体现了getoools中Binding的用途; 因为针对不同的attribute, 其拥有不同的类型; 针对客户端传递来的字符串进行对应转换时候, 肯定有着各自不同的逻辑. // parse the attributes for (int i = 0; i < element.getAttributes().length; i++) { AttributeInstance attribute = element.getAttributes()[i]; ParseExecutor executor = new ParseExecutor(attribute, null, parent.getContext(), parser); // Visitor模式解析出当前attribute的真实值, ParseExecutor就是本次的Visitor parser.getBindingWalker() .walk(attribute.getAttributeDeclaration(), executor, parent.getContext()); // 获取解析出来的值 Object parsed = executor.getValue(); node.addAttribute(new NodeImpl(attribute, parsed)); } ...... // 通知父Handler, 本Handler开始执行 // "start" the child handler parent.startChildHandler(this); }
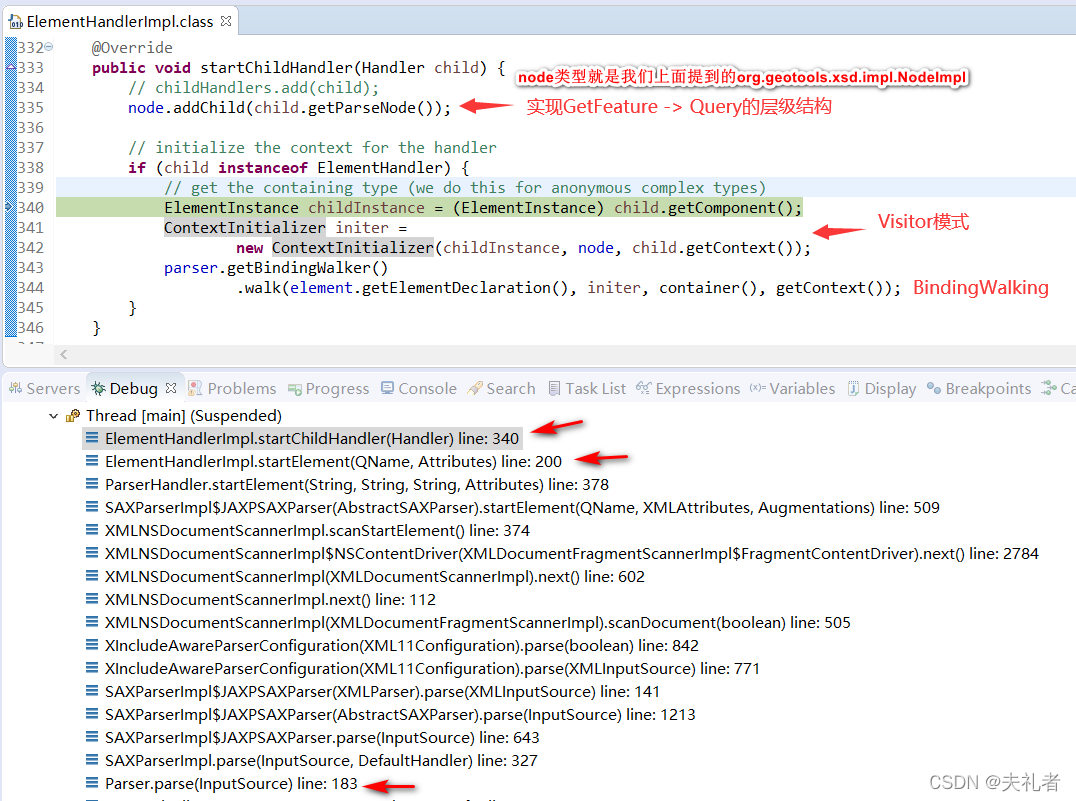
典型类型:
ParserHandler。前面已经介绍过了,该类属于SAX事件的直接响应者,处理控制权是由它转交给Handler的。ElementHandlerImpl。 内部不少为全局字段,且主体方法也是操作这些字段,说明该类实例属于prototype类型,每次使用都生成全新的。注意到其内部有一个类型为org.geotools.xsd.impl.NodeImpl的字段,其含义参见上面的代码部分。ParseExecutor。 实现了BindingWalker.Visitor。 访问者模式的实际参与者。
关于代码parent.startChildHandler(this);实现中出现的node.addChild()操作,我们引用上面提到的SAX流程进行一次专门解读:
startDocument
startElement:::wfs:GetFeature 创建出root Node,本例中是GetFeature
characters:::wfs:GetFeature
startElement:::wfs:Query node , 解析出来之后, ElementHandlerImpl 会调用parent handler的 startChildHandler(Handler child) 来将自身这个node作为child node 加入到 父级node(也就是 GetFeature Node)中
characters:::wfs:Query
startElement:::wfs:PropertyName node, 逻辑同上,将自身作为child node 加入到父级node(也就是 query Node)中 ;;; 这也是为啥ParserHandler中会维持一个Stack
characters:::wfs:PropertyName
endElement:::wfs:PropertyName
characters:::wfs:Query
endElement:::wfs:Query 生成queryTypeImpl实例 ; 当逻辑执行到这里的时候, 对应的node肯定是填充完毕的;;; 这一点很重要,因为在这一步中, 对应的binding会依据这个node进行Java Bean对象属性的赋值 (重要)
endElement:::wfs:GetFeature 生成getFeatureTypeImpl实例
endDocument
5.4 characters事件
经过断点调试,我们可以得到以下典型堆栈图:
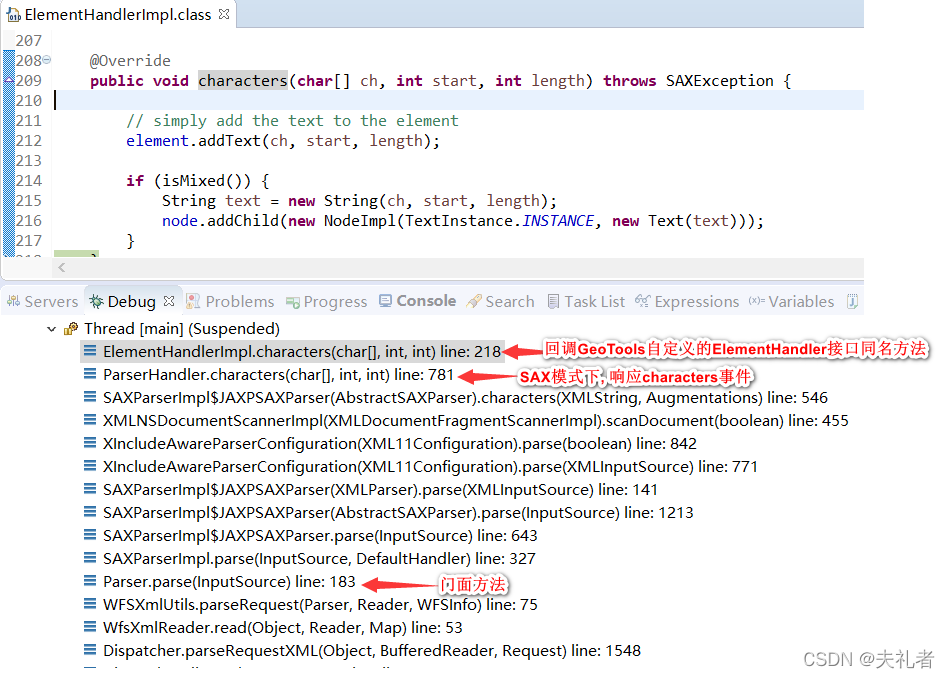
逻辑实现相当简单,不作专门解读。
5.5 endElement事件
经过断点调试,我们可以得到以下典型堆栈图:
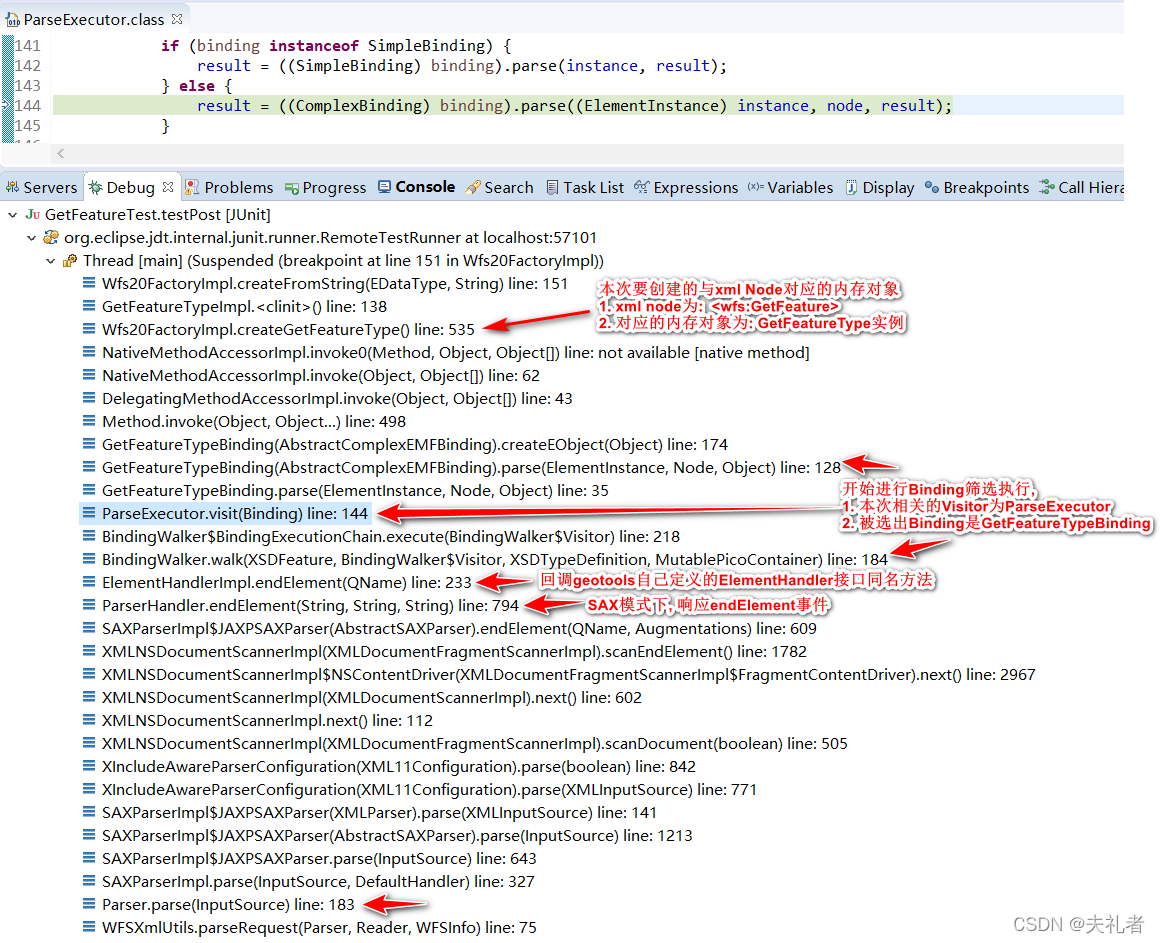
以上堆栈图中,我们注意一下 ElementHandlerImpl.endElement(QName qName)方法。本方法中,我们将实例化出xml 字符串所对应的java bean对象,诸如本例中的GetFeatureTypeImpl,QueryTypeImpl实例。(是的,这和第一印象里"应该在startElement"是相违背的)。
// ElementHandlerImpl.java
@Override
public void endElement(QName qName) throws SAXException {
// 本次的Visitor
// ================= 重要
// 对于ParseExecutor的调用,会触发Binding的parse操作, 进而导致复杂对象的实例化操作, 例如本例中的 GetFeatureTypeImpl实例, 以及QueryTypeImpl实例
ParseExecutor executor =
new ParseExecutor(element, node, getParentHandler().getContext(), parser);
parser.getBindingWalker()
.walk(
element.getElementDeclaration(),
executor,
container(),
getParentHandler().getContext());
// 获取到通过Visitor解析出来的java bean, 注意这个value为全局字段
// cache the parsed value
value = executor.getValue();
// 让Node持有解析完毕的java bean
// set the value for this node in the parse tree
node.setValue(value);
// 通知父Handler, 本Handler任务结束
// end this child handler
parent.endChildHandler(this);
// kill the context
parent.getContext().removeChildContainer(getContext());
}
关于这个违背了第一印象的实例化操作,之后我们会在专门的Binding小节进行相关的解释。
5.6 endDocument()事件
经过断点调试,我们可以得到以下典型堆栈图:
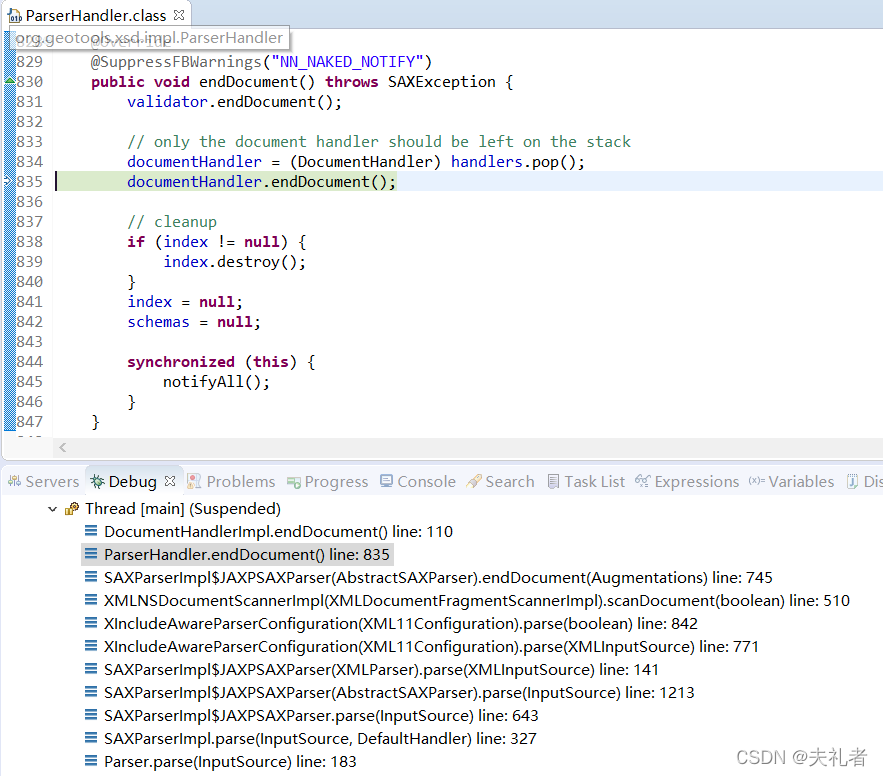
这个主体逻辑也不复杂,相关的DocumentHandler.endDocument()默认实现也是空的,因此这里也不再进行额外的阐述。
6. Java Bean >>> XML
本文至此,内容已经足够多了,这部分内容就留到下一篇博客了。
7. 知识点补足
7.1 关于XSD
w3school对于XSD的介绍:
- XML Schema 是基于 XML 的 DTD 替代者。
- XML Schema 描述 XML 文档的结构。
- XML Schema 语言也称作 XML Schema 定义(XML Schema Definition,XSD)。
Xml Schema的用途:
- 定义一个Xml文档中都有什么元素。
- 定义一个Xml文档中都会有什么属性。
- 定义某个节点的都有什么样的子节点,可以有多少个子节点,子节点出现的顺序。
- 定义元素或者属性的数据类型。
- 定义元素或者属性的默认值或者固定值。
根据以上XSD用途的介绍和说明,我们可以很自然地想到 —— ”基于XSD说明,可以将每个XML文档节点和面向对象语言中的一个类型进行对应“。
- 在两者之间建立转换关系,在理论上是完全可行的。 这就是GTXML中所提出的"Binding"概念。
- 基于XSD说明,应该存在一种通用的方式生成对应的静态语言对象;反过来应该也是可以的。这就是我们上面提到过一点的 EMF(Eclipse Modeling Framework) 。
7.2 关于Binding
官方文档中已经解释得很清楚了:“each binding maps an XML elements or XML attributes to Java class.”。大致意思就是每个Binding作为桥梁,将一个XML节点或属性与一个对应的Java类关联起来,它们之间的相互转换逻辑就在对应的Binding实现类中完成。
为了加速理解,额外补充一些的是:
- XML节点和Java类型关联关系的建立, geotools提供了
Configuration抽象类,更具体是registerBindings方法;同时也是在Configuration抽象类中,为了复用已存在的关联关系,子类可以通过调用addDependency(Configuration dependency)来复用其它Configuration的实现。相关范例可以参见对应本文用例的WFSConfiguration。 - 为了在运行时更好的进行Binding筛选和执行,GeoTools分别提供了
BindingLoader和BindingWalker。上文中在startDocument事件的响应中,主要工作之一就是组装好这两个实例。 - 在之前的解读中一再被提及的Visitor模式,其对应接口
BindingWalker.Visitor,所定义的唯一方法visit, 唯一方法入参正是Binding类型。 Binding接口没有直接实现类,相对应的是两个子接口SimpleBinding和ComplexBinding,其它的Binding实现类必然是这两个子接口实现者之一。
a. 这两个子接口中都定义了名为parse和encode的两个方法,区别在于各自的方法参数不同。
b. 即使只看方法名都知道,xml -> object 调用的是parse,object -> xml 调用的则是 encode。
c. 至于ComplexBinding接口中定义的其它诸如getProperties, getProperty方法,就留待下一篇博客中进行介绍了。
7.2.1 BindingWalker.Visitor接口
作为访问者模式的实现者,虽然是一个内部类,但其实现者并不少:

- 注意看该接口所所定义的方法,其唯一入参为
Binding类型,所以实际的binding调用是由这些Visitor决定的。 - xml处理逻辑被放到了Binding中,但调用时机又被转交给了Visitor ;
BindingLoader和BindingWalk则是负责加载和迭代 ; 另外在BindingWalker中,经过筛选迭代出来的bindings也不是直接调用,而是使用BindingWalker.BindingExecutionChain进行再一次封装。 - 仔细观察上面的继承树,虽然数量不少,但大体上其实可以分为两类:
a.ParseExecutor使用在 xml -> object流程中,这一点可以从其命名以及内部实现中调用Binding.parse可见一二。
b.ElementEncodeExecutor这样的则是使用 object -> xml过程中。
7.3 关于ParserHandler`
关于这个类型,上面已经有所提及,Parser只是对外提供的XML字符解析的门面,作为SAX模式的实际事件响应者,org.geotools.xsd.impl.ParserHandler维护着实际的响应逻辑。
8. 总结
GeoTools里XML的解析之所以会感觉比较绕,一来是因为XML解析自带的递归特性,二则是GeoTools为了增加XML处理上的灵活性,可调试性,性能等优势,而选择采取SAX这种事件响应式的流式处理方式,三则是Binding调用执行时的Visitor模式,在不了解其思路前,断点的反复命名会让人容易摸不着头脑。对此初学者而言,推荐先阅读这篇官方文档。
这里我们尝试做下总结:
- GTXML借助SAX模式进行XML文档的解析。
- GTXML使用
ParserHandler类来负责调度对于SAX响应事件的响应。 - Java Bean对象的创建和赋值主要发生在
endElement事件响应中,而在startElement事件响应中,主要完成的是对于xml节点内存对象org.geotools.xsd.Node的填充,以在之后进行的endElement事件响应中将值对应赋值给Java Bean对象。(Node类中的字段) - 针对binding,在xml -> object的流程中,调用的是其parse方法。对于Java Bean对象而言,其所对应的Binding一定是
ComplexBinding的子类,而在本例中,我们所需要的ComplexBinding都属于AbstractComplexEMFBinding的子类。而在AbstractComplexEMFBinding实现的parse方法中,就完成了java bean的创建,以及对应属性的赋值。
a. 对象创建使用的是Factory模式,本例中对应的是Wfs20FactoryImpl类;
b. 而对象属性的赋值则是采用的EMF方法,关于这一点初学者当前不用关心。唯一需要留意的是属性赋值过程中,强依赖于我们前面提到过的node对象,所以当代码逻辑执行到这里的时候,node对象可以肯定是被填充完毕的。 - 每份XSD所对应的binding集合,则是由使用者通过继承自
org.geotools.xsd.Configuration抽象类来进行注册的。 - 最终的整体流程概述,这里直接贴一下官网的示意图。
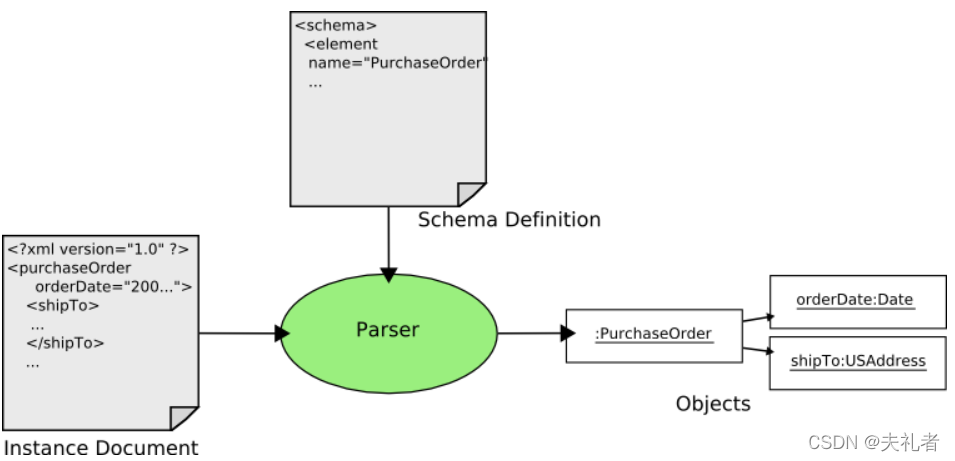
最后给出一份针对上面的用例XML文档的最简转换代码:
org.geotools.wfs.v2_0.WFSConfiguration config = new org.geotools.wfs.v2_0.WFSConfiguration();
Parser parser = new Parser(config);
// xml -> object
Object parsed = parser.parse(new StringReader(xml));


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









