







 本文介绍了Huffman编码的原理,它是一种基于信源概率统计的无失真编码方式,通过创建Huffman树来实现。实验流程包括编码和解码两部分,通过扫描文件计算字符频率,构建Huffman树,并进行编码和解码操作。程序通过C语言实现,包含主工程和库工程,支持命令行参数解析,能够对文件进行Huffman编码和解码。
本文介绍了Huffman编码的原理,它是一种基于信源概率统计的无失真编码方式,通过创建Huffman树来实现。实验流程包括编码和解码两部分,通过扫描文件计算字符频率,构建Huffman树,并进行编码和解码操作。程序通过C语言实现,包含主工程和库工程,支持命令行参数解析,能够对文件进行Huffman编码和解码。
一.实验原理
1.Huffman编码
(1) Huffman Coding(霍夫曼编码)是一种无失真编码的编码方式,Huffman编码是可变字长编码(VLC)的一种。
(2) Huffman编码基于信源的概率统计模型,它的基本思路是,出现概率大的信源符号编长码,出现概率小的信源符号编短码,从而使平均码长最小。
(3)在程序实现中常使用一种叫做树的数据结构实现Huffman编码,由它编出的码是即时码。
2.Huffman编码方法
(1)将文件以ASCII字符流的形式读入,统计每个符号的发生频率;
(4)重复3,直到最后得到和为1的根节点;
3.Huffman编码的数据结构
(1)Huffman节点结构
typedef struct huffman_node_tag
{
unsigned char isLeaf; //是否为树叶(叶节点),1代表是,0代表否
unsigned long count; //节点代表的符号加权和
struct huffman_node_tag *parent; //父节点指针
union //共同体
{
struct
{
struct huffman_node_tag *zero, *one; //如果不是叶节点,则此项为该节点左右孩子指针
};
unsigned char symbol; //若是叶节点,则此项为symbol,表示某个信源符号(1字节)
};
} huffman_node;
(2)Huffman码结构
typedef struct huffman_code_tag
{
/* The length of this code in bits. */
unsigned long numbits; //码字长度,单位:位
/* 码字的第1位存于bits[0]的第1位,
码字的第2位存于bits[0]的第的第2位,
码字的第8位存于bits[0]的第的第8位,
码字的第9位存于bits[1]的第的第1位 */
unsigned char *bits; //指向该码比特串的指针
} huffman_code;
二.试验流程
1.Huffman编码流程
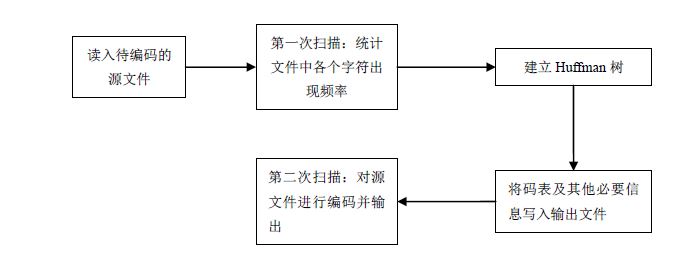
2.Huffman解码流程
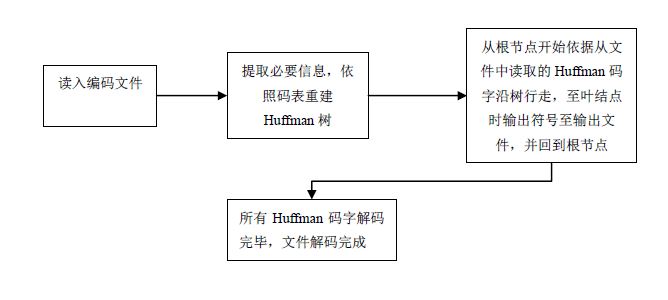
三.主要代码分析
该程序包括两个工程,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1474
1474

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









