







来由
调用一个外部接口,偶然遇到响应的header里面content-encoding为br(如下图),一般而言,这个值是常见的gzip等,起初并未在意。
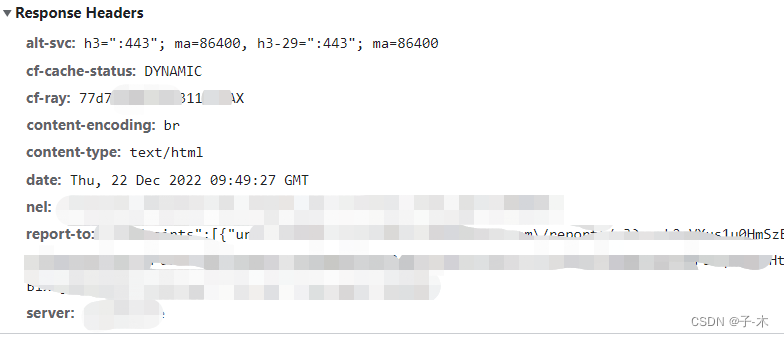
后来解析接口response body的时候,自然而然的使用String content = org.apache.http.util.EntityUtils.toString(response.getEntity(), CHARSET)转String,然而如看官所愿,大意了,怎么都是乱···码!!!
第一时间以为是编码方式(很正常的吧^^),好吧,仔细看响应,content-type简单的text/html,居然没有指定charset,懵逼了,没有编码方式。。。国际惯例utf-8都不能解析?于是其他的接口(如下图)跟这个接口比对,终于发现了该接口指定了一个content-encoding=br,太特殊了。
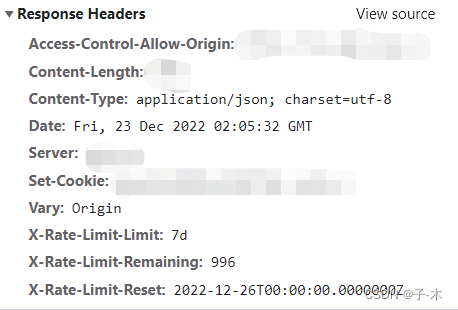
于是Bing一下,找到了 Content-Encoding的说明,原来值br表示是采用了 Brotli 算法的编码方式。
Brotli算法
Brotli是一种全新的数据格式,可以提供比Zopfli高20-26%的压缩比。据谷歌研究,Brotli压缩速度同zlib的Deflate实现大致相同,而在Canterbury语料库上的压缩密度比LZMA和bzip2略大。 链接:Google开源Brotli压缩算法 微软使用了一种基于谷歌提供的C代码的实现,向.NET Core 2.1添加了Brotli压缩支持。由于Brotli得到了许多Web浏览器和Web服务器的广泛支持,所以.NET Core提供对这项技术的支持是非常有用的。
什么是 Brotli 压缩算法
Brotli最初发布于2015年,用于网络字体的离线压缩。Google软件工程师在2015年9月发布了包含通用无损数据压缩的Brotli增强版本,特别侧重于HTTP压缩。其中的编码器被部分改写以提高压缩比,编码器和解码器都提高了速度,流式API已被改进,增加更多压缩质量级别。新版本还展现了跨平台的性能改进,以及减少解码所需的内存。
与常见的通用压缩算法不同,Brotli使用一个预定义的120千字节字典。该字典包含超过13000个常用单词、短语和其他子字符串,这些来自一个文本和HTML文档的大型语料库。预定义的算法可以提升较小文件的压缩密度。
使用brotli替换deflate来对文本文件压缩通常可以增加20%的压缩密度,而压缩与解压缩速度则大致不变。使用Brotli进行流压缩的内容编码类型已被提议使用“br”。
解决
首先引入解码相关的依赖
<dependency>
<groupId>org.brotli</groupId>
<artifactId>dec</artifactId>
<version>0.1.2</version>
</dependency>
解码代码
import org.apache.commons.io.IOUtils;
import org.brotli.dec.BrotliInputStream;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
public class BrotliUtil {
public static String toString(InputStream is) {
try {
BrotliInputStream stream = new BrotliInputStream(is);
BufferedReader reader = new BufferedReader(new InputStreamReader(stream));
StringBuilder result = new StringBuilder();
String str = null;
while ((str = reader.readLine()) != null) {
result.append(str);
}
return result.toString();
} catch (IOException e) {
e.printStackTrace();
return null;
} finally {
IOUtils.closeQuietly(is);
}
}
}
RFC
参考
[1]: https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers/Content-Encoding
[2]: https://zh.wikipedia.org/wiki/Brotli

















 2319
2319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









