/*通过五大视频网站数据,分析统计节目受欢迎度
注意:1-5数字和5大视频的关系:1优酷2搜狐3土豆4爱奇艺5迅雷看看
*/
第一步:定义一个电视剧热度数据的tvPlayWritable.java。
package com.hadoop.MapReduce;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class tvPlayWritable implements WritableComparable<Object>{
private int playTimes;//播放数
private int collectTimes;//收藏数
private int commentTimes;//评论数
private int treadTimes;//踩数
private int supportTimes;//赞数
public tvPlayWritable() {
}
public tvPlayWritable(int playTimes, int collectTimes, int commentTimes,
int treadTimes, int supportTimes) {
this.playTimes = playTimes;
this.collectTimes = collectTimes;
this.commentTimes = commentTimes;
this.treadTimes = treadTimes;
this.supportTimes = supportTimes;
}
@Override
public String toString() {
return playTimes+"\t"+collectTimes+"\t"+commentTimes+"\t"+treadTimes+"\t"+supportTimes;
}
public void set(int playTimes,int collectTimes, int commentTimes, int treadTimes, int supportTimes){
this.playTimes = playTimes;
this.collectTimes = collectTimes;
this.commentTimes = commentTimes;
this.treadTimes = treadTimes;
this.supportTimes = supportTimes;
}
public int getPlayTimes() {
return playTimes;
}
public void setPlayTimes(int playTimes) {
this.playTimes = playTimes;
}
public int getCollectTimes() {
return collectTimes;
}
public void setCollectTimes(int collectTimes) {
this.collectTimes = collectTimes;
}
public int getCommentTimes() {
return commentTimes;
}
public void setCommentTimes(int commentTimes) {
this.commentTimes = commentTimes;
}
public int getTreadTimes() {
return treadTimes;
}
public void setTreadTimes(int treadTimes) {
this.treadTimes = treadTimes;
}
public int getSupportTimes() {
return supportTimes;
}
public void setSupportTimes(int supportTimes) {
this.supportTimes = supportTimes;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(playTimes);
out.writeInt(collectTimes);
out.writeInt(commentTimes);
out.writeInt(treadTimes);
out.writeInt(supportTimes);
}
@Override
public void readFields(DataInput in) throws IOException {
playTimes = in.readInt();
collectTimes = in.readInt();
commentTimes = in.readInt();
treadTimes = in.readInt();
supportTimes = in.readInt();
}
@Override
public int compareTo(Object o) {
// TODO Auto-generated method stub
return 0;
}
}
第二步:定义一个读取热度数据的tvPlayInputFormat类。
package com.hadoop.MapReduce;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.util.LineReader;
public class tvPlayInputFormat extends FileInputFormat<Text, tvPlayWritable>{
@Override
public RecordReader<Text, tvPlayWritable> createRecordReader(
InputSplit split, TaskAttemptContext context) throws IOException,InterruptedException {
return new tvRecordReader();
}
public class tvRecordReader extends RecordReader<Text, tvPlayWritable>{
private LineReader lineReader; //private
private Text lineText;
private Text keyText;
private tvPlayWritable valuePlayWritable;
@Override
public void initialize(InputSplit split, TaskAttemptContext context)
throws IOException, InterruptedException {
FileSplit fileSplit=(FileSplit)split;
Path path = fileSplit.getPath();
Configuration configuration = context.getConfiguration();
FileSystem fileSystem = path.getFileSystem(configuration);
FSDataInputStream fsDataInputStream = fileSystem.open(path);
lineReader=new LineReader(fsDataInputStream, configuration);
lineText=new Text();
keyText=new Text();
valuePlayWritable=new tvPlayWritable();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
int i = lineReader.readLine(lineText);
if(i==0) return false;
String[] pieceStrings = lineText.toString().split("\\t+");
// String[] pieceStrings = lineText.toString().split("\\s+");
if(pieceStrings.length!=7){
throw new IOException("接收数据不合理");
}
int a,b,c,d,e,f;
try {
a=Integer.parseInt(pieceStrings[1].trim());
b=Integer.parseInt(pieceStrings[2].trim());
c=Integer.parseInt(pieceStrings[3].trim());
d=Integer.parseInt(pieceStrings[4].trim());
e=Integer.parseInt(pieceStrings[5].trim());
f=Integer.parseInt(pieceStrings[6].trim());
} catch (Exception e2) {
throw new IOException("强转类型失败");
}
String appName=null;
if(a==1){
appName="youku";
}else if(a==2){
appName="souhu";
}else if(a==3){
appName="tudou";
}else if(a==4){
appName="aiqiyi";
}else if(a==5){
appName="xunlei";
}
keyText.set(pieceStrings[0].trim()+"\t"+appName);
valuePlayWritable.set(b, c, d, e, f);
return true;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return keyText;
}
@Override
public tvPlayWritable getCurrentValue() throws IOException,
InterruptedException {
return valuePlayWritable;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
if(lineReader!=null){
lineReader.close();
}
}
}
}
第三步:写MapReduce统计程序
package com.hadoop.MapReduce;
import java.io.IOException;
//import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.MultipleOutputs;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class tvPlayCount extends Configured implements Tool{
public static class TvMapper extends Mapper<Text, tvPlayWritable, Text, tvPlayWritable>{
@Override
protected void map(Text key, tvPlayWritable value, Context context) throws java.io.IOException ,InterruptedException {
context.write(key, value);
};
}
public static class TvReducer extends Reducer<Text, tvPlayWritable, Text, Text>{
private MultipleOutputs<Text, Text> multipleOutputs;//对应map的输出kv
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
multipleOutputs=new MultipleOutputs<Text, Text>(context);
}
@Override
protected void cleanup(Context context) throws IOException,
InterruptedException {
multipleOutputs.close();
}
@Override
protected void reduce(Text key,Iterable<tvPlayWritable> values, Context context) throws java.io.IOException ,InterruptedException {
int playTimes=0;//播放数
int collectTimes=0;//收藏数
int commentTimes=0;//评论数
int treadTimes=0;//踩数
int supportTimes=0;//赞数
for (tvPlayWritable tvPlayWritable : values) {
playTimes+=tvPlayWritable.getPlayTimes();
collectTimes+=tvPlayWritable.getCollectTimes();
commentTimes+=tvPlayWritable.getCommentTimes();
treadTimes+=tvPlayWritable.getTreadTimes();
supportTimes+=tvPlayWritable.getSupportTimes();
}
String[] split = key.toString().split("\t");
multipleOutputs.write(new Text(split[0]), new Text(playTimes+"\t"+collectTimes+"\t"+commentTimes+"\t"+treadTimes+"\t"+supportTimes),split[1]);
//context.write(key, new Text(playTimes+"\t"+collectTimes+"\t"+commentTimes+"\t"+treadTimes+"\t"+supportTimes));
};
}
@Override
public int run(String[] args) throws Exception {
Configuration configuration = new Configuration();
Path path = new Path(args[1]);
FileSystem fileSystem = path.getFileSystem(configuration);
// FileSystem fileSystem = FileSystem.get(new URI(args[1]), configuration);
if(fileSystem.isDirectory(path)){
fileSystem.delete(path,true);
}
Job job = Job.getInstance();
job.setJarByClass(tvPlayCount.class);
job.setMapperClass(TvMapper.class);
job.setReducerClass(TvReducer.class);
job.setInputFormatClass(tvPlayInputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(tvPlayWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
String [] arg0={
"hdfs://dajiangtai:9000/junior/tvplay.txt",
"hdfs://dajiangtai:9000/junior/tvplay-out/"
};
System.exit(ToolRunner.run(new Configuration(), new tvPlayCount(), arg0));
}
}
第四步:上传tvplay.txt数据集到HDFS,并运行程序
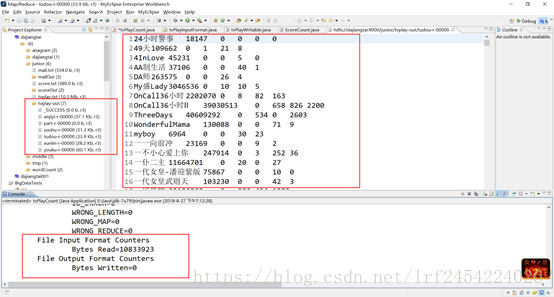





 该博客介绍通过五大视频网站数据,分析统计节目受欢迎度的方法。具体步骤包括定义电视剧热度数据的tvPlayWritable.java、读取热度数据的tvPlayInputFormat类,编写MapReduce统计程序,最后上传数据集到HDFS并运行程序。
该博客介绍通过五大视频网站数据,分析统计节目受欢迎度的方法。具体步骤包括定义电视剧热度数据的tvPlayWritable.java、读取热度数据的tvPlayInputFormat类,编写MapReduce统计程序,最后上传数据集到HDFS并运行程序。

















 932
932

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









