









论文题目:Reliability-aware Dynamic Feature Composition for Name Tagging
论文出处:ACL 2019
论文地址:http://nlp.cs.rpi.edu/paper/featurecomposition2019.pdf
源码:https://github.com/limteng-rpi/neural_name_tagging
论文概述
论文题目是 用于专名识别(命名实体识别,NER)的可靠性感知的动态特征组合。论文设计了一组基于字频率的可靠性信号,以指示每个词向量的质量。在可靠性信号的指导下,该模型能够使用门控机制动态选择和组合诸如词向量和字符级表示之类的特征。例如,如果输入单词为罕见词 / 稀有词,则模型较少依赖于其词嵌入,并为其字符和上下文特征分配较高权重。
论文要点
1. Reliability Signals

可靠性信号的组成是这篇论文的重点,主要包括两部分 词嵌入训练文本内的词频分布 以及 NER任务训练集的词频分布。
文章进行了一些处理,如将词频进行规范化处理,避免分布范围跨度过大的问题,另外设定一组词频阈值,引入一些二值信号。
如下面公式所示:
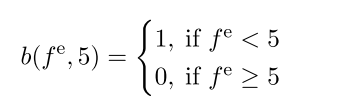
2.Dynamic Feature Composition
动态特征组合体现在两个部分: 词表示级别以及特征提取级别。
Word Representation Level
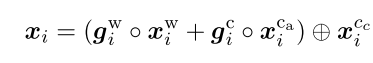
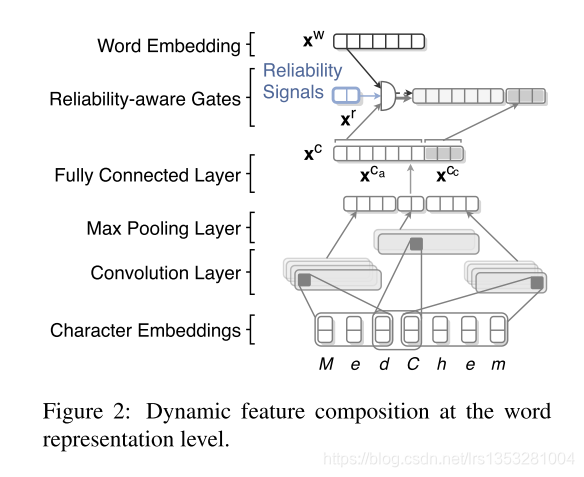
如图所示,这篇论文的word representation 的获取方式是:
首先, 字符嵌入经过卷积层,pooling层,FC层后,基于门控机制和依赖信号,与词嵌入进行结合(表示1)。
字符嵌入经过另外的卷积层,pooling层,FC层后,直接与上述表示1部分进行级联。
这里实际对词嵌入和字符嵌入都单独设置了一个门控机制,而不是基于两者概率加和为1的假设,文中解释是词嵌入和字符嵌入的信息并不总是 exclusive(独有、专一的)。
Feature Extraction Level
以下为特征提取阶段示意图,为了便于观察,文中只绘制了前向的提取过程,后向同理
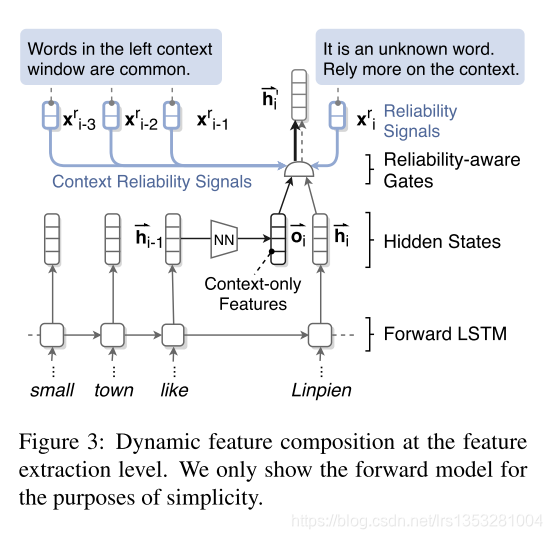
在特征提取级别,使用LSTM作为提取器。文中对当前词状态与上下文状态/信息 分隔开。
对上下文信息进行了编码:

同样基于门控机制和可靠性信号来控制对当前词信息和上下文信息的依赖程度(可理解为权重分布)。
最终的 状态编码/特征表示 如下:
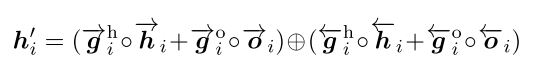
在此基础上通过常见的线性层等来做下游任务。
论文总结
以下仅代表个人观点。
1.这篇文章的主要创新是引入了可靠性信号,其实就是 词 在词向量训练文本和任务训练文本中的词频分布。基本想法是如果词出现次数较少,它的词向量不可靠,应该更多的依赖上下文信息,反之,如果词出现频率较高,则词向量相对可靠。
2.可靠性信号在两个层面体现作用,即在词表示阶段 以及 特征提取阶段 。
3. 在只允许使用字嵌入和词嵌入中的一种时,字嵌入在NER任务中表现更好,但是 单纯使用字嵌入会损失词嵌入中蕴含的丰富的语料信息。近期的NER模型倾向于同时利用字嵌入和词嵌入信息。
ps:本篇论文是基于英文NER任务,其字符嵌入与中文的字符嵌入还是有区别的,可以参考思路。















 924
924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









