




基于Socket的实时计算WordCount
Socket简述
Socket(套接字),用来描述IP地址和端口,是通信链的句柄,应用程序可以通过Socket向网络发送请求或者应答网络请求。Socket是支持TCP/IP协议的网络通信的基本操作单元,是对网络通信过程中端点的抽象表示,包含了进行网络通信所必须的五种信息:连接所使用的协议,本地主机的IP地址,本地远程的协议端口,远程主机的IP地址以及远程进程的协议端口。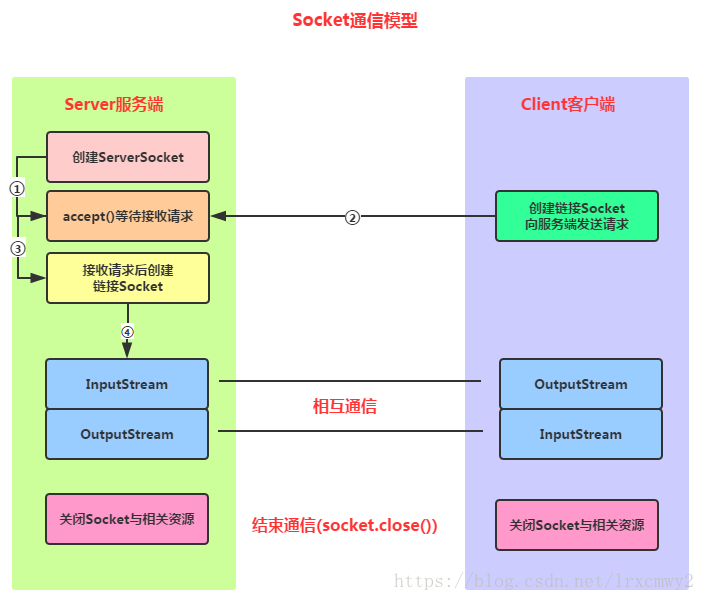
netcat
netcat是一个用于TCP/UDP连接和监听的Linux工具,主要用于网络传输及调试领域,简称nc
安装只需要yum install nc,不过CentOS7已经自带了。
编写基于Socket的实时WordCount
package StreamingDemo
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 基于Socket的实时WordCount
*/
object SocketWordCount {
def main(args: Array[String]): Unit = {
//设置日志级别
Logger.getLogger("org"). 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









