







引言
trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
前缀树的3个基本性质:
1.根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2.从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3.每个节点的所有子节点包含的字符都不相同。
前缀树有哪些应用:
- 前缀匹配
- 字符串检索, 比如 敏感词过滤,黑白名单等
- 词频统计
- 字符串排序
一、前缀树的结构
前缀树是一个由“路径”和“节点”组成多叉树结构。由根节点出发,按照存储字符串的每个字符,创建对应字符路径。
由“路径”记载字符串中的字符,由节点记载经过的字符数以及结尾字符结尾数,假设有b,abc,abd,bcd,abcd,efg,hii 这6个单词,那我们创建trie树就得到:
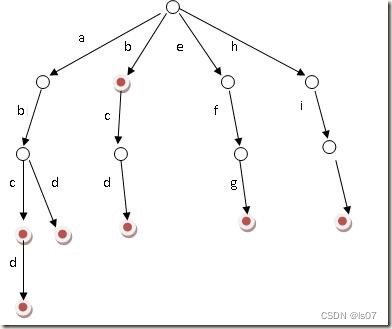
前缀树中的节点代码表示:
pass表示以该处节点之前的字符串为前缀的单词数量。
其中end代表有多少个字符串以这条路径结尾。
new TrieNode[26]中的26大小表示26个英文字母。
public class TrieNode {
int pass;
int end;
TrieNode[] nexts;
public TrieNode(){
pass=0;
end=0;
nexts = new TrieNode[26];
}
}
通过这样一颗前缀树,可以做到哪些功能:
是否有"ab"字符串?通过走到a-b,再看b的end是否不为0就能得到答案。
有多少以"ab"为前缀的字符串?来到头结点,走到a-b,查看b点的p值就能知道答案。
二、前缀树的节点添加
往前缀树中插入一个单词。
这有三种情况。
1、这个单词已经存在
2、这个单词已经是前缀了
3、这个单词不存在
对这三种情况,首先要做的都是遍历这棵树。
如果存在,修改路径上每个节点的path和end值。
如果是前缀,那就改成完整的单词。
如果不存在,那就把缺少的字母补进去,并设为完整的单词。
public void insert(String word) {//加入一个字符串
if (word == null) {
return;
}
char[] chs = word.toCharArray();//将word转换为字符型的数组
TrieNode node = root;//node从根节点出发
node.pass++;//头结点++//根节点的p值可以表示为添加了多少个字符串
int index = 0;
for (int i = 0; i < chs.length; i++) {
index = chs[i] - 'a';//index对应nexts数组的下标0,1,2‘a’-'a'=0,'b'-'a'=1
if (node.nexts[index] == null) {//如果不存在该节点则创建对应的一个新节点
node.nexts[index] = new TrieNode();
}
node = node.nexts[index];//按字符的顺序,指针移动到路径对应的节点
node.pass++;//沿途每路过一个节点++
}
node.end++;//在字符的最后一个节点处end+1,表示有一个以当前节点为尾的字符
}
三、前缀树的查询
两种查找方法,第一种是查询某个字符word在前缀树中出现的次数;第二种是前缀树所有加入的字符串中,有几个是以pre这个字符串作为前缀的。
3.1 当前字符出现的次数
遍历整个字符串,如果在遍历途中发现某个路径不存在(即路径的尾节点==null),则表示前缀树从未存储过该字符串。
经过遍历后,节点指针一定会来到最后一个字符路径的尾节点,这个节点的 end 记录了总共有多少个字符串以这个字符路径结尾,所以直接返回 end 即可。
public int search(String word) {
if (word == null) {
return 0;
}
char[] chs = word.toCharArray();//将word转换为char型的数组
TrieNode node = root;//node从根节点出发
int index = 0;
for (int i = 0; i < chs.length; i++) {
index = chs[i] - 'a';//index对应nexts数组的下标0,1,2‘a’-'a'=0,'b'-'a'=1
if (node.nexts[index] == null) {//表示该字符串不存在,直接返回0
return 0;
}
node = node.nexts[index];//移动节点指针
}
return node.end;//遍历结束后,节点指针来到字符串的尾节点,直接返回end统计值
}
3.2 查询pre前缀出现的次数
前缀查找统计的逻辑和字符串查找的逻辑几乎完全一样,唯一不同的是,在最后返回时,返回的是字符串尾节点的 pass 值,它代表有多少个字符串经过了这个节点。
public int prefixNumber(String pre) {
if (pre == null) {
return 0;
}
char[] chs = pre.toCharArray();
TrieNode node = root;
int index = 0;
for (int i = 0; i < chs.length; i++) {
index = chs[i] - 'a';
if (node.nexts[index] == null) {
return 0;
}
node = node.nexts[index];
}
return node.pass;
}
四、前缀树的删除
1.在开始执行真正的删除逻辑之前,一定要先调用 search 方法判断是否存在该字符串。
2、如果 node 的pass 属性-1 后是0,那么需要将节点引用置为 null,以便回收内存,同时也契合 insert、search等逻辑中 判断路径是否存在的方式。
//删除一个字符串(沿途p--.结尾end--即可)
public void delete(String word){
if (search(word) != 0) {//确定树种确实加入过word,才删除
char[] chs = word.toCharArray();
TrieNode node = root;
node.pass--;
int index = 0;
for (int i = 0; i < chs.length; i++) {
index = chs[i] - 'a';
if (--node.nexts[index].path == 0) {//特殊情况:如果发现某一个节点的p为0,说明该节点已经没有用了,删除该节点
node.nexts[index] = null;
return;
}
node = node.nexts[index];
}
node.end--;
}
}
五、相关例题
5.1 替换单词
描述
在英语中,有一个叫做 词根(root) 的概念,它可以跟着其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典和一个句子,需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
需要输出替换之后的句子。
示例1
输入:dictionary = ["cat","bat","rat"], sentence = "the cattle was rattled by the battery"
输出:"the cat was rat by the bat"
示例2
输入:dictionary = ["ac","ab"], sentence = "it is abnormal that this solution is accepted"
输出:"it is ab that this solution is ac"
注意
dictionary[i] 仅由小写字母组成。
1 <= sentence.length <= 10^6
sentence 仅由小写字母和空格组成。
sentence 中单词的总量在范围 [1, 1000] 内。
sentence 中每个单词的长度在范围 [1, 1000] 内。
sentence 中单词之间由一个空格隔开。
sentence 没有前导或尾随空格。
思路:
首先写出前缀树中的解节点构造,再需要我们前文提到过的两个方法,一个是前缀树的节点添加方法,还有一个是查询pre前缀出现的次数的方法。
在主方法中,先将词典dictionary转换为前缀树,通过String的split方法将sentence转换为String数组,方便后续操作,遍历String数组,如果当前字符在前缀树中能够找到对应的词根,那么就String的substring截取对应的词根,完成替换这一步。
最后通过StringBuilder 将转换后的String数组构造成字符串。
代码
class Solution {
//前缀树的节点构造
class TrieNode{
int pass;
int end;
TrieNode[] nexts;
public TrieNode(){
pass= 0;
end = 0;
nexts = new TrieNode[26];
}
}
TrieNode root;//创建一个根节点
//主方法
public String replaceWords(List<String> dictionary, String sentence) {
root = new TrieNode();
//先将词典dictionary转换为前缀树
for(String s : dictionary){
insert(s);
}
String[] s = sentence.split(" ");
for(int i = 0; i < s.length; i++){
int num = search(s[i]);
//如果当前字符有词根,那么截取对应的词根
s[i] = num == 0 ? s[i] : s[i].substring(0, num);
}
//拼接新的字符
StringBuilder res = new StringBuilder();
for(String str : s){
res.append(str);
res.append(" ");
}
res.delete(res.length() - 1, res.length());//去除最后一个多余的空格
return res.toString();//转换为string
}
//添加节点
public void insert(String word){
char[] chs = word.toCharArray();
TrieNode node = root;
node.pass++;
int index = 0;
for(int i = 0; i < chs.length; i++){
index = chs[i] - 'a';
if(node.nexts[index] == null) node.nexts[index] = new TrieNode();
node = node.nexts[index];
node.pass++;
}
node.end++;
}
//查看当前字符在前缀树中是否有前缀
public int search(String word){
char[] chs = word.toCharArray();
TrieNode node = root;
int index = 0;
int num = 0;//记录所需词根的长度
for(int i = 0; i < chs.length; i++){
index = chs[i] - 'a';
num++;
if(node.nexts[index] == null) return 0;
node = node.nexts[index];
if(node.end > 0) break;
}
return num;
}
}
5.2 单词之和
描述
实现一个 MapSum 类,支持两个方法,insert 和 sum:
- MapSum() 初始化 MapSum 对象
- void insert(String key, int val) 插入 key-val 键值对,字符串表示键 key ,整数表示值 val 。如果键 key 已经存在,那么原来的键值对将被替代成新的键值对。
- int sum(string prefix) 返回所有以该前缀 prefix 开头的键 key 的值的总和。
示例:
输入:
inputs = ["MapSum", "insert", "sum", "insert", "sum"]
inputs = [[], ["apple", 3], ["ap"], ["app", 2], ["ap"]]
输出:
[null, null, 3, null, 5]
解释:
MapSum mapSum = new MapSum();
mapSum.insert("apple", 3);
mapSum.sum("ap"); // return 3 (apple = 3)
mapSum.insert("app", 2);
mapSum.sum("ap"); // return 5 (apple + app = 3 + 2 = 5)
提示:
- 1 <= key.length, prefix.length <= 50
- key 和 prefix 仅由小写英文字母组成
- 1 <= val <= 1000
- 最多调用 50 次 insert 和 sum
思路:
本题可以通过前缀树+哈希表来实现
inset方法:
首先判断当前哈希表中是否有当前字符,如果有,前缀树中的节点值就应该先减去之前的值。即对“如果键 key 已经存在,那么原来的键值对将被替代成新的键值对。”这句话的翻译。
然后将新的键值对放入到哈希表中,并开始将当前字符添加到前缀树中去,并且前缀树中每个节点的num属性加delta值
sum方法只需遍历到prefix的最后一个字符,看这个字符当前在前缀树中的num值是多少,返回即可.
代码:
class MapSum {
class TrieNode{
int num;//不需要原来的pass和end属性,只需要将map中键值对的val赋给该属性即可
TrieNode[] nexts;
public TrieNode(){
num = 0;
nexts = new TrieNode[26];
}
}
TrieNode root;
Map<String, Integer> map;
/** 初始化 */
public MapSum() {
root = new TrieNode();
map = new HashMap<>();
}
public void insert(String key, int val) {
/**
这行代码可能不太好理解,简单说明一下
[[], ["apple", 3], ["ap"], ["app", 2], ["ap"], ["apple", 2], ["ap"]]
[null, null, 3, null, 5, null, 4(所以是4而不是7)]
因为"apple", 在前缀树中已经有了,所以原来的键值对将被替代成新的键值对,所以val变为2,同样的,前缀树中的节点对应的num属性也要更新,所以
将delta = val - map.getOrDefault(key, 0)即 2 - 3 = -1
后面的num += delta就将num更新为2
*/
int delta = val - map.getOrDefault(key, 0);
map.put(key, val);
char[] chs = key.toCharArray();
TrieNode node = root;
int index = 0;
for(int i = 0; i < chs.length; i++){
index = chs[i] - 'a';
if(node.nexts[index] == null) node.nexts[index] = new TrieNode();
node = node.nexts[index];
node.num += delta;
}
}
public int sum(String prefix) {
char[] chs = prefix.toCharArray();
TrieNode node = root;
int index = 0;
for(int i = 0; i < chs.length; i++){
index = chs[i] - 'a';
if(node.nexts[index] == null) return 0;
node = node.nexts[index];
}
return node.num;
}
}














 11万+
11万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









