







首先看一个小程序
public class T00_00_IPlusPlus {
private static long n = 0L;
public static void main(String[] args) throws Exception {
//Lock lock = new ReentrantLock();
Thread[] threads = new Thread[100];
CountDownLatch latch = new CountDownLatch(threads.length);
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
n++;
}
latch.countDown();
});
}
for (Thread t : threads) {
t.start();
}
latch.await();
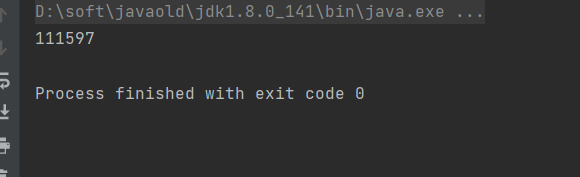
System.out.println(n);
}
}
在如上代码中首先创建一百个线程,然后每个线程将n加一万次,最后应该得出n等于1000000,但是在实际的输出中得到以下结果,n的值并没有达到一百万,这是因为多个线程同时访问同一个资源产生了竞争,比如线程1读取n=0在执行加加的时候这时侯还没有把n的值写回去的时候,同时线程2和线程3都读取了n=0再执行加1的操作,最后得出来3个线程读取完成之后n还是等于1,问题就出在这里。(产生原因为race condition=>竞争条件,指的是多个线程访问共享数据的时候产生竞争,就会随之产生数据的不一致的结果)
认识原子性:
首先分析一下为何会出现数据不一致的情况,首先加加操作会把n值从内存中读到寄存器里面然后加完了之后再写回去,但是还没有写回去的时候另外的线程过来读到了原值,导致了最后的数据不一致的问题(我一个线程正在执行的操作被另外一个线程打断了),只要我的当前操作不能被别的线程打断,那么最后的数据就是一致的,那么就符合并发编程的原子性。
哪些语句是原子性的呢(八大原子操作)?
1、lock:主内存,标识变量为线程独占
2、unlock:主内存,解锁线程独占变量
3、read:主内存,读取内存到线程缓存
4、load:工作内存,read后的值放入线程本地变量副本
5、use:工作内存,传值给执行引擎
6、assign:工作内存,存值到主内存给write备用
7、store:工作内存,存值到主内存给write备用
8、write:主内存,写变量值
工作内存:线程本地的缓存。
如何保证并发编程的原子性?(上锁)
使用synchronized 或者 lock。
上锁的本质:上锁的本质就是把并发编程序列化。
如下代码的Runnable接口就是先打印线程的名字然后睡2s,再让线程结束
public class WhatIsLock {
private static Object o = new Object();
public static void main(String[] args) {
Runnable r = () -> {
//synchronized (o) {
System.out.println(Thread.currentThread().getName() + " start!");
SleepHelper.sleepSeconds(2);
System.out.println(Thread.currentThread().getName() + " end!");
//}
};
for (int i = 0; i < 3; i++) {
new Thread(r).start();
}
}
}
输出结果如下:

如上所示基本上3个线程一起启动,再一起结束,基本上2s就结束了。如果将上面代码中synchronized的注释去掉的话,输出结果如下:

耗时基本上为6s,是因为将原来的并发执行输出变成了一个一个的来输出(序列化)。
回到n++的那个例子,如果在n++的前面加上synchronized,那么最后的输出始终都是1000000,因为sychronized保证了线程之间的可见性以及原子性。
同步的一些概念
race condition=>竞争条件,指的是多个线程访问共享数据的时候产生竞争
数据的不一致(unconsistency),并发访问之下产生的不期望出现的结果
sychronized锁住的对象我们一般称为管程(Monitor)–>锁
critical section -->临界区:持有锁的时候我所执行的代码(sychronized大括号里面包裹的)
如果临界区执行时间长,语句多,叫做锁的粒度比较粗,反之就是锁的粒度比较细。
乐观锁与悲观锁
上锁:保证(critical section)一系列操作的原子性,有两种方式可以保证(乐观锁,悲观锁)
悲观锁:先上锁,再做事(悲观的认为这个操作会被别的线程打断如sychronized)
乐观锁:乐观的认为这个操作不会被别的线程打断(乐观锁、自旋锁、无锁)
cas操作:CAS=Compare And Set/Swap/Exchange
CAS概念
如下图所示:

先读取一个未改变的值E,然后去做计算,得到计算的结果,在往回写的过程中,判断E是否和原来的值相等,如果相等的话则更新未改变的值为计算后的值,如果此时发现E和原来的值不相等的话,则重新读取原来的值为E值,然后再重复做计算,再来比较E的值是否发生改变,如果发生改变再次做计算,如果没有发生改变则更新值为计算后的值。
CAS的ABA问题:
当前的值为A,然后其他线程修改当前的值为B然后又把值还原回了初始的值A,
0->8->0,但大部分情况下是不需要做修改的。
有些情况下是必须解决ABA问题的,比如说这里的A变成了某个对象的引用,但是可能在最后里面引用的内容发生了改变,但是我们拿到的依然是那个引用。
如何解决ABA问题:
加一个Version标志,每次做了改变都增加Version的版本(时间戳或者布尔类型。)
CAS底层的原子性保证:
通过Atomic类
代码如下:
public class AtomicInteger {
/*volatile*/ //int count1 = 0;
AtomicInteger count = new AtomicInteger(0);
/* synchronized */void m() {
for (int i = 0; i < 10000; i++)
//if count1.get() < 1000
count.incrementAndGet(); //count1++
}
public static void main(String[] args) {
T01_AtomicInteger t = new T01_AtomicInteger();
List<Thread> threads = new ArrayList<Thread>();
for (int i = 0; i < 100; i++) {
threads.add(new Thread(t::m, "thread-" + i));
}
threads.forEach((o) -> o.start());
threads.forEach((o) -> {
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(t.count);
}
}
其中incrementAndGet()方法就是每次往回写的时候就比较是不是我所期望的值,
底层代码如下:


点击compareAndSwapInt()方法,是c++的源码:

然后进入Atomic::cmpxchg方法的定义:

is_MP:Multi_process–首先判断是否是多核的处理器,如果是则LOCK_IF_MP,然后执行汇编语句cmpxchg,但是这条指令并不是原子的,但是前面加上了lock上锁,必须等这条指令执行完了再释放锁。
硬件:
lock指令在执行的时候视情况采用缓存锁或者总线锁。
总结:虽然cas我们宏观称为乐观锁,但是底层实现用的是lock这个命令,也是直接使用的是悲观锁锁上的。
悲观锁和乐观锁谁的效率更高
悲观锁:一般会有一个等待的队列,但是在队列中等待的线程不消耗CPU资源
乐观锁:会一直自旋直到拿到锁,会消耗CPU的资源(做线程切换,一直在while中自旋)
不同的场景:
临界区执行时间比较长,等的人很多->重量级(选用悲观锁)
临界区执行时间短,等的人少->自旋锁(选用乐观锁)
推荐实战使用:synchronized
synchronized和三大特性
1、synchronized保证可见性:
在我们解锁之后,它会把我们所有的内存状态跟本地的缓存做一个刷新,然后下一个线程才能继续,sychronized本身底层也有lock语句,lock是有内存屏障的。
锁不仅是关于同步与互斥的,也是关于内存可见的,为了保证所有线程都能够看到共享的、可变变量的最新值,读取和写入线程必须使用公共的线程进行同步。
2、sychronized保证原子性
3、sychronized不保证有序性,不能控制语句执行的顺序。














 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









