







text-embedding模型系列
T-SNE来可视化embedding降维后的数据(相似评论和评分的分布关系)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.manifold import TSNE
import ast
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 #有中文出现的情况,需要u'内容'
#读取csv文件
df=pd.read_csv('datas/embedding_output_1k.csv')
print(df['embedding'][0])
# str类型
print(type(df['embedding'][0]))
#将字符串转化为矩阵(list类型)
df['embedding_vec'] = df['embedding'].apply(ast.literal_eval)
print(df['embedding_vec'][0])
print(type(df['embedding_vec'][0]))
# T-SNE 可以将高维度的数据映射到 2D 或 3D 的空间中, 以便我们可以直观地观察和理解数据的结构
# nunique返回不同值的个数[1,2,3,1,2,4]=4
if df['embedding_vec'].apply(len).nunique() == 1:
#向量转化为矩阵
matrix = np.vstack(df['embedding_vec'].values)
# 创建一个T-SNE的模型 n_components =2 代表是二维的
tsne = TSNE(n_components=2, perplexity=15, random_state=42,init='random',learning_rate=200)
# 使用t-sne模型降维得到二维的
matrix_2d = tsne.fit_transform(matrix)
print(matrix_2d)
#可视化建设,根据不同的颜色来区分不同的评论
colors = ["red", "darkorange", "gold", "turquoise", "darkgreen"]
#所有的行的第一列,以及所有的行的第二列
x=matrix_2d[:,0]
y=matrix_2d[:,1]
#评分从1开始的,颜色索引是从0开始的
colors_index = df.Score.values - 1
print(colors_index)
print(type(colors_index))
color_map = matplotlib.colors.ListedColormap(colors)
#开始画图,散点图 c:颜色的索引 cmap:颜色的映射对象,alpha透明度
plt.scatter(x, y, c=colors_index, cmap=color_map,alpha=0.3)
plt.title('使用T-SNE降维后的亚马逊评论')
plt.show()
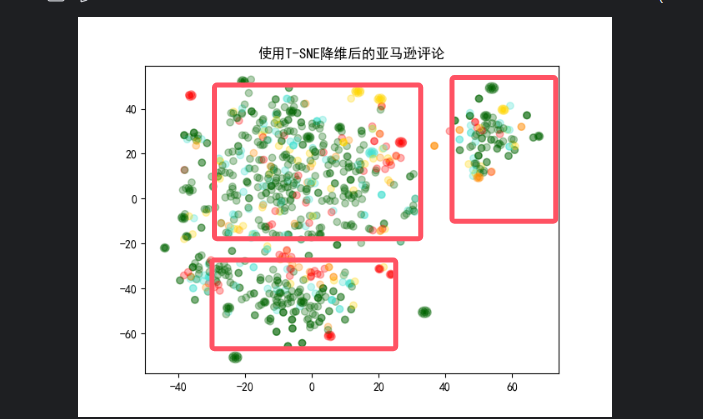
根据散点图的关系我们将评论分为消极,中立,积极的评论
embedding数据输出数据等长:

embedding后得到的向量空间,根据聚类结果得到散点图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.manifold import TSNE
import ast
from sklearn.cluster import k_means, KMeans
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号 #有中文出现的情况,需要u'内容'
#读取csv文件
df=pd.read_csv('datas/embedding_output_1k.csv')
print(df['embedding'][0])
# str类型
print(type(df['embedding'][0]))
#将字符串转化为矩阵(list类型)
df['embedding_vec'] = df['embedding'].apply(ast.literal_eval)
print(df['embedding_vec'][0])
print(type(df['embedding_vec'][0]))
# T-SNE 可以将高维度的数据映射到 2D 或 3D 的空间中, 以便我们可以直观地观察和理解数据的结构
# nunique返回不同值的个数[1,2,3,1,2,4]=4
if df['embedding_vec'].apply(len).nunique() == 1:
#向量转化为矩阵
matrix = np.vstack(df['embedding_vec'].values)
#初始化kMeans对象 聚类的数量
km = KMeans(3,init='k-means++',random_state=43, n_init=10)
km.fit(matrix)
df['Kmeans_Label'] = km.labels_ # 把所有的类别存放到新的字段:0,1,2
# 创建一个T-SNE的模型 n_components =2 代表是二维的
tsne = TSNE(n_components=2, perplexity=15, random_state=42,init='random',learning_rate=200)
# 使用t-sne模型降维得到二维的
matrix_2d = tsne.fit_transform(matrix)
print(matrix_2d)
#可视化建设,根据不同的颜色来区分不同的评论
colors = ["red", "green", "blue"]
#所有的行的第一列,以及所有的行的第二列
x=matrix_2d[:,0]
y=matrix_2d[:,1]
#根据类别的值来得到不同的颜色
colors_index = df['Kmeans_Label'].values
print(colors_index)
print(type(colors_index))
color_map = matplotlib.colors.ListedColormap(colors)
#开始画图,散点图 c:颜色的索引 cmap:颜色的映射对象,alpha透明度
plt.scatter(x, y, c=colors_index, cmap=color_map,alpha=0.3)
plt.title('使用聚类和T-SNE降维后的亚马逊评论')
plt.show()
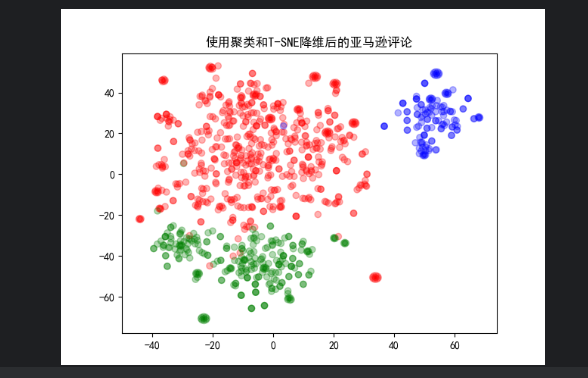
利用向量空间做相似度搜索
余弦相似度

import pandas as pd
import numpy as np
import ast
from openai import OpenAI
import os
client = client = OpenAI()
df = pd.read_csv('datas/embedding_output_50.csv')
# 把str转化成矩阵
df['embedding_vec'] = df['embedding'].apply(ast.literal_eval)
#在向量空间中,语意相似的词或者文本单位。距离靠近
def cosine_distance(a, b):
"""
计算两个向量之间的余弦距离
:param a:
:param b:
:return:
"""
# 得到这两个向量之间的夹角余弦值,如果余弦相似度接近于 1,则表示这两个向量非常相似;接近于 -1 表示它们方向相反;
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def embedding_text(text, model='text-embedding-ada-002'):
"""
通过OpenAI的Embedding模型处理文本数据
:param text: 需要处理的文本数据
:param model:
:return:
"""
resp = client.embeddings.create(input=text, model=model)
return resp.data[0].embedding
def search_by_word(df, work_key, n_result=3, print_flag=True):
"""
根据指定的关键词(句子),去向量空间中进行相似搜索
:param df: 已经Embedding之后的向量空间
:param work_key:
:param n_result: 返回结果中的数量
:param print_flag: 是否打印
:return:
"""
# 把关键词向量化
word_embedding = embedding_text(work_key)
# 计算相似度
df['similarity'] = df.embedding_vec.apply(lambda x: cosine_distance(x, word_embedding))
res = (
df.sort_values('similarity', ascending=False)
.head(n_result)
.combined.str.replace('Title:', "")
.str.replace('; Content:', ';')
)
if print_flag:
for r in res:
print(r)
print()
return res
if __name__ == '__main__':
search_by_word(df, 'delicious beans', 3)
print('='*50)
search_by_word(df, 'awful', 3)
输出结果
Great flavor no bite;This coffee is a favorite of mine and many others. Jet Fuel is dark roasted but smooth and rich with no bite!
Great flavor no bite;This coffee is a favorite of mine and many others. Jet Fuel is dark roasted but smooth and rich with no bite!
Blackcat;Great coffee! Love all Green Mountain coffee and all the wonderful flavors. Would and do recommend this coffee to all my friends.
==================================================
Arrived in pieces;Not pleased at all. When I opened the box, most of the rings were broken in pieces. A total waste of money.
Broken in a million pieces;Chips were broken into small pieces. Problem isn't amazon's, it's Stacy's. Stacy (or amazon) needs to pack the original box of six better, the bags move around too much. There was room for at least two more bags in the box.<br />Amazon packed the Stacy's box in their box very tight and good.<br /><br />I tried to complain to Stacy, they make it very hard, no luck.<br />Chips taste great though, maybe I'll pour them in a bowl with milk for breakfast.
It's Okay;Next time, I will buy Gevalia Irish Cream decaf coffee. I thought this would be as good, but it's mostly sugar.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









