









前言
本文介绍SparkSQL的相关知识;
Spark 知识系列文章
此处罗列了有关Spark相关知识的其他文章,有需要的可以进行点击查阅。
一、SparkSQL 概述
SparkSQL是Spark用来处理结构化数据的一个模块,它提供了两个编程抽象:DataFrame,DataSet,并且作为分布式Sql查询引擎的作用。
1.1 DataFrame
DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待,DataFrame也是懒执行的。性能上比RDD要高,主要原因:
优化的执行计划:查询计划通过Spark catalyst optimiser进行优化。
1.2 DataSet
RDD中的数据是没有结构的 + 数据结构 -> DataFrame + 类和属性 –> DataSet
1.3 RDD、DataFrame和DataSet三者的关系
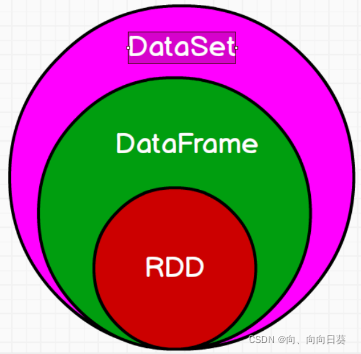
二、SparkSQL的编程
2.1 DataFrame
在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口,创建DataFrame有三种方式:通过Spark的数据源进行创建;从一个存在的RDD进行转换;还可以从Hive Table进行查询返回。
2.1.1 通过Spark的数据源进行创建
(1)通过SQL语法实现:
代码如下:
val df = Spark.read.json(“file:///opt/module/data/input/2.json”) #读取Json文件内
df.show
df.creatTempView(“student”) #将DataFrame对象转化成一个临时视图,方便用Sql查询
spark.sql(“select * from student”).show #就可以写SQL了
注意:临时表是Session范围内的,Session退出后,表就失效了。如果想应用范围内有效,可以使用全局表。注意使用全局表时需要全路径访问,如:global_temp.people
代码如下:
df.createGlobalTempView("emp")
spark.sql("SELECT * FROM global_temp.emp").show()
(2)DSL语法风格:
1、只查看”name”列数据:
df.select(“name”).show()
2、查看”name”列数据以及”age+1”数据:
df.select($“name”, $“age” + 1).show()
3、查看”age”大于”21”的数据 :
df.filter($“age” > 21).show()
4、按照”age”分组,查看数据条数:
df.groupBy(“age”).count().show()
2.1.2 RDD转换为DataFrame
2.1.2.1 手动转换
代码如下:
import spark.implicits._ //导入隐式转换
val rdd = sc.makeRDD(List((1,"zhangsan",20),(2,"lisi",12),(3,"wangwu",52)))
val df = rdd.toDF("id","name","age")
2.1.2.2 通过样例类
代码如下:
case class people(id:Int,name:String,age:Int) //构造样例类
val rdd = sc.makeRDD(List((1,"zhangsan",20),(2,"lisi",12),(3,"wangwu",52)))
val peopleRDD = rdd.map(t=>{people(t._1,t._2,t._3)})
val df = peopleRDD .toDF()
2.1.3 将DataFrame转化为RDD
直接调用RDD即可;
代码如下:
val dfToRDD = df.rdd
2.2 DataSet
Dataset是具有强类型的数据集合,需要提供对应的类型信息。
2.2.1 通过样例类创建
代码如下:
case class people(name:String,age:Int) //构造样例类
val caseclassDS = Seq(people("andy",12)).toDS //创建DataSet
2.2.2 RDD转换为DataSet
转化过程:RDD + 结构 -> DataFrame + 类型 -> DataSet
代码如下:
case class people(name:String,age:Int) //构造样例类
val peopleRDD = rdd.map(t=>{people(t._1,t._2)})//将RDD加上结构就是person
val peopleDS = peopleRDD.toDS //转化成DataSet,注意转化成DataFrame是.toDF
2.2.3 DataSet转化为RDD、DataFrame
直接用ds.rdd即可;
DataFrame -> DataSet: df.as[person],即加上类型就会自动转换了;
DataSet -> DataFrame: ds.toDF
2.3 RDD,DataFrame,DataSet相互转换示意图
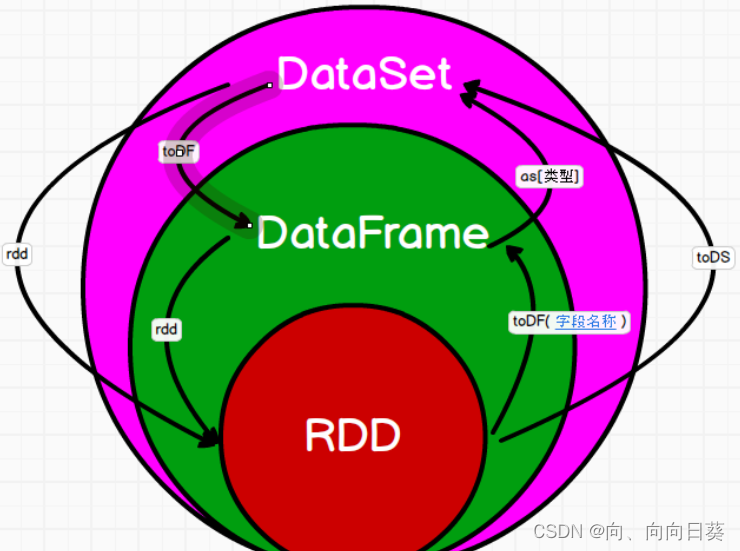
2.4 IDEA实现三者相互转换
创建样例类:
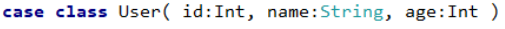
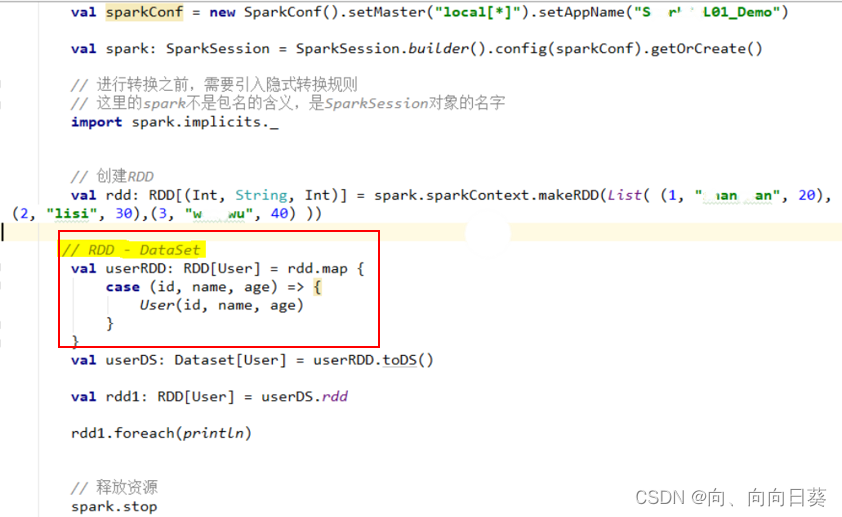
实现三者转换:

实现由RDD直接转化成DataSet:
2.5 用户自定义函数
2.5.1 用户自定义UDF函数
代码如下:
val df = Spark.read.json(“file:///opt/module/data/input/2.json”) #读取数据构建DataFrame对象
//自定义函数:在传过来的字符串前面加上“name”字符串:
spark.udf.register("addName",(x:String)=>"Name:"+x)
df.createTempView("users")//建立临时视图
spark.sql("select addName(name) from users").show //调用函数查看效果
2.5.2 用户自定义聚合函数
自定义求年龄的平均值的聚合函数
2.5.2.1 弱类型
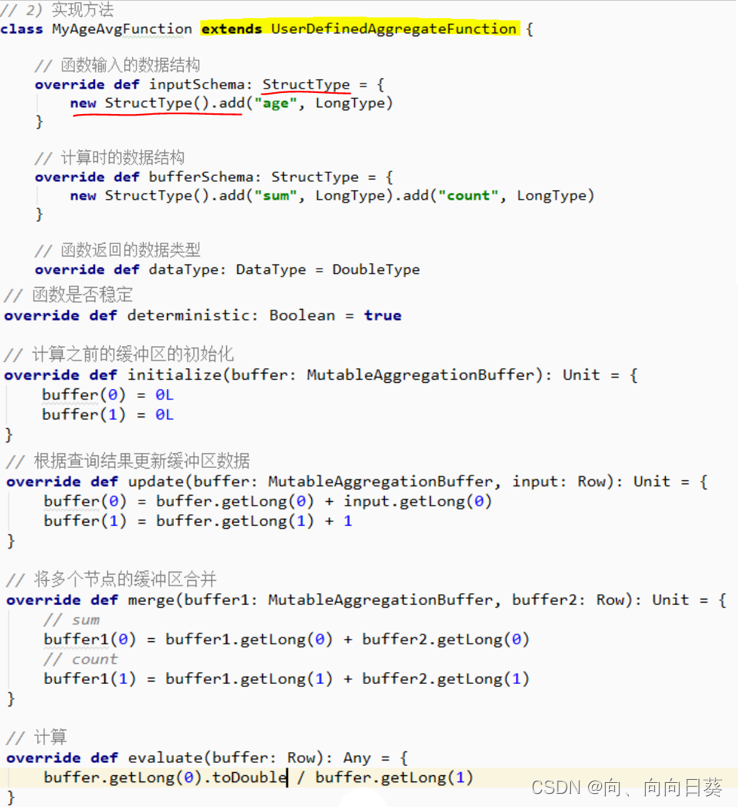
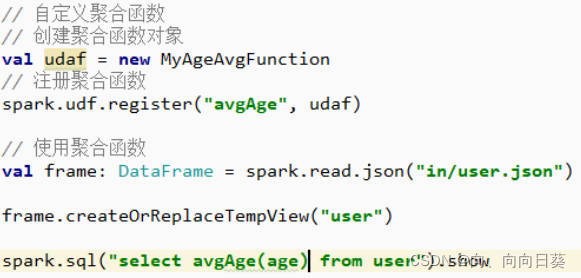
调用函数:
2.5.2.2 强类型
设置泛型 -> 增加样例类
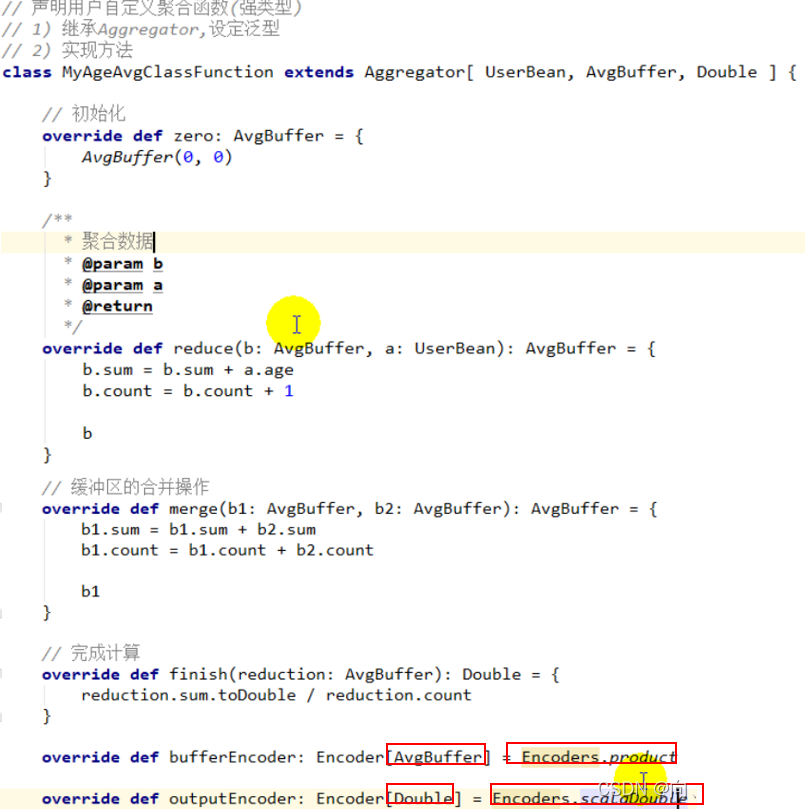
自定义类型转码就用这个(红框标注的),double等类型转码就用这个,是固定的;
调用函数:
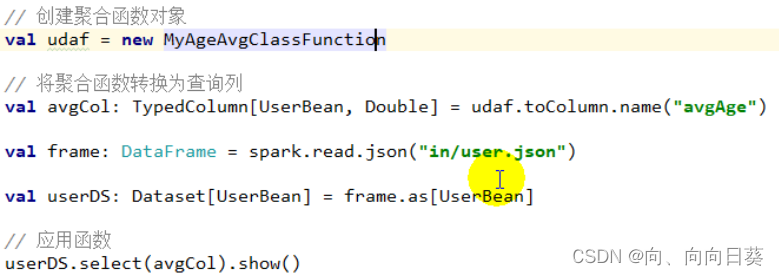
三、SparkSQL 的数据源
Spark SQL的默认数据源为Parquet格式。数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作。修改配置项spark.sql.sources.default可修改默认数据源格式。

当数据源格式不是parquet格式文件时,需要手动指定数据源的格式。数据源格式需要指定全名(例如:org.apache.spark.sql.parquet),如果数据源格式为内置格式,则只需要指定简称定json, parquet, jdbc, orc, libsvm, csv, text来指定数据的格式。

文件保存,默认保存格式parquet:

保存为目标格式(json):

设置文件写入模式-追加:

文件写入的其他模式:
(1)error(默认) 如果文件存在就报错
(2)append 追加
(3)overwrite 覆写
(4)ignore 数据存在则忽略
总结
本文介绍了SparkSQL的相关知识;如果有不足之处或者表述不当的地方欢迎大家指正。














 895
895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









