







 本文介绍了一个基于LibreOffice实现Word文档转换为PDF的Python脚本案例。通过详细记录解决过程中遇到的各种问题,如路径格式、权限问题等,最终实现了稳定可靠的转换流程。
本文介绍了一个基于LibreOffice实现Word文档转换为PDF的Python脚本案例。通过详细记录解决过程中遇到的各种问题,如路径格式、权限问题等,最终实现了稳定可靠的转换流程。
网上现在基于python代码实现word转pdf的方法,基本都是依赖于micro office。然后我找了一大圈之后,确实也没有别的完全不依赖外部就能实现word2pdf。但是也找到有一个比微软office友好的方案。就是 LibreOffice,他的优点是:
- 完全开源,没有任何使用限制,商业使用也没有限制
- 安装比微软office简单,安装包也小一点
当然,缺点也是有的,就是转换并不能完全保持格式不变,这点可能就能让很多人放弃他了。。。
但是不管怎么样,我也需要一种有别于微软office 的方案。
实现
LibreOffice虽说国内也有站点,但是资料是真的不多,特别是关于编程开发这块的,api的使用也很不人性化。所以,我从0 到整出来代码,花了两天。。。很痛苦。
但是整出来的代码并不可用呀,毕竟都是看的很老的资料了。
首选官方论坛提供了一种方法:api调用,但是这种方法他依赖于时候用libre自带的python,不能使用本地的python,这怎么能忍,所以四处搜索别的方法,于是在libre的大哥“openOffice”论坛上找到一些方法:python+COM桥
这里提供的方法可以使用本地python调用libre。于是我整合各方代码,写出了以下代码:
import win32com.client
OO_ServiceManager = win32com.client.DispatchEx("com.sun.star.ServiceManager")
desktop = OO_ServiceManager.CreateInstance("com.sun.star.frame.Desktop")
OO_ServiceManager._FlagAsMethod("Bridge_GetStruct")
def createProp(name, value):
prop = OO_ServiceManager.Bridge_GetStruct("com.sun.star.beans.PropertyValue")
prop.Name = name
prop.Value = value
return prop
loading_properties=[]
# loading_properties.append(createProp("ReadOnly",True))
# loading_properties.append(createProp("Hidden",True))
filepath = "file:///%s" % r"C:\workSpace\python\word2pdf\test.docx"
document = desktop.loadComponentFromUrl(filepath, "_blank", 0, tuple(loading_properties))
# document.CurrentController.Frame.ContainerWindow.Visible = False
pdf_properties = []
pdf_properties.append(createProp("FilterName", "writer_pdf_Export"))
newpath = filepath[:-len("docx")] + "pdf"
try:
document.storeToURL(newpath, pdf_properties) # Export
except Exception:
raise
try:
document.close(True)
except Exception:
raise
运行代码的前提当然是安装了LibreOffice,然后运行,首先能,不开“readOnly”和“hidden”模式去读取报告的时候,它会弹出可视化界面,会报这个错:
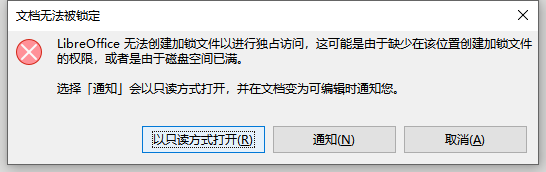
然后点通知呢,就能以可读的方式打开对应的word(这里可能需要time.sleep一下,否则这个窗口没多久可能就会自己关闭),所以呀,折腾了两天的代码,好歹看到了文档可以被打开,还是感觉到离成功不远了。
等这个窗口关闭之后,控制台还会输出错误:
Traceback (most recent call last):
File "C:\workSpace\python\word2pdf\test2.py", line 26, in <module>
document.storeToURL(newpath, pdf_properties) # Export
File "<COMObject <unknown>>", line 2, in storeToURL
pywintypes.com_error: (-2147352567, '发生意外。', (1001, '[automation bridge] ', 'com.sun.star.io.IOException: SfxBaseModel::impl_store <file:///C:\\workSpace\\python\\word2pdf\\test.pdf> failed: 0x507(Error Area:Io Class:Access Code:7)', None, 0, 0), None)
于是追着两个错误,查资料,看文档和代码,在安装包的“\libreoffice-7.2.5.2\include\vcl\errcode.hxx”文件中,可以看到错误代码7表示:“Locking”,就认为是权限问题:
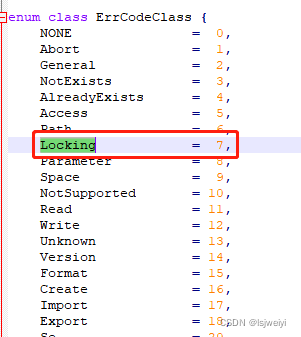
除了权限问题,我当时就还怀疑是我的路径写的有问题,当然因为文档确实也被打开了,所以也不是很怀疑是路径的问题。追着权限问题查了一天。但是实在是没有结果。于是想放弃。
但是还不甘心,就想着先用它自带的那个python跑一下,看能不能实现,于是我跑了api调用的代码
,没出意外,它和我报的一样的错误。到这里,是真的想放弃了。
但是难受了三天,还是挣扎了一下,最后再百度搜了这篇,替换了“”api调用“”的那份代码,只是将他的文件路径改成我的。神奇的是他居然没报错!!!
然后马上查为什么,对比了下来,就发现路径那里的写法不一样:
filepath = r"C:\Users\JimStandard\Desktop\Untitled 1.docx"
fileUrl = uno.systemPathToFileUrl(os.path.realpath(filepath))
他的路径是用libre的转换函数转换出来的,于是就print出来,乍一看,没发现什么不同,但是仔细对比,它的路径用的反斜杠“/”,而我的是“\”!然后马上改了自己的代码,它真的就可以了!!!
但是为什么我那样写它也能打开文档来!!!
好吧,是自己细节不好,没注意到这个地方,花了一整天。
PS:其实API调用那篇也没有问题的,只是人家那是Linux下的实现。
最后贴一下完整的代码:
import win32com.client
# 调用程序
OO_ServiceManager = win32com.client.DispatchEx("com.sun.star.ServiceManager")
desktop = OO_ServiceManager.CreateInstance("com.sun.star.frame.Desktop")
OO_ServiceManager._FlagAsMethod("Bridge_GetStruct")
# 生成参数元祖
def createProp(name, value):
prop = OO_ServiceManager.Bridge_GetStruct("com.sun.star.beans.PropertyValue")
prop.Name = name
prop.Value = value
return prop
#读取文档的参数
loading_properties=[]
loading_properties.append(createProp("ReadOnly",True)) # 以只读方式打开
loading_properties.append(createProp("Hidden",True)) # 隐藏可视化界面,只是隐藏,还是加载了资源的
filepath = "file:///%s" % r"C:/workSpace/python/word2pdf/test.docx" # 绝对路径,注意反斜杠
document = desktop.loadComponentFromUrl(filepath, "_blank", 0, tuple(loading_properties))
document.CurrentController.Frame.ContainerWindow.Visible = False # 据说这样就不会加载可视化界面了,可是放在这个位置都已经加载完成了呀!先放着吧
#转换为pdf的参数
pdf_properties = []
pdf_properties.append(createProp("FilterName", "writer_pdf_Export"))
newpath = filepath[:-len("docx")] + "pdf" # pdf 保存路径和名称
try:
document.storeToURL(newpath, pdf_properties) # 转换输出
except Exception:
raise
try:
document.close(True) # 关闭
except Exception:
raise
这里只是初级目标,我想的是,将libreOffice精简,然后整成一个很小的包,不然几百兆的安装包,还是挺烦人的。



















 1097
1097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











