







ElasticSearch 基本使用
一、基础概念
大数据4V理论
❶Volume,数据规模大,从T升到P、E;
❷Variety,数据类型多,非结构化的数据、语音、地理位置信息、视频等数据;
❸Value,数据价值高,具有很大的商业价值,支持深层数据挖掘;
❹Velocity,数据处理速度快,要求实时处理而非传统的存储性数据进行数据库处理。大数据底层架构
技术选型:大数据平台通常采用经过产业界验证的Hadoop生态技术组件为主,配合搜索引擎、传统DB等构底层架构。对部分组件进行了二次研发,以满足个性化需求。
技术团队:岗位匹配完整,团队具有对大数据技术的经验积累,具备对海量数据的处理能力。
基础概念解释
索引(index)
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
在一个集群中,如果你想,可以定义任意多的索引。
类型(type)
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
文档(document)
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(JavaScript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,只要你想,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
分片和复制(shards & replicas)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
允许你水平分割/扩展你的内容容量
允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因:
在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。
扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。
二、安装说明安装配置
配置文件修改
根据config中具体配置说明,主要字段为:
修改为本集群的ip列表:
discovery.zen.ping.unicast.hosts: [“10.26.168.18”,”10.26.168.16”,”10.26.79.131”]
文件系统恢复的节点数:
gateway.recover_after_nodes: 3
节点名称:
node.name: node1 配置ip: network.host: 192.168.10.133
修改host
10.44.45.93 node1
10.170.191.236 node2
10.172.9.66 node3
10.172.3.87 node4
- 启动与关闭
启动方法:
cd elasticsearch/bin/service
elasticsearch start
关闭方法:
elasticsearch stop
其它部分都已默认配置好!
检查方法
启动方法:
cd elasticsearch/bin/service
elasticsearch start
关闭方法:
elasticsearch stop
其它部分都已默认配置好!
#######################################################################################################
检查方法
curl -XPUT http://localhost:9201/_cluster/settings {"transient":{"cluster.routing.allocation.enable":"none"}}- 安装组件
安装组件
bin/plugin install mobz/elasticsearch-head
修改配置文件:
顶格修改!!!!,否则报错
页面
http://192.168.10.138:9201/_plugin/head/
- 卸载组件
卸载组件
bin/plugin remove head - 其它
查看已安装的组件
curl -XGET ‘http://localhost:9201/_nodes/plugin’
安装 sql的步骤
首先参考https://github.com/NLPchina/elasticsearch-sql
有的时候使用上述url中介绍的安装方式安装不上,这个时候就需要手动安装了。
1.下载es-sql
比如我使用的es的版本是2.3.3
https://github.com/NLPchina/elasticsearch-sql/releases/download/2.3.3.0/elasticsearch-sql-2.3.3.0.zip
2.将elasticsearch-sql-2.3.3.0.zip解压
zip elasticsearch-sql-2.3.3.0.zip,解压后的目录为elasticsearch-sql-2.3.3.0
3.将elasticsearch-sql-2.3.3.0移动到elasticsearch-2.3.3/plugins目录
4.将elasticsearch-sql-2.3.3.0重命名为sql
5.重启es
6.通过http://192.168.1.39:9200/_plugin/sql/进行访问
组件安装总结:
只需要在plugin下解压就可以了。但是名称要和在线安装的名称一样才行。
bin/plugin list
常用配置介绍
1.Cluster
cluster.name: elasticsearch
设置ElasticSearch集群的名字,默认的集群名字为elasticsearch,如果想要让某一ElasticSearch节点加入集群只需指定cluster.name
2. Node
node.name: “Franz Kafka“,设置ElasticSearch节点的名字
node.master: true,设置节点是否为主节点
node.data: true,设置节点是否存储索引分片
3. Index
index.number_of_shards: 5,设置索引的分片数,默认为5个分片
index.number_of_replicas: 1,设置索引的副本数,默认为1个副本
4. Paths
path.data: /data/esdata,设置索引数据的存储路径
path.logs: /data/eslogs,设置日志数据的存储路径
三、索引操作
rest接口
Elasticsearch提供了非常全面和强大的REST API,利用这个REST API你可以同集群交互。下面是利用这个API,可以做的几件事情:
检查集群、节点和索引的健康状态、和各种统计信息
管理集群、节点、索引数据和元数据
对索引进行CRUD(创建、读取、更新和删除)和搜索操作。
集群健康
以基本的健康检查作为开始,可以利用它来查看我们集群的状态。此过程中,我们使用curl,当然,你也可以使用任何可以创建HTTP/REST调用的工具。我们假设我们还在我们启动Elasticsearch的节点上并打开另外一个shell窗口。
要检查集群健康,我们将使用_cat API。需要事先记住的是,我们的节点HTTP的端口是9201:
curl ‘localhost:9201/_cat/health?v’
常用命令介绍
_cluster系列1、查询设置集群状态curl -XGET localhost:9201/_cluster/health?pretty=truepretty=true表示格式化输出level=indices 表示显示索引状态level=shards 表示显示分片信息2、curl -XGET localhost:9201/_cluster/stats?pretty=true显示集群系统信息,包括CPU JVM等等3、curl -XGET localhost:9201/_cluster/state?pretty=true集群的详细信息。包括节点、分片等。3、curl -XGET localhost:9201/_cluster/pending_tasks?pretty=true
_nodes系列1、查询节点的状态curl -XGET ‘http://localhost:9201/_nodes/stats?pretty=true’curl -XGET ‘http://localhost:9201/_nodes/192.168.1.2/stats?pretty=true’curl -XGET ‘http://localhost:9201/_nodes/process’curl -XGET ‘http://localhost:9201/_nodes/_all/process’curl -XGET ‘http://localhost:9201/_nodes/192.168.1.2,192.168.1.3/jvm,process’curl -XGET ‘http://localhost:9201/_nodes/192.168.1.2,192.168.1.3/info/jvm,process’curl -XGET ‘http://localhost:9201/_nodes/192.168.1.2,192.168.1.3/_allcurl -XGET ‘http://localhost:9201/_nodes/hot_threads创建索引(名称:ls)
curl -XPUT http://localhost:9201/ls/ls/1 -d '{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}'
更新(update)
curl -XPUT http://localhost:9201/changzhijun/changzhijun/1 -d '{
"first_name" : "John2",
"last_name" : "Smith2",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}'
删除索引
Delete
curl -XDELETE localhost:9201/changzhijun/changzhijun/1
四、脑裂问题
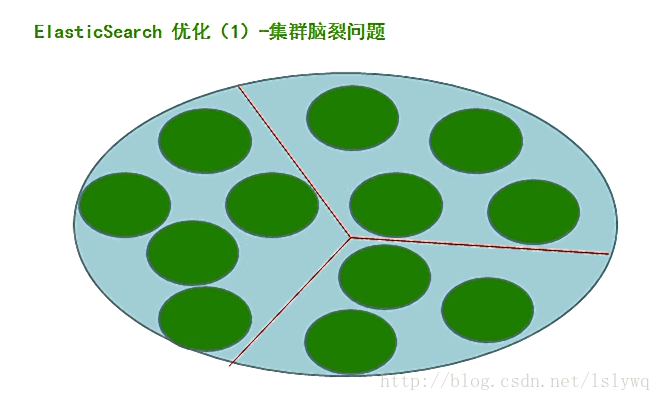
问题描述:
正常情况下,集群中的所有的节点,应该对集群中master的选择是一致的,这样获得的状态信息也应该是一致的,不一致的状态信息,说明不同的节点对master节点的选择出现了异常——也就是所谓的脑裂问题。这样的脑裂状态直接让节点失去了集群的正确状态,导致集群不能正常工作。
由于某些节点的失效,部分节点的网络连接会断开,并形成一个与原集群一样名字的集群,这种情况成为集群脑裂(split-brain)现象。这个问题非常危险,因为两个新形成的集群会同时索引和修改集群的数据。
ES集群脑裂可能导致的原因:
网络: 由于是内网通信, 网络通信问题造成某些节点认为 master 死掉, 而另选 master的可能性较小; 进而检查 Ganglia 集群监控, 也没有发现异常的内网流量, 故此原因可以排除。内网一般不会出现es集群的脑裂问题,可以监控内网流量状态。外网的网络出现问题的可能性大些。
节点负载: 由于 master 节点与 data 节点都是混合在一起的, 所以当工作节点的负载较大( 确实也较大) 时, 导致对应的 ES 实例停止响应, 而这台服务器如果正充当着 master节点的身份, 那么一部分节点就会认为这个 master 节点失效了, 故重新选举新的节点, 这时就出现了脑裂; 同时由于 data 节点上 ES 进程占用的内存较大, 较大规模的内存回收操作也能造成 ES 进程失去响应。 所以, 这个原因的可能性应该是最大的。
- 回收内存
由于data节点上es进程占用的内存较大,较大规模的内存回收操作也能造成es进程失去响应。
如果发生了脑裂,如何解决?
当脑裂发生后, 唯一的修复办法是解决这个问题并重启集群。 这儿有点复杂和可怕。 当elasticsearch 集群启动时, 会选出一个主节点( 一般是启动的第一个节点被选为主) 。 由于索引的两份拷贝已经不一样了, elasticsearch 会认为选出来的主保留的分片是“主拷贝”并将这份拷贝推送给集群中的其他节点。 这很严重。 让我们设想下你是用的是 node 客户端并且一个节点保留了索引中的正确数据。 但如果是另外的一个节点先启动并被选为主, 它会将一份过期的索引数据推送给另一个节点, 覆盖它, 导致丢失了有效数据。














 66
66











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









