







最近把海量数据如何进行相似查找技术进行个大体汇总,包括高维稀疏数据和稠密数据。
这一节重点针对高维稀疏数据情况,说如何通过哈希技术进行快速进行相似查找。
试想个案例,就拿推荐系统中item-user矩阵说事。如果你有item数量是百万级别,user是千万级别,这个矩阵是十分稀疏的。你如何计算每一个item的Top N相似item呢?
同样海量文本场景,文本集合可以看成doc-word 稀疏矩阵,如何求解每个文档的Top N相似文档?
如果采用两两比较的话,至少有两个问题:(1) O(n^2) 遍历比较时间复杂度; (2) 两个高维向量之间计算相似度,比如jaccard相似度,时间很耗时。
那如何解决呢? 第一反应是用倒排啊。的确倒排能把上面的时间复杂度降低好几个数量级。但是上面提到的第二个问题却还是存在的。并且当文本数量级达到一定数量级时候,倒排拉链过长,效率也会下降。
所以这章重点说下基于哈希的方法,这种方法通过牺牲一定精度来换取时间上大幅提升。
一 Minhashing
先从Minhash讲起。以下面这个例子说,其中S1={a, d}, S2={c}, S3={b, d, e}, S4={a, c, d}. 其中涉及的元素{a, b, c, d, e}。其中如果文本数据中,S1,S2,S3可以看成每个文本的bow向量形式,{a, b, c, d, e} 可以看整个词典集合。
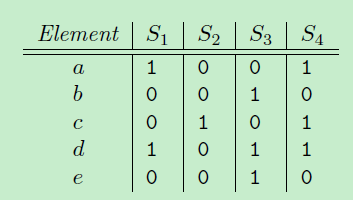
Minhashing 做什么呢?
他思路如下:把原来元素{a, b, c, d, e} 顺序随机重排,比如下图,一次随机重排序为{b, e, a, d, c}, 定义一个函数h:计算集合S最小的minhash值,就是在这种顺序下最先出现1的元素。
那么h(S1) = a, h(S2)=c, h(S3)=b, h(S4)=a;
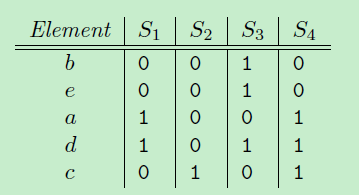
如果进行n重排的话,就会有n个minhash函数,{h1(S), h2(S)..., hn(S)}, 那原来每个高维集合,就会被降到n维空间,比如S1->{h1(S1), h2(S1)..., hn(S1)}。
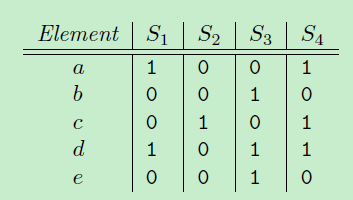
但是实际中因为重排比较耗时,会用若干随机哈希函数替代。比如设定一个哈希函数: h(x) = (i+1) % 5.
还是上面例子为例, 还是以{a, b, c, d, e}顺序,“i”表示各个索引,比如a的“i”值为,1, b的“i”值为2等。
对集合S1,计算各个元素哈希值为{2,0},其中h(a->i) = 2, h(d->i) = 0, 再计算最小哈希值对应的元素 minhash (h(S1))= d。
同样可以定义n个哈希函数,进行上述操作,那每个集合S就被降维到n维空间的签名。
二 LSH (Locality-Sensitive Hashing)
上面Minhashing解决了文章一开始提到的第二个问题,高维向量间计算复杂度问题(通过minhash 机制把高维降低到n维低纬空间), 但是还没解决第一个问题:两两比较,时间复杂度O(n^2)。
那是否有一种可能,通过某种机制让每个向量需要计算相似度的候选向量集合降低? LSH 就是这样的机制,通过哈希机制,让相似向量尽可能出现一个桶中,而不相似的向量出现在不同的桶中。相似度计算只在么个桶中进行,每个桶彼此之间不做相似度计算。
在minhashing 签名的基础上做LSH分析。
一个高维向量通过minhashing处理后变成n维低维向量的签名,现在把这n维签名分成b组,每组r个元素。每组通过一个哈希函数,把这组的r个元素组成r维向量哈希到一个桶中。每组可以使用同一个哈希函数,但是每组桶没交集,即使哈希值一样。桶名可以类似:组名+哈希值。在一个桶中的向量才进行相似度计算,相似度计算的向量是minhash的n维向量(不是r维向量)。
下面例子: minhash签名维度是12,分成4组,每组3个元素。拿band1来说,第二列和第四列向量是一样的(第二列是(0, 2, 1), 第四列是(0, 2, 1)),一定会哈希到相同的桶中(band1名下的桶),而第一列和第二列有可能不会在一个桶中(band1名下的桶)。
这里就是重点设置分多少个组,每组多少个元素问题。这个可以根据实际情况和一些经验case来定。

三 Simhash
simhash在工业界引起很大注意力是因为google 07那篇文章,把Simhash技术引入到海量文本去重领域。
google 通过Simhash把一篇文本映射成64bits的二进制串。下面是具体示意图:
文档每个词有个权重,同时哈希成一个二进制串。文档最终的签名是各个词签名的加权和。
如果两篇文档相同,则他们simhash签名汉明距离小于等于3。

他这篇文章重点还做了另外一块优化处理。
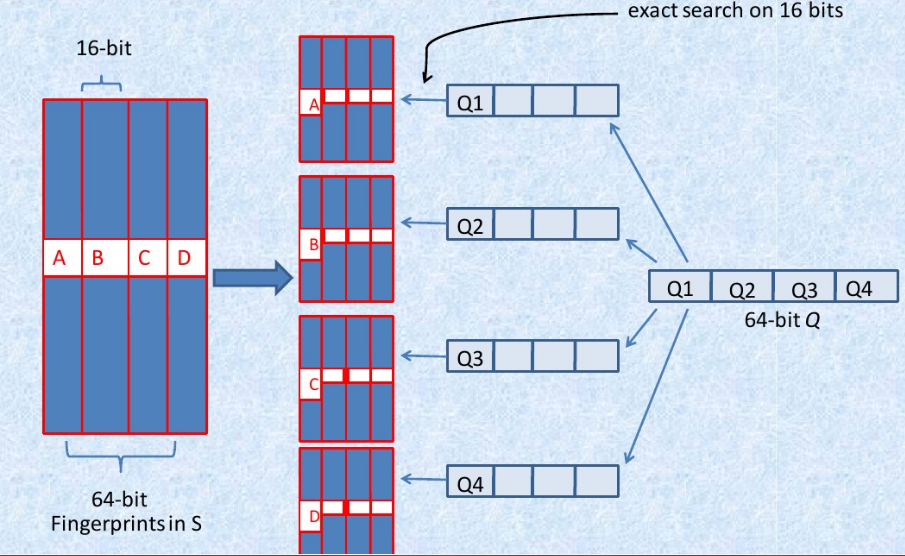
试想所有文档都用64bits代表,如果想要找到汉明距离小于等于3得文档,是不是也有需要两两比较的问题,那这样又回到时间复杂度是O(n^2)这个问题。
这篇文章作者通过把64bits分成4份,每份16bits。每份16bits看成一个桶,这16bits一样进入一个桶,进行汉明距离计算。
参考文献
【1】
Leskovec, Jurij. Mining of massive datasets / Jure Leskovec, Anand Rajaraman, Jeffrey David Ullman. 2nd ed[M]. Cambridge University Press, 2014.
【2】Manku G S, Jain A, Sarma A D. Detecting near-duplicates for web crawling[C]// International Conference on World Wide Web. ACM, 2007:141-150.















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









