







SimHash算法----海量数据如何根据文本内容快速找到相似文本原理及案例
SimHash算法原理转载自:https://blog.csdn.net/Daverain/article/details/80919418
一、什么是SimHash
SimHash算法是Google在2007年发表的论文《Detecting Near-Duplicates for Web Crawling》中提到的一种指纹生成算法,被应用在Google搜索引擎网页去重的工作之中。
简单的说,SimHash算法主要的工作就是将文本进行降维,生成一个SimHash值,也就是论文中所提及的“指纹”,通过对不同文本的SimHash值进而比较海明距离,从而判断两个文本的相似度。
对于文本去重这个问题,常见的解决办法有余弦算法、欧式距离、Jaccard相似度、最长公共子串等方法。但是这些方法并不能对海量数据高效的处理。
比如说,在搜索引擎中,会有很多相似的关键词,用户所需要获取的内容是相似的,但是搜索的关键词却是不同的,如“北京好吃的火锅“和”哪家北京的火锅好吃“,是两个可以等价的关键词,然而通过普通的hash计算,会产生两个相差甚远的hash串。而通过SimHash计算得到的Hash串会非常的相近,从而可以判断两个文本的相似程度。
二、SimHash的计算原理
SimHash算法主要有五个过程:分词、Hash、加权、合并、降维。
借用一张网络上经典的图片来描述整个过程:
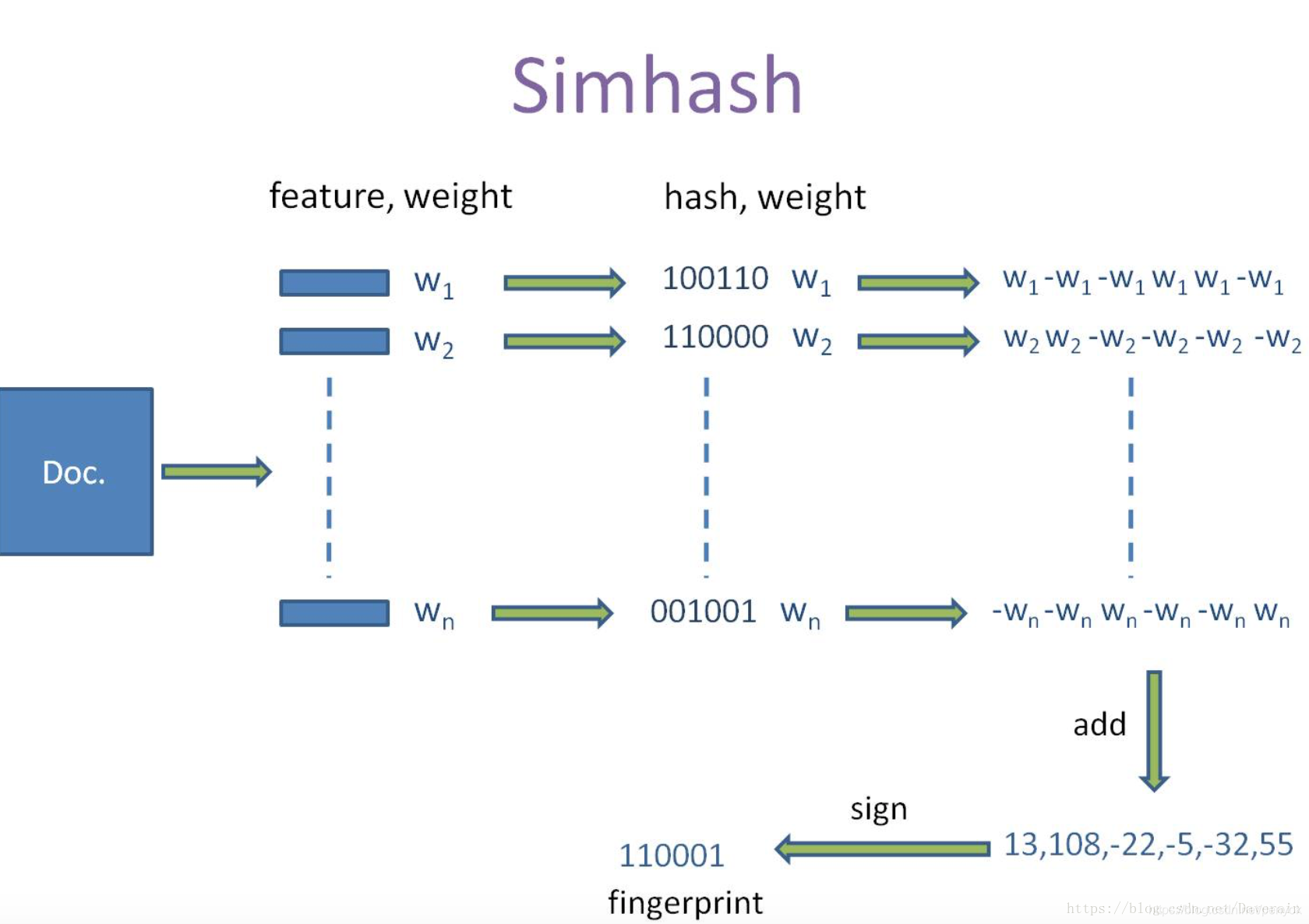
1.分词
对给定的一段文本进行分词,产生n个特征词,并赋予每个特征词一个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









