







目录
前面我们介绍了管程和信号量这两个同步原语在Java语言中的实现,理论上用这两个同步原语中任何一个都可以解决所有的并发问题。那Java SDK并发包里为什么还有很多其他的工具类呢?原因很简单:分场景优化性能,提升易用性。
读多写少这种并发场景,Java SDK并发包提供了读写锁——ReadWriteLock,非常容易使用,并且性能很好。
(一)ReadWriteLock
1)那什么是读写锁呢?
读写锁,并不是Java语言特有的,而是一个广为使用的通用技术,所有的读写锁都遵守以下三条基本原则:
- 允许多个线程同时读共享变量;
- 只允许一个线程写共享变量;
- 如果一个写线程正在执行写操作,此时禁止读线程读共享变量。
读写锁与互斥锁的一个重要区别就是读写锁允许多个线程同时读共享变量,而互斥锁是不允许的,这是读写锁在读多写少场景下性能优于互斥锁的关键。但读写锁的写操作是互斥的,当一个线程在写共享变量的时候,是不允许其他线程执行写操作和读操作。
2)快速实现一个缓存
下面我们用ReadWriteLock快速实现一个通用的缓存工具类。
在下面的代码中,我们声明了一个Cache类,其中类型参数K代表缓存里key的类型,V代表缓存里value的类型。缓存的数据保存在Cache类内部的HashMap里面,HashMap不是线程安全的,这里我们使用读写锁ReadWriteLock 来保证其线程安全。ReadWriteLock 是一个接口,它的实现类是ReentrantReadWriteLock,通过名字你应该就能判断出来,它是支持可重入的。下面我们通过rwl创建了一把读锁和一把写锁。
Cache这个工具类,我们提供了两个方法,一个是读缓存方法get(),另一个是写缓存方法put()。
- 读缓存需要用到读锁,读锁的使用和前面我们介绍的Lock的使用是相同的,都是try{}finally{}这个编程范式。
- 写缓存则需要用到写锁,写锁的使用和读锁是类似的。
class Cache {
final Map m = new HashMap<>();
final ReadWriteLock rwl = new ReentrantReadWriteLock();
// 读锁
final Lock r = rwl.readLock();
// 写锁
final Lock w = rwl.writeLock();
// 读缓存
V get(K key) {
r.lock();
try { return m.get(key); }
finally { r.unlock(); }
}
// 写缓存
V put(K key, V value) {
w.lock();
try { return m.put(key, v); }
finally { w.unlock(); }
}
}
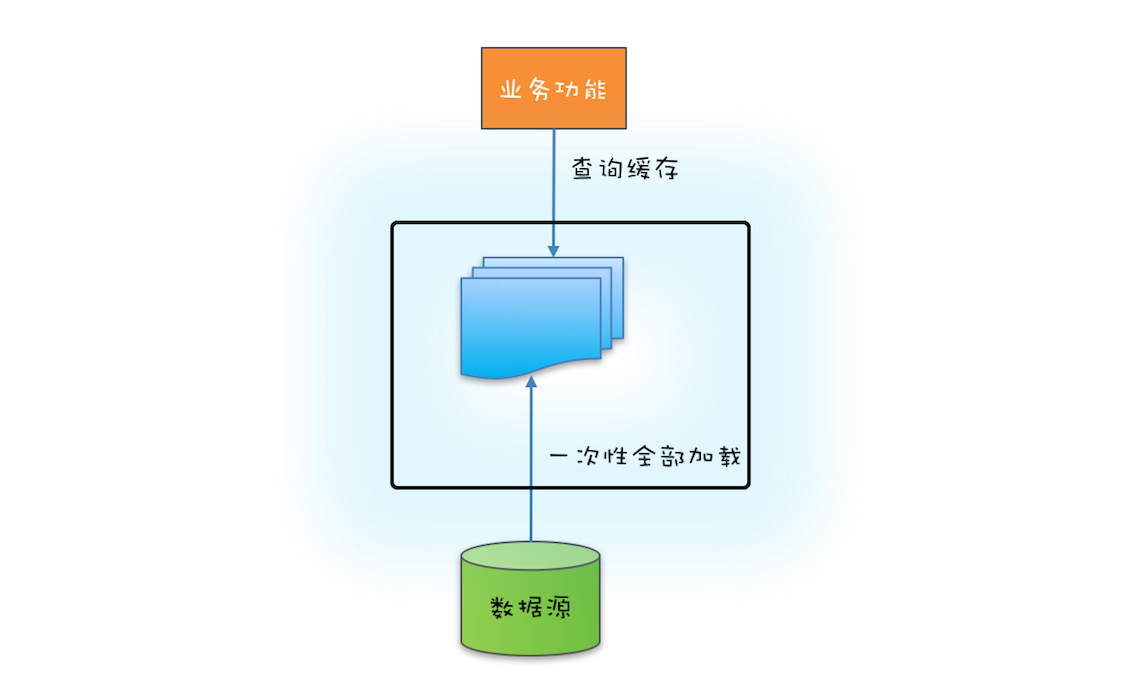
如果你曾经使用过缓存的话,你应该知道使用缓存首先要解决缓存数据的初始化问题。缓存数据的初始化,可以采用一次性加载的方式,也可以使用按需加载的方式。
如果源头数据的数据量不大,就可以采用一次性加载的方式,这种方式最简单(可参考下图),只需在应用启动的时候把源头数据查询出来,依次调用类似上面示例代码中的put()方法就可以了。
如果源头数据量非常大,那么就需要按需加载了,按需加载也叫懒加载,指的是只有当应用查询缓存,并且数据不在缓存里的时候,才触发加载源头相关数据进缓存的操作。下面你可以结合文中示意图看看如何利用ReadWriteLock 来实现缓存的按需加载。
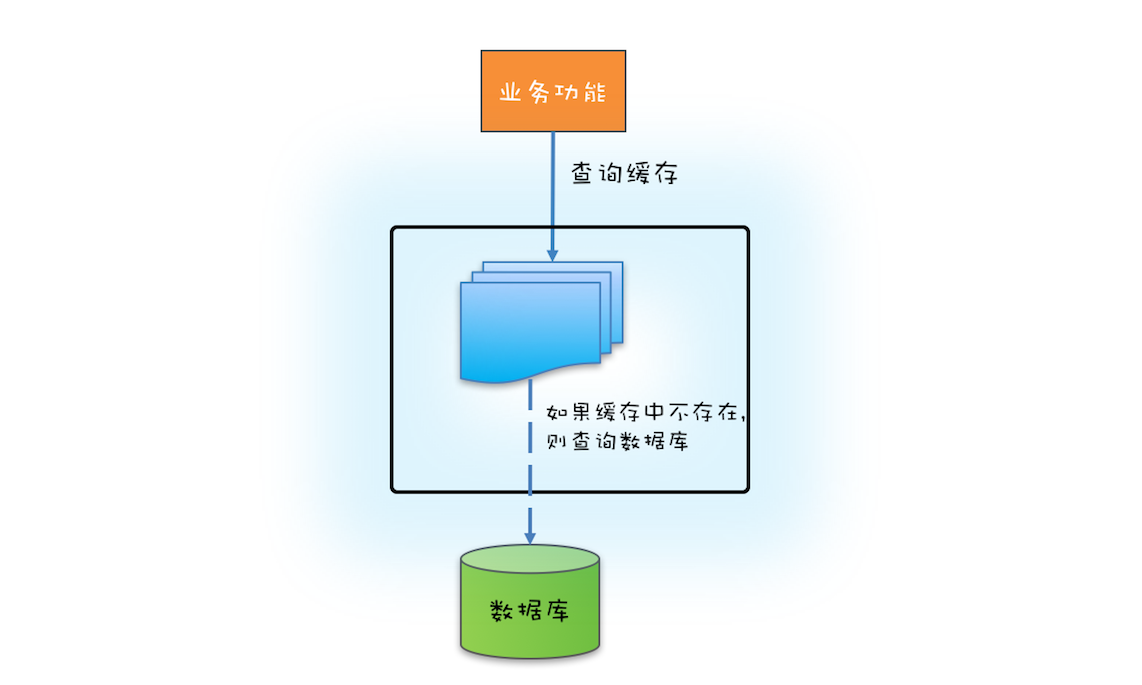
如何实现缓存的按需加载?
文中下面的这段代码实现了按需加载的功能,这里我们假设缓存的源头是数据库。需要注意的是,如果缓存中没有缓存目标对象,那么就需要从数据库中加载,然后写入缓存,写缓存需要用到写锁,所以在代码中的⑤处,我们调用了 w.lock() 来获取写锁。
另外,还需要注意的是,在获取写锁之后,我们并没有直接去查询数据库,而是在代码⑥⑦处,重新验证了一次缓存中是否存在,再次验证如果还是不存在,我们才去查询数据库并更新本地缓存。为什么我们要再次验证呢?
class Cache {
final Map m = new HashMap<>();
final ReadWriteLock rwl = new ReentrantReadWriteLock();
final Lock r = rwl.readLock();
final Lock w = rwl.writeLock();
V get(K key) {
V v = null;
//读缓存
r.lock(); ①
try {
v = m.get(key); ②
} finally{
r.unlock(); ③
}
//缓存中存在,返回
if(v != null) { ④
return v;
}
//缓存中不存在,查询数据库
w.lock(); ⑤
try {
//再次验证
//其他线程可能已经查询过数据库
v = m.get(key); ⑥
if(v == null){ ⑦
//查询数据库
v=省略代码无数
m.put(key, v);
}
} finally{
w.unlock();
}
return v;
}
}
原因是在高并发的场景下,有可能会有多线程竞争写锁。假设缓存是空的,没有缓存任何东西,如果此时有三个线程T1、T2和T3同时调用get()方法,并且参数key也是相同的。那么它们会同时执行到代码⑤处,但此时只有一个线程能够获得写锁,假设是线程T1,线程T1获取写锁之后查询数据库并更新缓存,最终释放写锁。此时线程T2和T3会再有一个线程能够获取写锁,假设是T2,如果不采用再次验证的方式,此时T2会再次查询数据库。T2释放写锁之后,T3也会再次查询一次数据库。而实际上线程T1已经把缓存的值设置好了,T2、T3完全没有必要再次查询数据库。所以,再次验证的方式,能够避免高并发场景下重复查询数据的问题。
3)读写锁的升级与降级
上面按需加载的示例代码中,在①处获取读锁,在③处释放读锁,那是否可以在②处的下面增加验证缓存并更新缓存的逻辑呢?详细的代码如下。
//读缓存
r.lock(); ①
try {
v = m.get(key); ②
if (v == null) {
w.lock();
try {
//再次验证并更新缓存
//省略详细代码
} finally{
w.unlock();
}
}
} finally{
r.unlock(); ③
}
这样看上去好像是没有问题的,先是获取读锁,然后再升级为写锁,对此还有个专业的名字,叫锁的升级。可惜ReadWriteLock并不支持这种升级。在上面的代码示例中,读锁还没有释放,此时获取写锁,会导致写锁永久等待,最终导致相关线程都被阻塞,永远也没有机会被唤醒。锁的升级是不允许的,这个你一定要注意。
不过,虽然锁的升级是不允许的,但是锁的降级却是允许的。以下代码来源自ReentrantReadWriteLock的官方示例,略做了改动。你会发现在代码①处,获取读锁的时候线程还是持有写锁的,这种锁的降级是支持的。
class CachedData {
Object data;
volatile boolean cacheValid;
final ReadWriteLock rwl = new ReentrantReadWriteLock();
// 读锁
final Lock r = rwl.readLock();
//写锁
final Lock w = rwl.writeLock();
void processCachedData() {
// 获取读锁
r.lock();
if (!cacheValid) {
// 释放读锁,因为不允许读锁的升级
r.unlock();
// 获取写锁
w.lock();
try {
// 再次检查状态
if (!cacheValid) {
data = ...
cacheValid = true;
}
// 释放写锁前,降级为读锁
// 降级是可以的
r.lock(); ①
} finally {
// 释放写锁
w.unlock();
}
}
// 此处仍然持有读锁
try {use(data);}
finally {r.unlock();}
}
}
4)源码分析
4.1 类结构
public class ReentrantReadWriteLock
implements ReadWriteLock, java.io.Serializable {
// 属性
/** Inner class providing readlock 读锁 */
private final ReentrantReadWriteLock.ReadLock readerLock;
/** Inner class providing writelock 写锁 */
private final ReentrantReadWriteLock.WriteLock writerLock;
/** Performs all synchronization mechanics 锁的主体 AQS */
final Sync sync;
// 内部类
/**
* Synchronization implementation for ReentrantReadWriteLock.
* Subclassed into fair and nonfair versions.
*/
abstract static class Sync extends AbstractQueuedSynchronizer{}
/**
* Nonfair version of Sync
*/
static final class NonfairSync extends Sync{}
/**
* Fair version of Sync
*/
static final class FairSync extends Sync{}
/**
* The lock returned by method {@link ReentrantReadWriteLock#readLock}.
*/
public static class ReadLock implements Lock, java.io.Serializable{}
/**
* The lock returned by method {@link ReentrantReadWriteLock#writeLock}.
*/
public static class WriteLock implements Lock, java.io.Serializable{}
}
// 构造方法
/**
* Creates a new {@code ReentrantReadWriteLock} with
* default (nonfair) ordering properties.
*/
public ReentrantReadWriteLock() {
this(false);
}
/**
* Creates a new {@code ReentrantReadWriteLock} with
* the given fairness policy.
*
* @param fair {@code true} if this lock should use a fair ordering policy
*/
public ReentrantReadWriteLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
readerLock = new ReadLock(this);
writerLock = new WriteLock(this);
}
ReentrantReadWriteLock与ReentrantLock一样,其锁主体依然是Sync,读写锁其实就是两个属性:readerLock、writerLock。
一个ReentrantReadWriteLock对象都对应着读锁和写锁两个锁,而这两个锁是通过同一个sync(AQS)实现的。
4.2 记录读写锁的状态
我们知道AQS.state使用来表示同步状态的。ReentrantLock中,state=0表示没有线程占用锁,state>0时state表示线程的重入次数。但是读写锁ReentrantReadWriteLock内部维护着两个锁,需要用state这一个变量维护多种状态,应该怎么办呢?
读写锁采用“按位切割使用”的方式,将state这个int变量分为高16位和低16位,高16位记录读锁状态,低16位记录写锁状态,并通过位运算来快速获取当前的读写锁状态。
/**
* Synchronization implementation for ReentrantReadWriteLock.
* Subclassed into fair and nonfair versions.
*/
abstract static class Sync extends AbstractQueuedSynchronizer {
private static final long serialVersionUID = 6317671515068378041L;
/*
* Read vs write count extraction constants and functions.
* Lock state is logically divided into two unsigned shorts:
* The lower one representing the exclusive (writer) lock hold count,
*
* 将state这个int变量分为高16位和低16位,
* 高16位记录读锁状态,低16位记录写锁状态
*
* and the upper the shared (reader) hold count.
*/
static final int SHARED_SHIFT = 16;
static final int SHARED_UNIT = (1 << SHARED_SHIFT);
static final int MAX_COUNT = (1 << SHARED_SHIFT) - 1;
static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1;
/**
* Returns the number of shared holds represented in count
* 获取读锁的状态,读锁的获取次数(包括重入)
* c无符号补0右移16位,获得高16位
*/
static int sharedCount(int c) { return c >>> SHARED_SHIFT; }
/**
* Returns the number of exclusive holds represented in count
* 获取写锁的状态,写锁的重入次数
* c & 0x0000FFFF,将高16位全部抹去,获得低16位
*/
static int exclusiveCount(int c) { return c & EXCLUSIVE_MASK;
}
2.3 记录获取锁的线程
线程获取写锁后,和重入锁一样,将AQS.exclusiveOwnerThread置为当前线程。但是读锁是共享的,可以多个线程同时获取读锁,那么如何记录获取读锁的多个线程以及每个线程的重入情况呢?
sycn中提供了一个HoldCounter类,类似计数器,用于记录一个线程读锁的重入次数。将HoldCounter通过ThreadLocal与线程绑定。
/**
* Synchronization implementation for ReentrantReadWriteLock.
* Subclassed into fair and nonfair versions.
*/
abstract static class Sync extends AbstractQueuedSynchronizer {
/**
* A counter for per-thread read hold counts.
* Maintained as a ThreadLocal; cached in cachedHoldCounter
* 这个嵌套类的实例用来记录每个线程持有的读锁数量(读锁重入)
*/
static final class HoldCounter {
int count = 0; // 读锁重入次数
// Use id, not reference, to avoid garbage retention
final long tid = getThreadId(Thread.currentThread()); // 线程ID
}
/**
* ThreadLocal subclass. Easiest to explicitly define for sake
* of deserialization mechanics. ThreadLocal 的子类
*/
static final class ThreadLocalHoldCounter
extends ThreadLocal<HoldCounter> {
public HoldCounter initialValue() {
return new HoldCounter();
}
}
/**
* The number of reentrant read locks held by current thread.
* Initialized only in constructor and readObject.
* Removed whenever a thread's read hold count drops to 0.
*
* 组合使用上面两个类,用一个 ThreadLocal 来记录当前线程持有的读锁数量
*/
private transient ThreadLocalHoldCounter readHolds;
/**
* The hold count of the last thread to successfully acquire
* readLock. This saves ThreadLocal lookup in the common case
* where the next thread to release is the last one to
* acquire. This is non-volatile since it is just used
* as a heuristic, and would be great for threads to cache.
*
* 记录"最后一个获取读锁的线程"的读锁重入次数,用于缓存提高性能
*
* <p>Can outlive the Thread for which it is caching the read
* hold count, but avoids garbage retention by not retaining a
* reference to the Thread.
*
* <p>Accessed via a benign data race; relies on the memory
* model's final field and out-of-thin-air guarantees.
*/
private transient HoldCounter cachedHoldCounter;
/**
* firstReader is the first thread to have acquired the read lock.
* firstReaderHoldCount is firstReader's hold count.
*
* <p>More precisely, firstReader is the unique thread that last
* changed the shared count from 0 to 1, and has not released the
* read lock since then; null if there is no such thread.
*
* <p>Cannot cause garbage retention unless the thread terminated
* without relinquishing its read locks, since tryReleaseShared
* sets it to null.
*
* <p>Accessed via a benign data race; relies on the memory
* model's out-of-thin-air guarantees for references.
*
* <p>This allows tracking of read holds for uncontended read
* locks to be very cheap.
*/
// 第一个获取读锁的线程(并且其未释放读锁)
private transient Thread firstReader = null;
// 第一个获取读锁的线程重入的读锁数量
private transient int firstReaderHoldCount;
}
属性cachedHoldCounter、firstReader、firstReaderHoldCount都是为了提高性能,线程与HoldCounter的存储结构如下图:

4.4 读锁获取
查看使用示例中 rwl.readLock().lock() 的实现:
/**
* Acquires the read lock.
*
* <p>Acquires the read lock if the write lock is not held by
* another thread and returns immediately.
*
* rwl.readLock().lock()-->ReadLock.lock()
*
* <p>If the write lock is held by another thread then
* the current thread becomes disabled for thread scheduling
* purposes and lies dormant until the read lock has been acquired.
*/
public void lock() {
sync.acquireShared(1);
}
/**
* Acquires in shared mode, ignoring interrupts. Implemented by
* first invoking at least once {@link #tryAcquireShared},
* returning on success. Otherwise the thread is queued, possibly
* repeatedly blocking and unblocking, invoking {@link
* #tryAcquireShared} until success.
*
* ReadLock.lock()-->AQS.acquireShared(int)
* sync 重写了 tryAcquireShared() 方法
*
* @param arg the acquire argument. This value is conveyed to
* {@link #tryAcquireShared} but is otherwise uninterpreted
* and can represent anything you like.
*/
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
4.4.1 tryAcquireShared 尝试获取读锁
tryAcquireShared() :尝试获取读锁,获取到锁返回 1,获取不到返回 -1,首先来分析一下可以获取读锁的条件:
- 当前锁的状态:读锁写锁都没有被占;只有读锁被占用;写锁被自己线程占用。简单总结就是:只有在其它线程持有写锁时,不能获取读锁,其它情况都可以去获取;
- AQS队列中的情况,如果是公平锁,同步队列中有线程等锁时,当前线程是不可以先获取锁的,必须到队列中排队;
- 读锁的标志位只有16位,最多只能有2^16-1个线程获取读锁或重入。
/**
* 尝试获取读锁,获取到锁返回1,获取不到返回-1
*/
protected final int tryAcquireShared(int unused) {
/*
* Walkthrough:
* 1. If write lock held by another thread, fail.
* 2. Otherwise, this thread is eligible for
* lock wrt state, so ask if it should block
* because of queue policy. If not, try
* to grant by CASing state and updating count.
* Note that step does not check for reentrant
* acquires, which is postponed to full version
* to avoid having to check hold count in
* the more typical non-reentrant case.
* 3. If step 2 fails either because thread
* apparently not eligible or CAS fails or count
* saturated, chain to version with full retry loop.
*/
Thread current = Thread.currentThread();
int c = getState();
if (exclusiveCount(c) != 0 && // 写锁被占用
getExclusiveOwnerThread() != current) // 持有写锁的不是当前线程
return -1;
int r = sharedCount(c);
// 检查AQS队列中的情况,看是当前线程是否可以获取读锁,下文有解释
if (!readerShouldBlock() &&
r < MAX_COUNT && // 读锁的标志位只有16位,最多之能有2^16-1个线程获取读锁或重入
// 在state的第17位加1,也就是将读锁标志位加1
compareAndSetState(c, c + SHARED_UNIT)) {
/*
* 到这里已经获取到读锁了
* 以下是修改记录获取读锁的线程和重入次数,
* 以及缓存firstReader和cachedHoldCounter
*/
if (r == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
cachedHoldCounter = rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
}
return 1;
}
/*
* 到这里
* 没有获取到读锁,因为上面代码获取到读锁的话已经在上一个if里返回1了
* 锁的状态是满足获取读锁的,因为不满足的上面返回-1了
* 所以没有获取到读锁的原因:AQS队列不满足获取读锁条件,
* 或者CAS失败,或者16位标志位满了
* 像CAS失败这种原因,是一定要再尝试获取的,所以这里再次尝试获取读锁,
* fullTryAcquireShared()方法下文有详细讲解
*/
return fullTryAcquireShared(current);
}
2.4.1.1 readerShouldBlock
readerShouldBlock():检查AQS队列中的情况,看是当前线程是否可以获取读锁,返回true表示当前不能获取读锁。分别看下公平锁和非公平锁的实现:
公平锁FairSync:
对于公平锁来说,如果队列中还有线程在等锁,就不允许新来的线程获得锁,必须进入队列排队。
hasQueuedPredecessors() 方法在重入锁的文章中分析过,判断同步队列中是否还有等锁的线程,如果有其他线程等锁,返回true当前线程不能获取读锁。
/**
* Fair version of Sync
*/
static final class FairSync extends Sync {
private static final long serialVersionUID = -2274990926593161451L;
final boolean readerShouldBlock() {
return hasQueuedPredecessors();
}
}
非公平锁NonfairSync:
对于非公平锁来说,原本是不需要关心队列中的情况,有机会直接尝试抢锁就好了,这里问什么会限制获取锁呢?
这里给写锁定义了更高的优先级,如果队列中第一个等锁的线程请求的是写锁,那么当前线程就不能跟那个马上就要获取写锁的线程抢,这样做很好的避免了写锁饥饿。
/**
* Nonfair version of Sync
*/
static final class NonfairSync extends Sync {
private static final long serialVersionUID = -8159625535654395037L;
final boolean readerShouldBlock() {
/* As a heuristic to avoid indefinite writer starvation,
* block if the thread that momentarily appears to be head
* of queue, if one exists, is a waiting writer. This is
* only a probabilistic effect since a new reader will not
* block if there is a waiting writer behind other enabled
* readers that have not yet drained from the queue.
*
* 队列中第一个等锁的线程请求的是写锁时,返回true,当前线程不能获取读锁
*/
return apparentlyFirstQueuedIsExclusive();
}
}
/**
* Returns {@code true} if the apparent first queued thread, if one
* exists, is waiting in exclusive mode. If this method returns
* {@code true}, and the current thread is attempting to acquire in
* shared mode (that is, this method is invoked from {@link
* #tryAcquireShared}) then it is guaranteed that the current thread
* is not the first queued thread. Used only as a heuristic in
* ReentrantReadWriteLock.
* AbstractQueuedSynchronizer 类中方法
* 返回true-队列中第一个等锁的线程请求的是写锁
*
*/
final boolean apparentlyFirstQueuedIsExclusive() {
Node h, s;
return (h = head) != null &&
(s = h.next) != null &&
!s.isShared() && // head后继节点线程请求写锁
s.thread != null;
}
4.4.1.2 fullTryAcquireShared
tryAcquireShared() 方法中因为 CAS 抢锁失败等原因没有获取到读锁的,fullTryAcquireShared() 再次尝试获取读锁。此外,fullTryAcquireShared() 还处理了读锁重入的情况。
/**
* 再次尝试获取读锁
*/
final int fullTryAcquireShared(Thread current) {
HoldCounter rh = null;
for (;;) {// 注意这里是循环
int c = getState();
if (exclusiveCount(c) != 0) {
// 仍然是先检查锁状态:在其它线程持有写锁时,不能获取读锁,返回-1
if (getExclusiveOwnerThread() != current)
return -1;
} else if (readerShouldBlock()) {
/*
* exclusiveCount(c) == 0 写锁没有被占用
* readerShouldBlock() == true,AQS同步队列中的线程在等锁,
* 当前线程不能抢读锁
* 既然当前线程不能抢读锁,为什么没有直接返回呢?
* 因为这里还有一种情况是可以获取读锁的,那就是读锁重入。
* 以下代码就是检查如果不是重入的话,return -1,不能继续往下获取锁。
*/
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
} else {
if (rh == null) {
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current)) {
rh = readHolds.get();
if (rh.count == 0)
readHolds.remove();
}
}
if (rh.count == 0)
return -1;
}
}
if (sharedCount(c) == MAX_COUNT)
throw new Error("Maximum lock count exceeded");
// CAS修改读锁标志位,修改成功表示获取到读锁;
// CAS失败,则进入下一次for循环继续CAS抢锁
if (compareAndSetState(c, c + SHARED_UNIT)) {
/*
* 到这里已经获取到读锁了
* 以下是修改记录获取读锁的线程和重入次数,
* 以及缓存firstReader和cachedHoldCounter
*/
if (sharedCount(c) == 0) {
firstReader = current;
firstReaderHoldCount = 1;
} else if (firstReader == current) {
firstReaderHoldCount++;
} else {
if (rh == null)
rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
else if (rh.count == 0)
readHolds.set(rh);
rh.count++;
cachedHoldCounter = rh; // cache for release
}
return 1;
}
}
}
4.4.1.3 doAcquireShared
再回到最开始的 acquireShared(),tryAcquireShared() 抢锁成功,直接返回,执行同步代码;如果 tryAcquireShared() 抢锁失败,调用 doAcquireShared()。
doAcquireShared() 应该比较熟悉了吧,类似 AQS 那篇中分析过 acquireQueued():
- 将当前线程构成节点 node;
- 如果 node 是 head 的后继节点就可以继续尝试抢锁;
- 如果 node 不是 head 的后继节点,将 node 加入队列的队尾,并将当前线程阻塞,等待 node 的前节点获取、释放锁之后唤醒 node 再次抢锁;
- node 抢到读锁之后执行 setHeadAndPropagate() 方法,setHeadAndPropagate() 是获取读锁的特殊之处,
public final void acquireShared(int arg) {
if (tryAcquireShared(arg) < 0)
doAcquireShared(arg);
}
private void doAcquireShared(int arg) {
// 把当前线程构造成节点,Node.SHARED表示共享锁
final Node node = addWaiter(Node.SHARED);
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();
if (p == head) {// 前驱节点是head,node才能去抢锁
int r = tryAcquireShared(arg);// 抢锁,上文分析了
if (r >= 0) {// r>0表示抢锁成功
setHeadAndPropagate(node, r);
p.next = null; // help GC
if (interrupted)
selfInterrupt();
failed = false;
return;
}
}
// 判断node前驱节点状态,将当前线程阻塞
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
4.4.1.4 setHeadAndPropagate
试想一种情况:当线程1持有写锁时,线程2、线程3、线程4、线程5…来获取读锁是获取不到的,只能排进同步队列。当线程1释放写锁时,唤醒线程2来获取锁。因为读锁是共享锁,当线程2获取到读锁时,线程3也应该被唤醒来获取读锁。
setHeadAndPropagate()方法就是在一个线程获取读锁之后,唤醒它之后排队获取读锁的线程的。该方法可以保证线程2获取读锁后,唤醒线程3获取读锁,线程3获取读锁后,唤醒线程4获取读锁,直到遇到后继节点是要获取写锁时才结束。
private void setHeadAndPropagate(Node node, int propagate) {
Node h = head;
setHead(node);// 因为node获取到锁了,所以设置node为head
if (propagate > 0 || h == null || h.waitStatus < 0 ||
(h = head) == null || h.waitStatus < 0) {
Node s = node.next;
if (s == null || s.isShared())// node后继节点线程要获取读锁,此时node就是head
doReleaseShared();// 唤醒head后继节点(也就是node.next)获取锁
}
}
4.5 读锁释放
理解了上文读锁的获取过程,读锁的释放过程不看源码也应该可以分析出来:
- 处理 firstReader、cachedHoldCounter、readHolds 获取读锁线程及读锁重入次数;
- 修改读锁标志位 state 的高16位;
- 释放读锁之后,如果队列中还有线程等锁,唤醒同步队列 head 后继节点等待写锁的线程。这里为什么是写锁?因为线程持有读锁时会把它之后要获取读锁的线程全部唤醒直到遇到写锁。
/**
* rwl.readLock().unlock()-->ReadLock.unlock()
*/
public void unlock() {
sync.releaseShared(1);
}
/**
* sync.releaseShared(1)-->AQS.releaseShared(int)
*/
public final boolean releaseShared(int arg) {
if (tryReleaseShared(arg)) {// 当前线程释放读锁,下文介绍
/*
* 到这里,已经没有任何线程占用锁,调用 doReleaseShared()
* 唤醒之后获取写锁的线程
* 如果同步队列中还有线程在排队,head后继节点的线程一定是要获取写锁,
* 因为线程持有读锁时会把它之后要获取读锁的线程全部唤醒
*/
doReleaseShared();// 唤醒head后继节点获取锁
return true;
}
return false;
}
/**
* 释放读锁
* 当前线程释放读锁之后,没有线程占用锁,返回true
*/
protected final boolean tryReleaseShared(int unused) {
Thread current = Thread.currentThread();
// 处理firstReader、cachedHoldCounter、readHolds
// 获取读锁线程及读锁重入次数
if (firstReader == current) {
// assert firstReaderHoldCount > 0;
if (firstReaderHoldCount == 1)
firstReader = null;
else
firstReaderHoldCount--;
} else {
HoldCounter rh = cachedHoldCounter;
if (rh == null || rh.tid != getThreadId(current))
rh = readHolds.get();
int count = rh.count;
if (count <= 1) {
readHolds.remove();
if (count <= 0)
throw unmatchedUnlockException();
}
--rh.count;
}
for (;;) {
int c = getState();
int nextc = c - SHARED_UNIT;// state第17位-1,也就是读锁状态标志位-1
// CAS设置state,CAS失败自旋进入下一次for循环
if (compareAndSetState(c, nextc))
return nextc == 0;// state=0表示没有线程占用锁,返回true
}
}
上文例子中 rwl.writeLock().lock() 的调用:
public void lock() {
sync.acquire(1);
}
public final void acquire(int arg) {
if (!tryAcquire(arg) && // 写锁实现了获取锁的方法,下文详细讲解
// 获取锁失败进入同步队列,等待被唤醒,AQS一文中重点讲过
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
先分析一下可以获取写锁的条件:
- 当前锁的状态:没有线程占用锁(读写锁都没被占用);线程占用写锁时,线程再次来获取写锁,也就是重入;
- AQS队列中的情况,如果是公平锁,同步队列中有线程等锁时,当前线程是不可以先获取锁的,必须到队列中排队;
- 写锁的标志位只有16位,最多重入2^16-1次。
/**
* ReentrantReadWriteLock.Sync.tryAcquire(int)
*/
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);// 写锁标志位
// 进到这个if里,c!=0表示有线程占用锁
// 当有线程占用锁时,只有一种情况是可以获取写锁的,那就是写锁重入
if (c != 0) {
/*
* 两种情况返回false
* 1.(c != 0 & w == 0)
* c!=0表示标志位!=0,w==0表示写锁标志位==0,
* 总的标志位不为0而写锁标志位(低16位)为0,只能是读锁标志位(高16位)不为0
* 也就是有线程占用读锁,此时不能获取写锁,返回false
*
* 2.(c != 0 & w != 0 & current != getExclusiveOwnerThread())
* c != 0 & w != 0 表示写锁标志位不为0,有线程占用写锁
* current != getExclusiveOwnerThread() 占用写锁的线程不是当前线程
* 不能获取写锁,返回false
*/
if (w == 0 || current != getExclusiveOwnerThread())
return false;
// 重入次数不能超过2^16-1
if (w + exclusiveCount(acquires) > MAX_COUNT)
throw new Error("Maximum lock count exceeded");
/*
* 修改标志位
* 这里修改标志位为什么没有用CAS原子操作呢?
* 因为到这里肯定是写锁重入了,写锁是独占锁,不会有其他线程来捣乱。
*/
setState(c + acquires);
return true;
}
/*
* 到这里表示锁是没有被线程占用的,因为锁被线程占用的情况在上个if里处理并返回了
* 所以这里直接检查AQS队列情况,没问题的话CAS修改标志位获取锁
*/
// 检查AQS队列中的情况,看是当前线程是否可以获取写锁
if (writerShouldBlock() ||
!compareAndSetState(c, c + acquires)) // 修改写锁标志位
return false;
// 获取写锁成功,将AQS.exclusiveOwnerThread置为当前线程
setExclusiveOwnerThread(current);
return true;
}
4.6.1 writerShouldBlock
writerShouldBlock():检查AQS队列中的情况,看是当前线程是否可以获取写锁,返回false表示可以获取写锁。
对于公平锁来说,如果队列中还有线程在等锁,就不允许新来的线程获得锁,必须进入队列排队。hasQueuedPredecessors()方法在重入锁的文章中分析过,判断同步队列中是否还有等锁的线程,如果有其他线程等锁,返回true当前线程不能获取读锁。
// 公平锁
final boolean writerShouldBlock() {
return hasQueuedPredecessors();
}
对于非公平锁来说,不需要关心队列中的情况,有机会直接尝试抢锁就好了,所以直接返回false。
// 非公平锁
final boolean writerShouldBlock() {
return false;
}
4.7 写锁释放
写锁释放比较简单,跟之前的重入锁释放基本类似,看下源码:
public void unlock() {
sync.release(1);
}
/**
* 释放写锁,如果释放之后没有线程占用写锁,唤醒队列中的线程来获取锁
*/
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);// 唤醒head的后继节点去获取锁
return true;
}
return false;
}
/**
* 释放写锁,修改写锁标志位和exclusiveOwnerThread
* 如果这个写锁释放之后,没有线程占用写锁了,返回true
*/
protected final boolean tryRelease(int releases) {
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
int nextc = getState() - releases;
boolean free = exclusiveCount(nextc) == 0;
if (free)
setExclusiveOwnerThread(null);
setState(nextc);
return free;
}
2.8 锁降级
读写锁支持锁降级。锁降级就是写锁是可以降级为读锁的,但是需要遵循获取写锁、获取读锁、释放写锁的次序。
为什么要支持锁降级?
支持降级锁的情况:线程A 持有写锁时,线程A要读取共享数据,线程A 直接获取读锁读取数据就好了。
如果不支持锁降级会怎么样?
线程A 持有写锁时,线程A 要读取共享数据,但是线程A 不能获取读锁,只能等待释放写锁。
当线程A 释放写锁之后,线程A 获取读锁要和其他线程抢锁,如果另一个线程B 抢到了写锁,对数据进行了修改,那么线程B 释放写锁之后,线程A 才能获取读锁。线程B 获取到读锁之后读取的数据就不是线程A 修改的数据了,也就是脏数据。
源码中体现锁降级?
tryAcquireShared() 方法中,当前线程占用写锁时是可以获取读锁的,如下:
protected final int tryAcquireShared(int unused) {
Thread current = Thread.currentThread();
int c = getState();
/*
* 根据锁的状态判断可以获取读锁的情况:
* 1. 读锁写锁都没有被占用
* 2. 只有读锁被占用
* 3. 写锁被自己线程占用
* 总结一下,只有在其它线程持有写锁时,不能获取读锁,其它情况都可以去获取。
*/
if (exclusiveCount(c) != 0 && // 写锁被占用
getExclusiveOwnerThread() != current) // 持有写锁的不是当前线程
return -1;
...
4.8.2 锁升级
持有写锁的线程,去获取读锁的过程称为锁降级;持有读锁的线程,在没释放的情况下不能去获取写锁的过程称为锁升级。
读写锁是不支持锁升级的。获取写锁的tryAcquire()方法:
protected final boolean tryAcquire(int acquires) {
Thread current = Thread.currentThread();
int c = getState();
int w = exclusiveCount(c);
/*
* (c != 0 & w == 0)时返回false,不能获取写锁
* c != 0 表示state不是0
* w == 0 表示写锁标志位state的低16位为0
* 所以state的高16位不为0,也就是有线程占有读锁
* 也就是说只要有线程占有读锁返回false,不能获取写锁,
* 当然线程自己持有读锁时也就不能获取写锁了
*/
if (c != 0) {
if (w == 0 || current != getExclusiveOwnerThread())
return false;
...
4)小结
大多数业务场景,都是读多写少的,采用互斥锁性能较差,所以提供了读写锁。读写锁允许共享资源在同一时刻可以被多个读线程访问,但是在写线程访问时,所有的读线程和其他的写线程都会被阻塞。
一个 ReentrantReadWriteLock 对象都对应着读锁和写锁两个锁,而这两个锁是通过同一个 sync(AQS)实现的。
读写锁采用“按位切割使用”的方式,将 state 这个 int 变量分为高 16位和低 16位,高 16位记录读锁状态,低 16位记录写锁状态。
读锁获取时,需要判断当时的写锁没有被其他线程占用即可,锁处于的其他状态都可以获取读锁。
对于写锁,可以获取写锁的情况只有两种:读锁和写锁都没有线程占用;当前线程占用写锁,也就写锁重入。
读写锁支持锁降级,不支持锁升级。锁降级就是写锁是可以降级为读锁的,但是需要遵循获取写锁、获取读锁、释放写锁的次序。
读写锁多用于解决读多写少的问题,最典型的就是缓存问题。
读写锁类似于ReentrantLock,也支持公平模式和非公平模式。读锁和写锁都实现了 java.util.concurrent.locks.Lock接口,所以除了支持lock()方法外,tryLock()、lockInterruptibly() 等方法也都是支持的。但是有一点需要注意,那就是只有写锁支持条件变量,读锁是不支持条件变量的,读锁调用newCondition()会抛出UnsupportedOperationException异常。
(二)StampedLock
上面我们介绍了读写锁,学习完之后你应该已经知道“读写锁允许多个线程同时读共享变量,适用于读多写少的场景”。
那在读多写少的场景中,还有没有更快的技术方案呢?还真有,Java在1.8这个版本里,提供了一种叫StampedLock的锁,它的性能就比读写锁还要好。
1)StampedLock支持三种锁模式
我们先看看在使用上StampedLock和ReadWriteLock有哪些区别。
- ReadWriteLock支持两种模式:一种是读锁,一种是写锁。
- 而StampedLock支持三种模式,分别是:写锁、悲观读锁和乐观读。
其中,写锁、悲观读锁的语义和ReadWriteLock的写锁、读锁的语义非常类似,允许多个线程同时获取悲观读锁,但是只允许一个线程获取写锁,写锁和悲观读锁是互斥的。
不同的是:StampedLock里的写锁和悲观读锁加锁成功之后,都会返回一个stamp;然后解锁的时候,需要传入这个stamp。相关的示例代码如下。
final StampedLock sl = new StampedLock();
// 获取/释放悲观读锁示意代码
long stamp = sl.readLock();
try {
//省略业务相关代码
} finally {
sl.unlockRead(stamp);
}
// 获取/释放写锁示意代码
long stamp = sl.writeLock();
try {
//省略业务相关代码
} finally {
sl.unlockWrite(stamp);
}
StampedLock的性能之所以比ReadWriteLock还要好,其关键是StampedLock支持乐观读的方式。
- ReadWriteLock支持多个线程同时读,但是当多个线程同时读的时候,所有的写操作会被阻塞;
- 而StampedLock提供的乐观读,是允许一个线程获取写锁的,也就是说不是所有的写操作都被阻塞。
注意这里,我们用的是“乐观读”这个词,而不是“乐观读锁”,是要提醒你,乐观读这个操作是无锁的,所以相比较ReadWriteLock的读锁,乐观读的性能更好一些。
文中下面这段代码是出自Java SDK官方示例,并略做了修改。在distanceFromOrigin()这个方法中,首先通过调用tryOptimisticRead()获取了一个stamp,这里的tryOptimisticRead()就是我们前面提到的乐观读。之后将共享变量x和y读入方法的局部变量中,不过需要注意的是,由于tryOptimisticRead()是无锁的,所以共享变量x和y读入方法局部变量时,x和y有可能被其他线程修改了。因此最后读完之后,还需要再次验证一下是否存在写操作,这个验证操作是通过调用validate(stamp)来实现的。
class Point {
private int x, y;
final StampedLock sl = new StampedLock();
//计算到原点的距离
int distanceFromOrigin() {
// 乐观读
long stamp = sl.tryOptimisticRead();
// 读入局部变量,
// 读的过程数据可能被修改
int curX = x, curY = y;
//判断执行读操作期间,
//是否存在写操作,如果存在,
//则sl.validate返回false
if (!sl.validate(stamp)){
// 升级为悲观读锁
stamp = sl.readLock();
try {
curX = x;
curY = y;
} finally {
//释放悲观读锁
sl.unlockRead(stamp);
}
}
return Math.sqrt(
curX * curX + curY * curY);
}
}
在上面这个代码示例中,如果执行乐观读操作的期间,存在写操作,会把乐观读升级为悲观读锁。这个做法挺合理的,否则你就需要在一个循环里反复执行乐观读,直到执行乐观读操作的期间没有写操作(只有这样才能保证x和y的正确性和一致性),而循环读会浪费大量的CPU。升级为悲观读锁,代码简练且不易出错,建议你在具体实践时也采用这样的方法。
2)进一步理解乐观读
如果你曾经用过数据库的乐观锁,可能会发现StampedLock的乐观读和数据库的乐观锁有异曲同工之妙。的确是这样的,就拿我个人来说,我是先接触的数据库里的乐观锁,然后才接触的StampedLock,我就觉得我前期数据库里乐观锁的学习对于后面理解StampedLock的乐观读有很大帮助,所以这里有必要再介绍一下数据库里的乐观锁。
还记得我第一次使用数据库乐观锁的场景是这样的:在ERP的生产模块里,会有多个人通过ERP系统提供的UI同时修改同一条生产订单,那如何保证生产订单数据是并发安全的呢?我采用的方案就是乐观锁。
乐观锁的实现很简单,在生产订单的表 product_doc 里增加了一个数值型版本号字段 version,每次更新product_doc这个表的时候,都将 version 字段加1。生产订单的UI在展示的时候,需要查询数据库,此时将这个 version 字段和其他业务字段一起返回给生产订单UI。假设用户查询的生产订单的id=777,那么SQL语句类似下面这样:
select id,... ,version
from product_doc
where id=777
用户在生产订单UI执行保存操作的时候,后台利用下面的SQL语句更新生产订单,此处我们假设该条生产订单的 version=9。
update product_doc
set version=version+1,...
where id=777 and version=9
如果这条SQL语句执行成功并且返回的条数等于1,那么说明从生产订单UI执行查询操作到执行保存操作期间,没有其他人修改过这条数据。因为如果这期间其他人修改过这条数据,那么版本号字段一定会大于9。
你会发现数据库里的乐观锁,查询的时候需要把 version 字段查出来,更新的时候要利用 version 字段做验证。这个 version 字段就类似于StampedLock里面的stamp。这样对比着看,相信你会更容易理解StampedLock里乐观读的用法。
3)StampedLock使用注意事项
对于读多写少的场景StampedLock性能很好,简单的应用场景基本上可以替代ReadWriteLock,但是StampedLock的功能仅仅是ReadWriteLock的子集,在使用的时候,还是有几个地方需要注意一下。
StampedLock在命名上并没有增加Reentrant,想必你已经猜测到StampedLock应该是不可重入的。事实上,的确是这样的,StampedLock不支持重入。这个是在使用中必须要特别注意的。
另外,StampedLock的悲观读锁、写锁都不支持条件变量,这个也需要你注意。
还有一点需要特别注意,那就是:如果线程阻塞在StampedLock的readLock()或者writeLock()上时,此时调用该阻塞线程的interrupt()方法,会导致CPU飙升。例如下面的代码中,线程T1获取写锁之后将自己阻塞,线程T2尝试获取悲观读锁,也会阻塞;如果此时调用线程T2的interrupt()方法来中断线程T2的话,你会发现线程T2所在CPU会飙升到100%。
final StampedLock lock
= new StampedLock();
Thread T1 = new Thread(()->{
// 获取写锁
lock.writeLock();
// 永远阻塞在此处,不释放写锁
LockSupport.park();
});
T1.start();
// 保证T1获取写锁
Thread.sleep(100);
Thread T2 = new Thread(()->
//阻塞在悲观读锁
lock.readLock()
);
T2.start();
// 保证T2阻塞在读锁
Thread.sleep(100);
//中断线程T2
//会导致线程T2所在CPU飙升
T2.interrupt();
T2.join();
所以,使用StampedLock一定不要调用中断操作,如果需要支持中断功能,一定使用可中断的悲观读锁readLockInterruptibly()和写锁writeLockInterruptibly()。这个规则一定要记清楚。
4)源码分析
4.1 锁状态
StampedLock 提供了写锁、悲观读锁、乐观读三种模式的锁,如何维护锁状态呢?StampedLock 的锁状态用 long 类型的 state 表示,类似ReentrantReadWriteLock,通过将 state 按位切分的方式表示不同的锁状态。
悲观读锁:state 的前 7 位(0-7 位)表示获取读锁的线程数,如果超过 0-7 位的最大容量 126,则使用一个名为 readerOverflow 的 int 整型保存超出数。
写锁:state 第 8 位为写锁标志,0 表示未被占用,1 表示写锁被占用。state 第 8-64 位表示写锁的获取次数,次数超过 64 位最大容量则重新从 1 开始。
乐观读:不需要维护锁状态,但是在具体操作数据前要检查一下自己操作的数据是否经过修改操作,也就是验证是否有线程获取过写锁。
你有没有想过为什么 state 要记录写锁的获取次数呢?写锁是不能重入的,如果只是修改第 8 位的状态,获取写锁时 state 第 8 位变为 1,释放写锁时 state 第 8 位变回 0 不是更方便?
如果只用第 8 位来标志写锁,那么来看乐观写锁的使用过程:
- 检查是否有写锁,state 第 8 位为 0,没有写锁,拷贝数据;
- 检查是否有线程获取过写锁,state 第 8 位为 0,没有线程获取过,直接使用原来拷贝的数据。
发现其中的问题了吗?第一次检查 state 第 8 位为 0 之后,有线程获取写锁修改数据并释放了写锁,那么之后在检查是否有线程获取过写锁时 state 第 8 位还是 0,认为没有线程获取过写锁,可能导致数据不一致。
也就是 ABA 问题,在《14 - CAS 无锁工具类的典范》文章中介绍过 ABA 问题的解决办法就是加版本号,将原来的 A->B->A 就变成了 1A->2B->3A。StampedLock 同样采用这种方法,将获取写锁的次数作为版本号,也就是乐观读锁的票据,写锁释放时次数加 1,也就是 state 第 8 位加 1。
state原始状态为 //...0001 0000 0000
获取写锁 //...0001 1000 0000
释放写锁次数加1 //...0010 0000 0000
获取写锁 // ...0010 1000 0000
释放写锁次数加1 //...0011 0000 0000JDK 设计的精妙之处还在于,获取写锁后 state 第 8 位为 1,释放写锁时 state 第 8 位加 1 使第 8 位变回 0,既记录了写锁次数,又可以保证 state 的第 8 位一个位置来标志写锁
4.2 属性
4.2.1 锁状态相关属性
// 一个单位的读锁 0000... 0000 0000 0001
private static final long RUNIT = 1L;
// 一个单位的写锁 0000... 0000 1000 0000
private static final long WBIT = 1L << LG_READERS;
// 读状态标识 0000... 0000 0111 1111
private static final long RBITS = WBIT - 1L;
// 读锁最大数量 0000... 0000 0111 1110
private static final long RFULL = RBITS - 1L;
// 用于获取读写状态 0000... 0000 1111 1111
private static final long ABITS = RBITS | WBIT;
// 1111... 1111 1000 0000
private static final long SBITS = ~RBITS;
// 锁state初始值,0000... 0001 0000 0000
private static final long ORIGIN = WBIT << 1;
/** 锁队列状态, 当处于写模式时第8位为1,读模式时前7为为1-126
(附加的readerOverflow用于当读者超过126时) */
private transient volatile long state;
/** 将state超过 RFULL=126的值放到readerOverflow字段中 */
private transient int readerOverflow;给出这些常量的比特位,等下看源码过程中会频繁用到
4.2.2 节点
StampedLock中,等待队列的结点要比 AQS 中简单些,仅仅三种状态。0:初始状态;-1:等待中;1:取消。结点的定义中有个 cowait 字段,该字段指向一个栈,用于保存读线程。
// 结点状态
private static final int WAITING = -1;
private static final int CANCELLED = 1;
// 结点的读写模式
private static final int RMODE = 0;
private static final int WMODE = 1;
/** Wait nodes */
static final class WNode {
volatile WNode prev;
volatile WNode next;
volatile WNode cowait; // 读模式使用该结点形成栈
volatile Thread thread; // non-null while possibly parked
volatile int status; // 0, WAITING, or CANCELLED
final int mode; // RMODE or WMODE
WNode(int m, WNode p) {
mode = m;
prev = p;
}
}
/** CLH队头结点 */
private transient volatile WNode whead;
/** CLH队尾结点 */
private transient volatile WNode wtail;4.3 写锁的获取与释放
写锁的获取:
- 可以获取写锁的条件:没有线程占用悲观读锁和写锁;
- 获取写锁,state 写锁位加 1,此时写锁标志位变为 1,返回邮戳 stamp;
- 获取失败,加入同步队列等待被唤醒。
写锁的释放:
- 传入获取写锁时的 stamp 验证;
- stamp 值被修改,抛出异常;
- stamp 正确,state 写锁位加 1,此时写锁标志位变为 0;
- 唤醒同步队列等锁线程。
/**
* 获取写锁,如果获取失败,进入阻塞
*/
public long writeLock() {
long s, next;
return ((((s = state) & ABITS) == 0L && // 没有读写锁
U.compareAndSwapLong(this, STATE, s, next = s + WBIT)) ?
// cas操作尝试获取写锁
// 获取成功后返回next,失败则进行后续处理,排队也在后续处理中
next : acquireWrite(false, 0L));
}
/**
* 释放写锁
*/
public void unlockWrite(long stamp) {
WNode h;
//stamp值被修改,或者写锁已经被释放,抛出错误
if (state != stamp || (stamp & WBIT) == 0L)
throw new IllegalMonitorStateException();
//加0000 1000 0000来记录写锁的变化,同时改变写锁状态
state = (stamp += WBIT) == 0L ? ORIGIN : stamp;
if ((h = whead) != null && h.status != 0)
release(h);// 唤醒等待队列的队首结点
}
/**
* 尝试自旋的获取写锁, 获取不到则阻塞线程
*
* @param interruptible true 表示检测中断, 如果线程被中断过,
* 则最终返回INTERRUPTED
* @param deadline 如果非0, 则表示限时获取
* @return 非0表示获取成功, INTERRUPTED表示中途被中断过
*/
private long acquireWrite(boolean interruptible, long deadline) {
WNode node = null, p;
/**
* 自旋入队操作
* 如果没有任何锁被占用, 则立即尝试获取写锁, 获取成功则返回.
* 如果存在锁被使用, 则将当前线程包装成独占结点, 并插入等待队列尾部
*/
for (int spins = -1; ; ) {
long m, s, ns;
if ((m = (s = state) & ABITS) == 0L) { // 没有任何锁被占用
if (U.compareAndSwapLong(this, STATE, s, ns = s + WBIT)) // 尝试立即获取写锁
return ns; // 获取成功直接返回
} else if (spins < 0)
spins = (m == WBIT && wtail == whead) ? SPINS : 0;
else if (spins > 0) {
if (LockSupport.nextSecondarySeed() >= 0)
--spins;
} else if ((p = wtail) == null) { // 队列为空, 则初始化队列, 构造队列的头结点
WNode hd = new WNode(WMODE, null);
if (U.compareAndSwapObject(this, WHEAD, null, hd))
wtail = hd;
} else if (node == null) // 将当前线程包装成写结点
node = new WNode(WMODE, p);
else if (node.prev != p)
node.prev = p;
else if (U.compareAndSwapObject(this, WTAIL, p, node)) {
// 链接结点至队尾
p.next = node;
break;
}
}
for (int spins = -1; ; ) {
WNode h, np, pp;
int ps;
// 如果当前结点是队首结点, 则立即尝试获取写锁
if ((h = whead) == p) {
if (spins < 0)
spins = HEAD_SPINS;
else if (spins < MAX_HEAD_SPINS)
spins <<= 1;
for (int k = spins; ; ) { // spin at head
long s, ns;
if (((s = state) & ABITS) == 0L) { // 写锁未被占用
if (U.compareAndSwapLong(this, STATE, s,
ns = s + WBIT)) { // CAS修改State: 占用写锁
// 将队首结点从队列移除
whead = node;
node.prev = null;
return ns;
}
} else if (LockSupport.nextSecondarySeed() >= 0
&& --k <= 0)
break;
}
} else if (h != null) { // 唤醒头结点的栈中的所有读线程
WNode c;
Thread w;
while ((c = h.cowait) != null) {
if (U.compareAndSwapObject(h, WCOWAIT, c, c.cowait)
&& (w = c.thread) != null)
U.unpark(w);
}
}
if (whead == h) {
if ((np = node.prev) != p) {
if (np != null)
(p = np).next = node; // stale
} else if ((ps = p.status) == 0)
// 将当前结点的前驱置为WAITING,
// 表示当前结点会进入阻塞, 前驱将来需要唤醒我
U.compareAndSwapInt(p, WSTATUS, 0, WAITING);
else if (ps == CANCELLED) {
if ((pp = p.prev) != null) {
node.prev = pp;
pp.next = node;
}
} else { // 阻塞当前调用线程
long time; // 0 argument to park means no timeout
if (deadline == 0L)
time = 0L;
else if ((time = deadline - System.nanoTime()) <= 0L)
return cancelWaiter(node, node, false);
Thread wt = Thread.currentThread();
U.putObject(wt, PARKBLOCKER, this);
node.thread = wt;
if (p.status < 0 && (p != h || (state & ABITS) != 0L)
&& whead == h && node.prev == p)
// emulate LockSupport.park
U.park(false, time);
node.thread = null;
U.putObject(wt, PARKBLOCKER, null);
if (interruptible && Thread.interrupted())
return cancelWaiter(node, node, true);
}
}
}
}
4.4 悲观锁的获取与释放
悲观锁的获取:
- 获取悲观读锁条件:没有线程占用写锁;
- 读锁标志位+1,返回邮戳 stamp;
- 获取失败加入同步队列。
悲观锁的释放:
- 传入邮戳 stamp 验证;
- stamp 验证失败,抛异常;
- stamp 验证成功,读锁标志位-1,唤醒同步队列等锁线程。
/**
* 获取悲观读锁,如果写锁被占用,线程阻塞
*/
public long readLock() {
long s = state, next;
//队列为空,无写锁,同时读锁未溢出,尝试获取读锁
return ((whead == wtail && (s & ABITS) < RFULL
&& U.compareAndSwapLong(this, STATE, s, next = s + RUNIT)) ?
//cas尝试获取读锁+1
//获取读锁成功,返回s + RUNIT,失败进入后续处理,类似acquireWrite
next : acquireRead(false, 0L));
}
/**
* 释放悲观读锁
*/
public void unlockRead(long stamp) {
long s, m; WNode h;
for (;;) {
if (((s = state) & SBITS) != (stamp & SBITS)
|| (stamp & ABITS) == 0L || (m = s & ABITS) == 0L || m == WBIT)
throw new IllegalMonitorStateException();
//小于最大记录值(最大记录值127超过后放在readerOverflow变量中)
if (m < RFULL) {
//cas尝试释放读锁-1
if (U.compareAndSwapLong(this, STATE, s, s - RUNIT)) {
if (m == RUNIT && (h = whead) != null && h.status != 0)
release(h);
break;
}
}
else if (tryDecReaderOverflow(s) != 0L) //readerOverflow - 1
break;
}
}
4.5 乐观读的获取
乐观读锁因为实际上没有获取过锁,所以也就没有释放锁的过程。
/**
* 尝试获取乐观锁
* 写锁被占用,返回state第8-64位的写锁记录;没被占用返回0
*/
public long tryOptimisticRead() {
long s;
return (((s = state) & WBIT) == 0L) ? (s & SBITS) : 0L;
}
/**
* 验证乐观锁获取之后是否有过写操作
*/
public boolean validate(long stamp) {
// 之前的所有load操作在内存屏障之前完成,对应的还有storeFence()及fullFence()
U.loadFence();
return (stamp & SBITS) == (state & SBITS); //比较是否有过写操作
}
5)总结
读写锁在读线程非常多,写线程很少的情况下可能会导致写线程饥饿,JDK1.8 新增的StampedLock通过乐观读锁来解决这一问题。StampedLock有三种访问模式:
- 写锁 writeLock:功能和读写锁的写锁类似;
- 悲观读锁 readLock:功能和读写锁的读锁类似;
- 乐观读 Optimistic reading:一种优化的读模式。
所有获取锁的方法,都返回一个票据 Stamp,Stamp 为 0 表示获取失败,其余都表示成功;所有释放锁的方法,都需要一个票据 Stamp,这个 Stamp 必须是和成功获取锁时得到的 Stamp 一致。
乐观读:乐观的认为在具体操作数据前其他线程不会对自己操作的数据进行修改,所以当前线程获取到乐观读的之后不会阻塞线程获取写锁。为了保证数据一致性,在具体操作数据前要检查一下自己操作的数据是否经过修改操作了,如果进行了修改操作,就重新读一次。因为乐观读不需要进行 CAS 设置锁的状态而只是简单的测试状态,所以在读多写少的情况下有更好的性能。
StampedLock 通过将 state 按位切分的方式表示不同的锁状态。
悲观读锁:state 的 0-7 位表示获取读锁的线程数,如果超过 0-7 位的最大容量 126,则使用一个名为 readerOverflow 的 int 整型保存超出数。
写锁:state 第 8 位为写锁标志,0 表示未被占用,1 表示写锁被占用。state 第 8-64 位表示写锁的获取次数,次数超过 64 位最大容量则重新从 1 开始。















 477
477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









