








背景
每个开发者都想了解自己任务运行时的状态,便于调优及排错,Spark 提供的 webui 已经提供了很多信息,用户可以从上面了解到任务的 shuffle,任务运行等信息,但是运行时 Executor JVM 的状态对用户来说是个黑盒,在应用内存不足报错时,初级用户可能不了解程序究竟是 Driver 还是 Executor 内存不足,从而也无法正确的去调整参数。
Spark 的度量系统提供了相关数据,我们需要做的只是将其采集并展示。
实现
技术方案
后端存储使用 Prometheus,类似的时序数据库还有 influxDB/opentsdb 等。
前端展示使用的 Grafana,也可以使用 Graphite 或者自己绘图 。
这套方案最大的好处就是所有的组件都是开箱即用。
在集群规模较大的情况下,建议可以先将指标采集到 kafka,然后再消费写入数据库。这样做对采集和数据库进行了解耦,还能在一定程度上能提高吞吐量,并且只需要实现一个 Kafka Sink,不需要对每个数据库进行适配。建议使用现成轮子:jvm-profiler
版本信息:
grafana-5.2.4
graphite_exporter-0.3.0
prometheus-2.3.2
采集数据写入数据库
spark 默认没有 Prometheus Sink ,这时候一般需要去自己实现一个,例如 spark-metrics。
其实 prometheus 还提供了一个插件(graphite_exporter),可以将 Graphite metrics 进行转化并写入 Prometheus (本文的方式),spark 是自带 Graphite Sink 的,这下省事了,只需要配置一把就可以生效了。
/path/to/spark/conf/metrics.properties
*.sink.graphite.class=org.apache.spark.metrics.sink.GraphiteSink
*.sink.graphite.host=<metrics_hostname>
*.sink.graphite.port=<metrics_port>
*.sink.graphite.period=5
*.sink.graphite.unit=seconds
driver.source.jvm.class=org.apache.spark.metrics.source.JvmSource
executor.source.jvm.class=org.apache.spark.metrics.source.JvmSource
提交时记得使用 --files /path/to/spark/conf/metrics.properties 参数将配置文件分发到所有的 Executor,否则将采集不到相应的 executor 数据。
启动应用后,如果采集成功,将在 http://<metrics_hostname>:<metrics_port>/metrics 页面中看到相应的信息。
例如:
# HELP application_1533838659288_1030_driver_CodeGenerator_compilationTime_count Graphite metric application_1533838659288_1030.driver.CodeGenerator.compilationTime.count
# TYPE application_1533838659288_1030_driver_CodeGenerator_compilationTime_count gauge
application_1533838659288_1030_driver_CodeGenerator_compilationTime_count 2
原生的 Graphite 数据可以通过映射文件转化为有 label 维度的 Prometheus 数据。
例如:
mappings:
- match: '*.*.jvm.*.*'
name: jvm_memory_usage
labels:
application: $1
executor_id: $2
mem_type: $3
qty: $4
上述文件会将数据转化成 metric name 为 jvm_memory_usage,label 为 application,executor_id,mem_type,qty 的格式。
application_1533838659288_1030_1_jvm_heap_usage -> jvm_memory_usage{application="application_1533838659288_1030",executor_id="driver",mem_type="heap",qty="usage"}
启动 graphite_exporter 时加载配置文件
./graphite_exporter --graphite.mapping-config=graphite_exporter_mapping
配置 Prometheus 从 graphite_exporter 获取数据
/path/to/prometheus/prometheus.yml
scrape_configs:
- job_name: 'spark'
static_configs:
- targets: ['localhost:9108']
dashboard 配置
增加 Prometheus 数据源
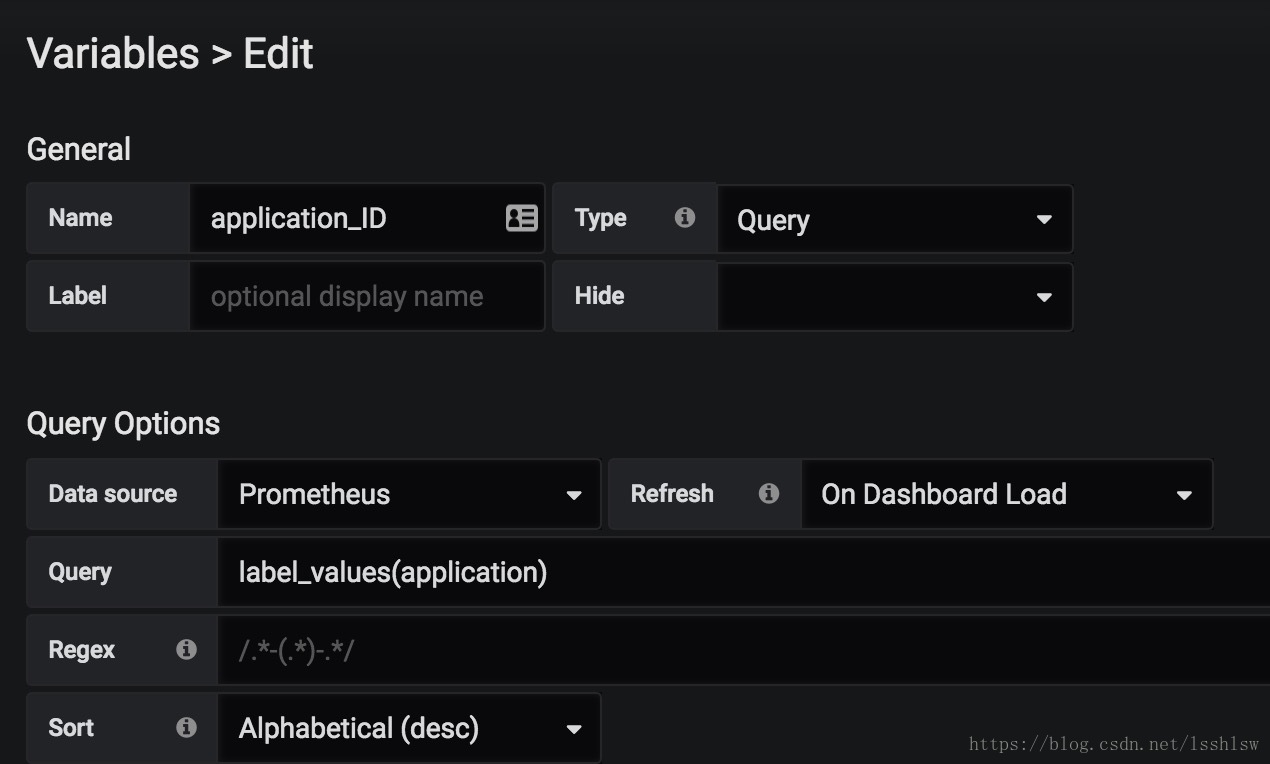
将 application label 加入 Variables 用于筛选不同的应用
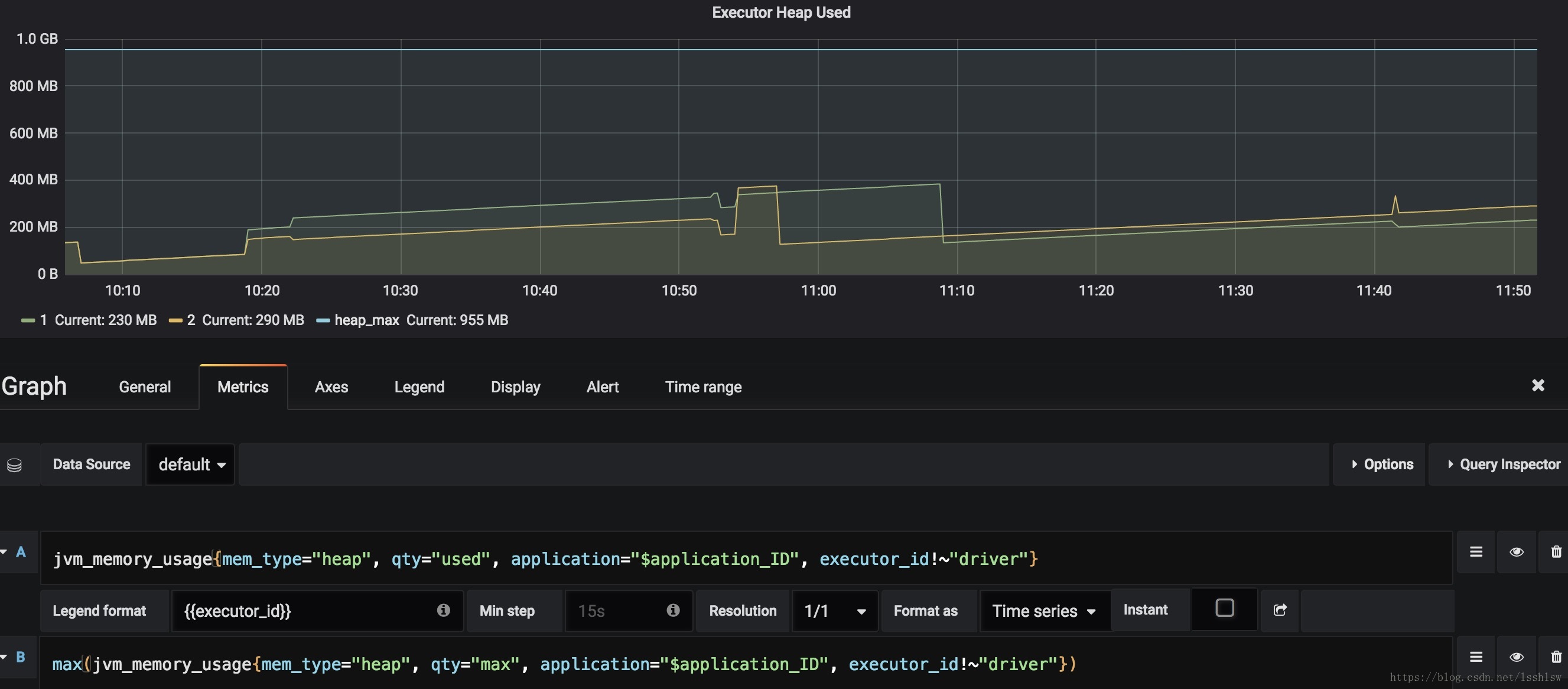
配置相应的图表
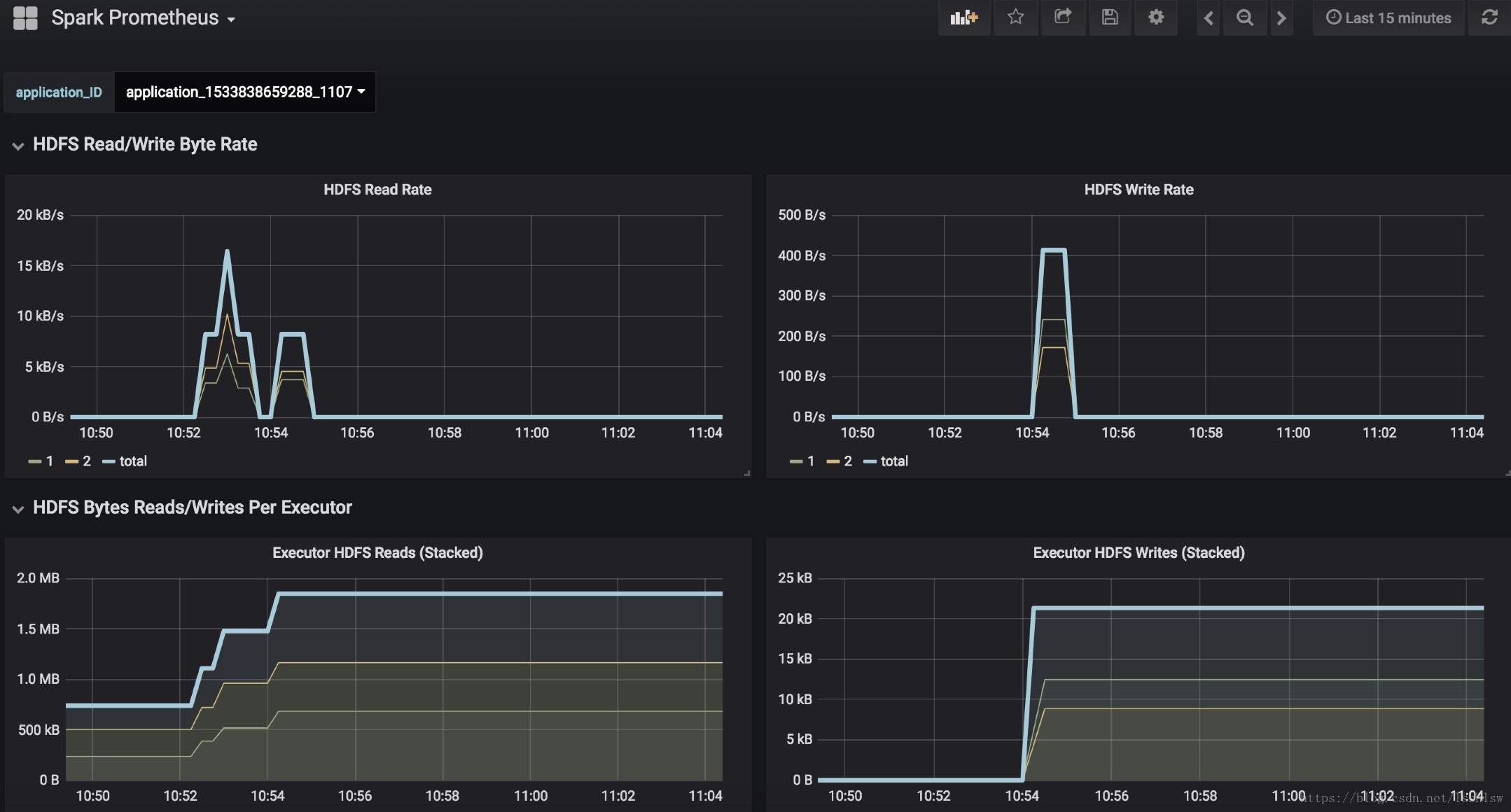
效果
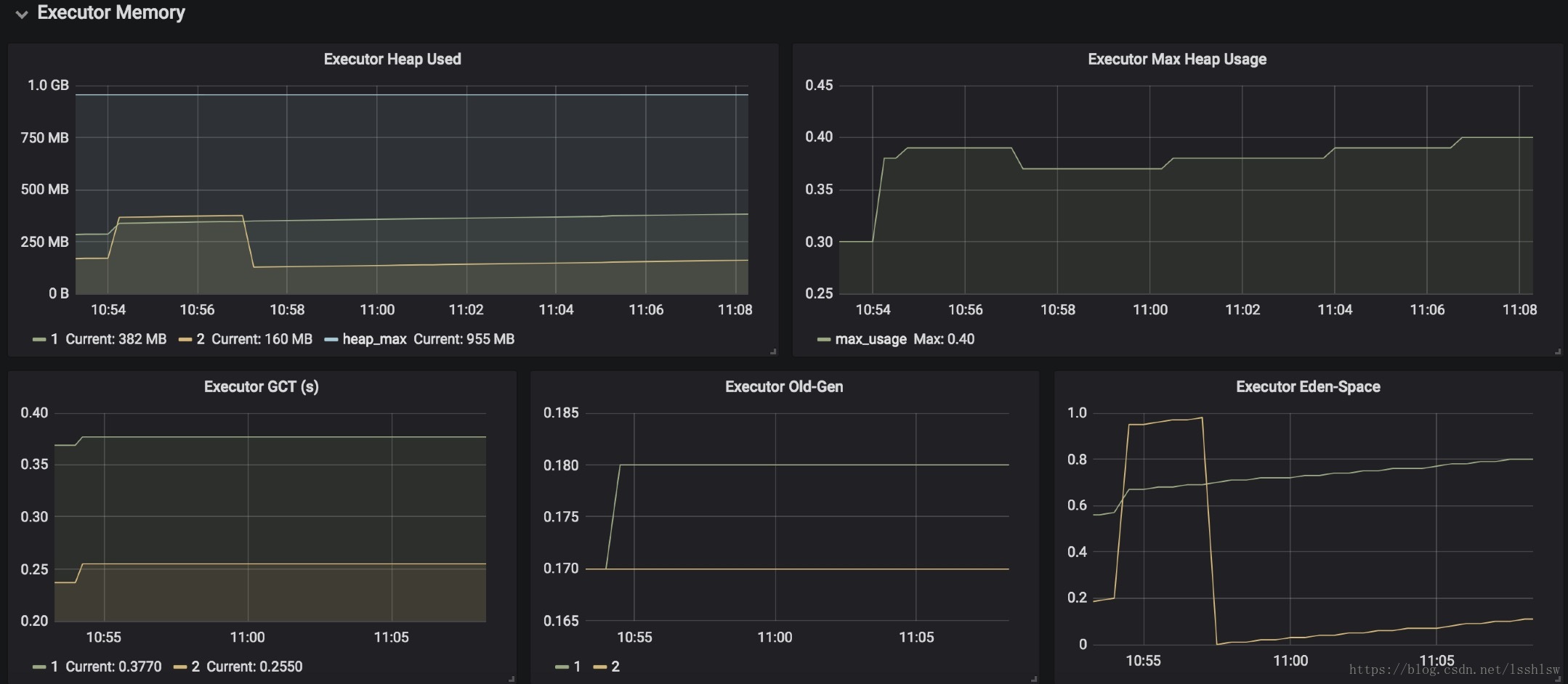
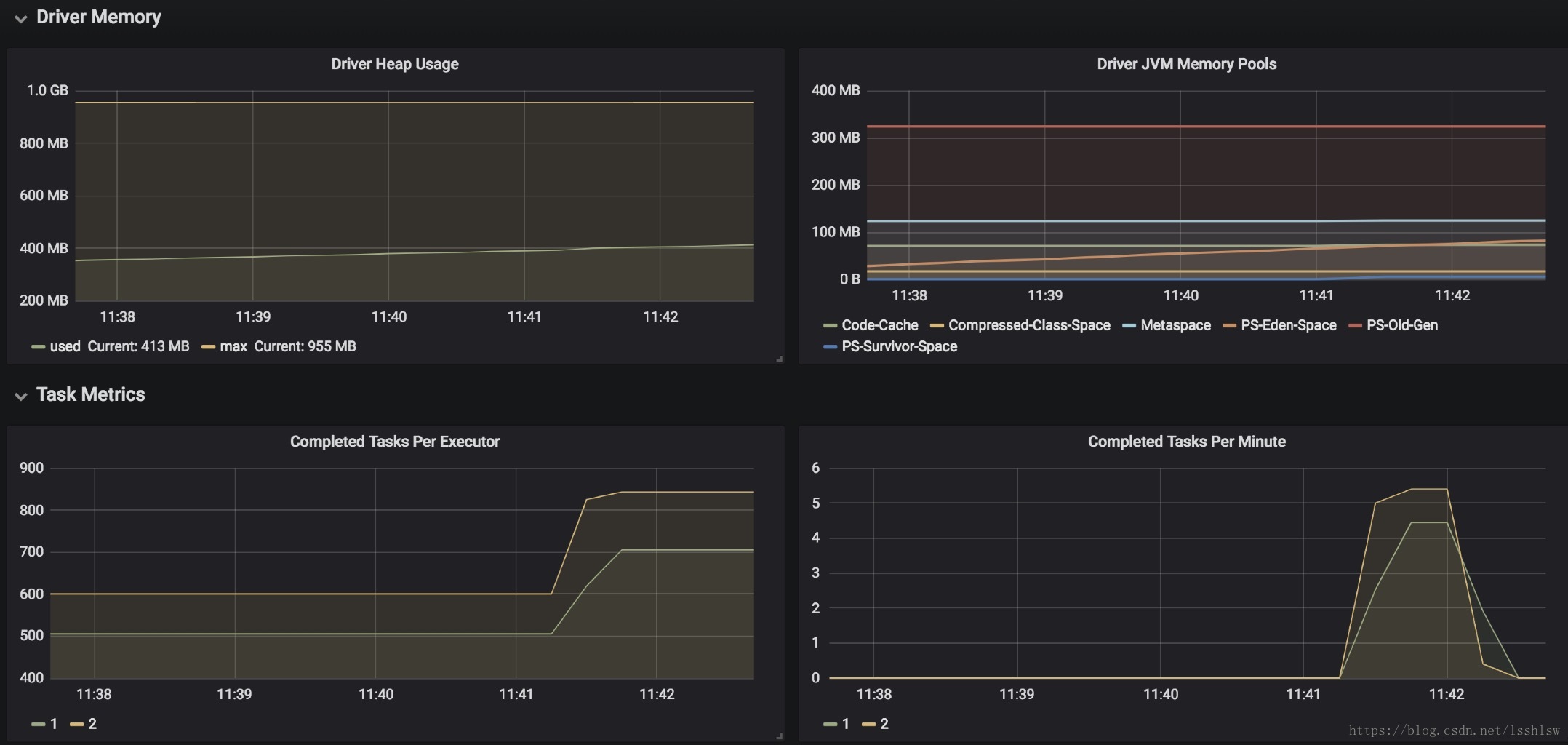
相关文件
graphite_exporter_mapping
mappings:
- match: '*.*.executor.filesystem.*.*'
name: filesystem_usage
labels:
application: $1
executor_id: $2
fs_type: $3
qty: $4
- match: '*.*.jvm.*.*'
name: jvm_memory_usage
labels:
application: $1
executor_id: $2
mem_type: $3
qty: $4
- match: '*.*.executor.jvmGCTime.count'
name: jvm_gcTime_count
labels:
application: $1
executor_id: $2
- match: '*.*.jvm.pools.*.*'
name: jvm_memory_pools
labels:
application: $1
executor_id: $2
mem_type: $3
qty: $4
- match: '*.*.executor.threadpool.*'
name: executor_tasks
labels:
application: $1
executor_id: $2
qty: $3
- match: '*.*.BlockManager.*.*'
name: block_manager
labels:
application: $1
executor_id: $2
type: $3
qty: $4
- match: DAGScheduler.*.*
name: DAG_scheduler
labels:
type: $1
qty: $2

















 1270
1270

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









