






1.原型
一、prototype
在JavaScript中,每个函数都有一个prototype属性,这个属性指向函数的原型对象。
函数的prototype指向了一个对象,而这个对象正是调用构造函数时创建的实例的原型,也就是person1和person2的原型。
函数的prototype指向了一个对象,而这个对象正是调用构造函数时创建的实例的原型,也就是person1和person2的原型。
每个对象都有 __proto__ 属性,但只有函数对象才有 prototype 属性二、__proto__
这是每个对象(除null外)都会有的属性,叫做__proto__,这个属性会指向该对象的原型。
function Person() { } var person = new Person(); console.log(person.__proto__ === Person.prototype); // true
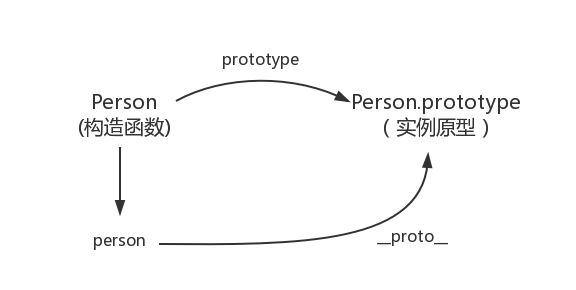
每个原型都有一个constructor属性,指向该关联的构造函数。
function Person() {
}
console.log(Person===Person.prototype.constructor) //true
- this指向
补充说明:
function Person() {
}
var person = new Person();
console.log(person.constructor === Person); // true
当获取 person.constructor 时,其实 person 中并没有 constructor 属性,当不能读取到constructor 属性时,会从 person 的原型也就是 Person.prototype 中读取,正好原型中有该属性,所以:
person.constructor === Person.prototype.constructor
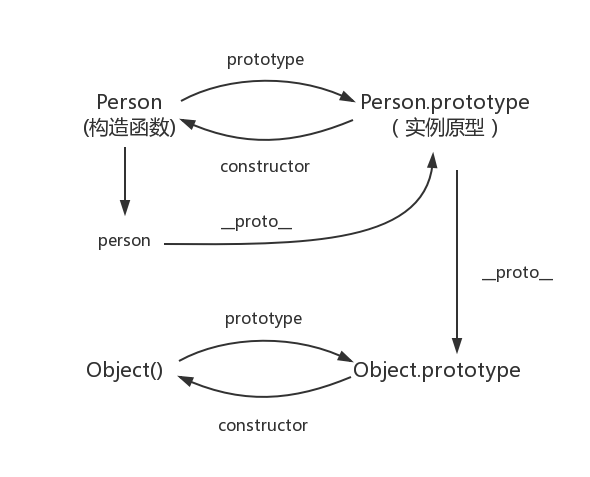
五、原型的原型
在前面,我们已经讲了原型也是一个对象,既然是对象,我们就可以用最原始的方式创建它,那就是:其实原型对象就是通过 Object 构造函数生成的,结合之前所讲,实例的 __proto__ 指向构造函数的 prototype
var obj = new Object(); obj.name = 'Kevin' console.log(obj.name) // Kevin
this指向:
this的指向在函数定义的时候是确定不了的,只有函数执行的时候才能确定this到底指向谁,实际上this的最终指向的是那个调用它的对象 【 this永远指向的是最后调用它的对象,也就是看它执行的时候是谁调用的】
哪个对象调用函数,函数里面的this指向哪个对象。
一、普通函数调用
情况1:如果一个函数中有this,但是它没有被上一级的对象所调用,那么this指向的就是window,这里需要说明的是在js的严格版中this指向的不是window,
这个情况没特殊意外,就是指向全局对象-window。
function a(){
var user = "追梦子";
console.log(this.user); //undefined
console.log(this); //Window
}
a();1、使用let
/*普通函数调用*/
let username = "程新松";
function fn(){
console.log(this.username); //undefined
}
fn();(1)let 允许把变量的作用域限制在块级域中;var 申明变量要么是全局的,要么是函数级的,而无法是块级的。
2)先let后var
let subClass = function(){
let name='程新松';
if(true){
var name='saucxs';
console.log(name);
}
console.log(name);
}
subClass();
Uncaught SyntaxError: Identifier 'name' has already been declared二、对象函数调用
哪个函数调用,this指向哪里
情况2:如果一个函数中有this,这个函数有被上一级的对象所调用,那么this指向的就是上一级的对象。
var name='程新松';
let obj={
id:201102304,
fn:function(){
console.log(this.name); //undefined
console.log(this.id); //201102304
}
}
obj.fn()
很明显,第一次就是输出 obj.name ,但是没有这个name属性,输出的结果undefined。而第二次输出obj.id,有这个id属性,输出 201102304,因为 this 指向 obj 情况3:如果一个函数中有this,这个函数中包含多层对象,尽管这个函数是被最外层的对象所调用,this指向的也只是它上一级的对象,
var o = {
a:10,
b:{
a:12,
fn:function(){
console.log(this.a); //12
}
}
}
o.b.fn();
var o = {
a:10,
b:{
fn:function(){
console.log(this.a); //undefined
}
}
}
o.b.fn();还有一种比较特殊的情况,例子4:
var o = {
a:10,
b:{
a:12,
fn:function(){
console.log(this.a); //undefined
console.log(this); //window
}
}
}
var j = o.b.fn;
j();
this永远指向的是最后调用它的对象,也就是看它执行的时候是谁调用的,
例子4中虽然函数fn是被对象b所引用,
但是在将fn赋值给变量j的时候并没有执行所以最终指向的是window三、构造函数调用(实例)
let structureClass=function(){
this.name='程新松';
}
let subClass1=new structureClass();
console.log(subClass1.name); //程新松
let subClass=new structureClass();
subClass.name='成才';
console.log(subClass.name); //成才
new关键字可以改变this的指向,将这个this指向对象subClass1,为什么我说subClass1是对象,
因为用了new关键字就是创建一个对象实例,用变量subClass1创建了一个Fn的实例
(相当于复制了一份Fn到对象a里面),new关键字就等同于复制了一份。。首先new关键字会创建
一个空的对象,然后会自动调用一个函数apply方法,将this指向这个空对象,这样的话函数内部
的this就会被这个空的对象替代。在构造函数里面返回一个对象,会直接返回这个对象,而不是执行构造函数后创建的对象。如果返回值不是一个对象那么this还是指向函数的实例。
在构造函数里面返回一个对象,会直接返回这个对象,而不是执行构造函数后创建的对象
复制代码
let structureClass=function(){
this.name='程新松';
return {
username:'saucxs'
}
}
let subClass1=new structureClass();
console.log(subClass1); // { username:'saucxs'}
console.log(subClass1.name); //undefinedfunction fn()
{
this.user = '追梦子';
return undefined;
}
var a = new fn;
console.log(a); //fn {user: "追梦子"}手写new
function Dog(name){
this.name = name
}
Dog.prototype.sayName = function(){
console.log(this.name)
}
//原来的new
}
var dog = new Dog('小狗')
dog.sayName()
//首先创建了一个新的空对象
//设置原型,将对象的原型设置为函数的prototype对象。
//让函数的this指向这个对象,执行构造函数的代码(为这个新对象添加属性)
//判断函数的返回值类型,如果是值类型,返回创建的对象。如果是引用类型,就返回这个引用类型的对象。
// 手写new
function _new(fn,...args){
//先用Object创建一个空的对象,
const obj = Object.create(fn.prototype) [设置原型,将对象的原型设置为函数的prototype对象。修改obj.__proto__=Dog.prototype]
//让函数的this指向这个对象,执行构造函数的代码(为这个新对象添加属性)
const rel = fn.apply(obj,args)
[ // 如果执行结果有返回值并且是一个对象, 返回执行的结果, 否则, 返回新创建的对象]
return rel instanceof Object ? rel : obj
}
var _newDog = _new(Dog,'这是用_new出来的小狗')
_newDog.sayName()对于为啥需要判断返回值得问题
function Person(firtName, lastName) {
this.firtName = firtName;
this.lastName = lastName;
return {
fullName: `${this.firtName} ${this.lastName}`
};
}
function _new(obj, ...rest){
const newObj = Object.create(obj.prototype);
const result = obj.apply(newObj, rest);
// const result = obj.call(newObj, ...rest);
return typeof result === 'object' ? result : newObj;
}
const tb2 = _new(Person, 'Chen', 'Tianbao');
console.log(tb2) //{fullName: "Chen Tianbao"}四、apply和call调用
apply和call简单来说就是会改变传入函数的this。
复制代码
/*apply和call调用*/
let obj1={
name:'程新松'
};
let obj2={
name:'saucxs',
fn:function(){
console.log(this.name);
}
}
obj2.fn.call(obj1); //程新松
此时虽然是 obj2 调用方法,但是使用 了 call ,动态的把 this 指向到 obj1 。
相当于这个 obj2.fn 这个执行环境是 obj1 。
call 和 apply 两个主要用途:
1.改变 this 的指向(把 this 从 obj2 指向到 obj1 )
2.方法借用( obj1 没有 fn ,只是借用 obj2 方法)var a = {
user:"追梦子",
fn:function(){
console.log(this.user);
}
}
var b = a.fn;
b(); //undefined
var a = {
user:"追梦子",
fn:function(){
console.log(this.user);
}
}
a.fn(); //追梦子
var a = {
user:"追梦子",
fn:function(){
console.log(this.user); //追梦子
}
}
var b = a.fn;
b.call(a);
通过在call方法,给第一个参数添加要把b添加到哪个环境中,简单来说,this就会指向那个对象。2、call与apply区别
//注意如果call和apply的第一个参数写的是null,那么this指向的是window对象
call 和 apply 的作用,完全一样,唯一的区别就是在参数上面。
call 接收的参数不固定,第一个参数是函数体内 this 的指向,第二个参数以下是依次传入的参数。
apply接收两个参数,第一个参数也是函数体内 this 的指向。第二个参数是一个集合对象(数组或者类数组)
let fn=function(a,b,c){
console.log(a,b,c);
}
let arrArray=[1,2,3];
fn.call(window,arrArray); //[1, 2, 3] undefined undefined
fn.apply(window,arrArray); // 1 2 3bind方法返回的是一个修改过后的函数。
var a = {
user:"追梦子",
fn:function(){
console.log(this.user);
}
}
var b = a.fn;
var c = b.bind(a);
console.log(c); //function() { [native code] }
c(); 追梦子此时才会打印
同样bind也可以有多个参数,并且参数可以执行的时候再次添加,但是要注意的是,参数是按照形参的顺序进行的。
var a = {
user:"追梦子",
fn:function(e,d,f){
console.log(this.user); //追梦子
console.log(e,d,f); //10 1 2
}
}
var b = a.fn;
var c = b.bind(a,10);
c(1,2);- bind:语法和call一模一样,区别在于立即执行还是等待执行,bind不兼容IE6~8
fn.call(obj, 1, 2); // 改变fn中的this,并且把fn立即执行
fn.bind(obj, 1, 2); // 改变fn中的this,fn并不执行总结:call和apply都是改变上下文中的this并立即执行这个函数,bind方法可以让对应的函数想什么时候调就什么时候调用,并且可以将参数在执行的时候添加,这是它们的区别,根据自己的实际情况来选择使用。
五、箭头函数调用
在箭头函数里面,没有 this ,箭头函数里面的 this 是继承外面的环境。如果有嵌套的情况,则this绑定到最近的一层对象上。
对象调用
var o = {
user:"追梦子",
fn:function(){
console.log(this.user); //追梦子
}
}
o.fn()
let obj={
name:'程新松',
fn:function(){
setTimeout(function(){console.log(this.name)})
}
}
obj.fn(); //undefined
fn() 里面的 this 是指向 obj ,但是,传给 setTimeout 的是普通函数,
this 指向是 window , window 下面没有 name ,所以这里输出 underfind 。
//换成箭头函数
let obj={
name:"程新松",
fn:function(){
setTimeout(()=>{console.log(this.name)});
}
}
obj.fn();
传给 setTimeout 的是箭头函数,然后箭头函数里面没有 this ,
所以要向上层作用域查找,在这个例子上, setTimeout 的上层作用域是
fn 。而 fn 里面的 this 指向 obj ,所以 setTimeout 里面的箭头函数的 this ,
指向 obj 。所以输出 程新松。
防抖节流
在进行窗口的resize、scroll,输入框内容校验等操作时,如果事件处理函数调用的频率无限制,会加重浏览器的负担,导致用户体验非常糟糕
函数防抖(debounce):触发高频事件后n秒内函数只会执行一次,如果n秒内高频事件再次被触发,则重新计算时间。
函数节流(throttle):高频事件触发,但在n秒内只会执行一次,所以节流会稀释函数的执行频率。
1、函数防抖(debounce)
- 实现方式:每次触发事件时设置一个延迟调用方法,并且取消之前的延时调用方法
- 缺点:如果事件在规定的时间间隔内被不断的触发,则调用方法会被不断的延迟
-
//防抖debounce代码: function debounce(fn,delay) { var timeout = null; // 创建一个标记用来存放定时器的返回值 return function (e) { // 每当用户输入的时候把前一个 setTimeout clear 掉 clearTimeout(timeout); // 然后又创建一个新的 setTimeout, 这样就能保证interval 间隔内如果时间持续触发,就不会执行 fn 函数 timeout = setTimeout(() => { fn.apply(this, arguments); }, delay); }; } // 处理函数 function handle() { console.log('防抖:', Math.random()); } //滚动事件 window.addEventListener('scroll', debounce(handle,500)); - 实现方式:每次触发事件时,如果当前有等待执行的延时函数,则直接return
-
//节流throttle代码: function throttle(fn,delay) { let canRun = true; // 通过闭包保存一个标记 return function () { // 在函数开头判断标记是否为true,不为true则return if (!canRun) return; // 立即设置为false canRun = false; // 将外部传入的函数的执行放在setTimeout中 setTimeout(() => { // 最后在setTimeout执行完毕后再把标记设置为true(关键)表示可以执行下一次循环了。 // 当定时器没有执行的时候标记永远是false,在开头被return掉 fn.apply(this, arguments); canRun = true; }, delay); }; } function sayHi(e) { console.log('节流:', e.target.innerWidth, e.target.innerHeight); } window.addEventListener('resize', throttle(sayHi,500));总结:
函数防抖:将多次操作合并为一次操作进行。原理是维护一个计时器,规定在delay时间后触发函数,但是在delay时间内再次触发的话,就会取消之前的计时器而重新设置。这样一来,只有最后一次操作能被触发。函数节流:使得一定时间内只触发一次函数。原理是通过判断是否有延迟调用函数未执行。
区别: 函数节流不管事件触发有多频繁,都会保证在规定时间内一定会执行一次真正的事件处理函数,而函数防抖只是在最后一次事件后才触发一次函数。 比如在页面的无限加载场景下,我们需要用户在滚动页面时,每隔一段时间发一次 Ajax 请求,而不是在用户停下滚动页面操作时才去请求数据。这样的场景,就适合用节流技术来实现。
闭包
闭包就是能够读取其他函数内部变量的函数。
由于在Javascript语言中,只有函数内部的子函数才能读取局部变量,因此可以把闭包简单理解成"定义在一个函数内部的函数"
所以,在本质上,闭包就是将函数内部和函数外部连接起来的一座桥梁
如何从外部读取局部变量
function f1(){
var n=999;
function f2(){
alert(n); // 999
}}
在上面的代码中,函数f2就被包括在函数f1内部,这时f1内部的所有局部变量,对f2都是可见的。但是反过来就不行,f2内部的局部变量,对f1就是不可见的。
既然f2可以读取f1中的局部变量,那么只要把f2作为返回值,我们不就可以在f1外部读取它的内部变量了吗!
function f1(){
var n=999;
function f2(){
alert(n);
}return f2;
}
var result=f1();
result(); // 999
四、闭包的用途
闭包可以用在许多地方。它的最大用处有两个,一个是前面提到的可以读取函数内部的变量,另一个就是让这些变量的值始终保持在内存中。
怎么来理解这句话呢?请看下面的代码。
function f1(){
var n=999;
nAdd=function(){n+=1}
function f2(){
alert(n);
}return f2;
}
var result=f1();
result(); // 999
nAdd();
result(); // 1000
在这段代码中,result实际上就是闭包f2函数。它一共运行了两次,第一次的值是999,第二次的值是1000。这证明了,函数f1中的局部变量n一直保存在内存中,并没有在f1调用后被自动清除。
为什么会这样呢?原因就在于f1是f2的父函数,而f2被赋给了一个全局变量,这导致f2始终在内存中,而f2的存在依赖于f1,因此f1也始终在内存中,不会在调用结束后,被垃圾回收机制(garbage collection)回收。
这段代码中另一个值得注意的地方,就是"nAdd=function(){n+=1}"这一行,首先在nAdd前面没有使用var关键字,因此nAdd是一个全局变量,而不是局部变量。其次,nAdd的值是一个匿名函数(anonymous function),而这个匿名函数本身也是一个闭包,所以nAdd相当于是一个setter,可以在函数外部对函数内部的局部变量进行操作。
五、使用闭包的注意点
1)由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在IE中可能导致内存泄露。解决方法是,在退出函数之前,将不使用的局部变量全部删除。
2)闭包会在父函数外部,改变父函数内部变量的值。所以,如果你把父函数当作对象(object)使用,把闭包当作它的公用方法(Public Method),把内部变量当作它的私有属性(private value),这时一定要小心,不要随便改变父函数内部变量的值。
六、思考题
如果你能理解下面两段代码的运行结果,应该就算理解闭包的运行机制了。
代码片段一。
var name = "The Window";
var object = {
name : "My Object",getNameFunc : function(){
return function(){
return this.name;
};}
};
alert(object.getNameFunc()());
代码片段二。
var name = "The Window";
var object = {
name : "My Object",getNameFunc : function(){
var that = this;
return function(){
return that.name;
};}
};
alert(object.getNameFunc()());
JS垃圾回收机制
概念:一般来说没有被引用的对象就是垃圾,就是要被清除, 有个例外如果几个对象引用形成一个环,互相引用,但根访问不到它们,这几个对象也是垃圾,也要被清除。
原理:
JavaScript中会被判定为垃圾的情形如下:
- 对象不再被引用;
- 对象不能从根上访问到;
垃圾回收方法:
1.标记清除:
核心思想:分标记和清除两个阶段完成。
- 遍历所有对象找标记活动对象;
- 遍历所有对象清除没有标记对象;
- 回收相应的空间。
谷歌浏览器:“查找引用”,浏览器不定时去查找当前内存的引用,如果没有被占用了,浏览器会回收它;如果被占用,就不能回收。
IE浏览器:“引用计数法”,当前内存被占用一次,计数累加1次,移除占用就减1,减到0时,浏览器就回收它
EventLoop 事件循环
JS是单线程的,为了防止一个函数执行时间过长阻塞后面的代码,所以会先将同步代码压入执行栈中,依次执行,将异步代码推入异步队列,异步队列又分为宏任务队列和微任务队列,因为宏任务队列的执行时间较长,所以微任务队列要优先于宏任务队列。微任务队列的代表就是,Promise、MutaionObserver、process.nextTick(Node.js 环境),宏任务的话就是script( 整体代码)、setTimeout、setInterval、I/O、UI 交互事件、setImmediate(Node.js 环境)
当主程结束,先执行准备好微任务,然后再执行准备好的宏任务,一个轮询结束。
浏览器中的事件环(Event Loop)
事件环的运行机制是,先会执行栈中的内容,栈中的内容执行后执行微任务,微任务清空后再执行宏任务,先取出一个宏任务,再去执行微任务,然后在取宏任务清微任务这样不停的循环。
-
eventLoop 是由JS的宿主环境(浏览器)来实现的;
-
事件循环可以简单的描述为以下四个步骤:
- 函数入栈,当Stack中执行到异步任务的时候,就将他丢给WebAPIs,接着执行同步任务,直到Stack为空;
- 此期间WebAPIs完成这个事件,把回调函数放入队列中等待执行(微任务放到微任务队列,宏任务放到宏任务队列)
- 执行栈为空时,Event Loop把微任务队列执行清空;
- 微任务队列清空后,进入宏任务队列,取队列的第一项任务放入Stack(栈)中执行,执行完成后,查看微任务队列是否有任务,有的话,清空微任务队列。重复4,继续从宏任务中取任务执行,执行完成之后,继续清空微任务,如此反复循环,直至清空所有的任务。

-
浏览器中的任务源(task):
宏任务(macrotask):
宿主环境提供的,比如浏览器
ajax、setTimeout、setInterval、setTmmediate(只兼容ie)、script、requestAnimationFrame、messageChannel、UI渲染、一些浏览器api微任务(microtask):
语言本身提供的,比如promise.then
then、queueMicrotask(基于then)、mutationObserver(浏览器提供)、messageChannel 、mutationObersve
总结:【js是单线程的,将同步任务放在主线程立即执行,将异步任务挂起放在异步队列中,将宿主提供的方法settimeout 为宏任务,语言本身提供的promise.then为微任务,执行完同步代码,就执行微任务,然后执行宏任务】
console.log('script start');
setTimeout(function() {
console.log('timeout1');
}, 10);
new Promise(resolve => {
console.log('promise1');
resolve();
setTimeout(() => console.log('timeout2'), 10);
}).then(function() {
console.log('then1')
})
console.log('script end');
// script start promise1 script end 'then1' timeout1 timeout2
首先遇到了console.log,输出 script start; 接着往下走,遇到 setTimeout 任务源,将其分发到任务队列中去,记为 timeout1; 接着遇到 promise,new promise 中的代码立即执行,输出 promise1, 然后执行 resolve ,遇到 setTimeout ,将其分发到任务队列中去,记为 timemout2, 将其 then 分发到微任务队列中去,记为 then1; 接着遇到 console.log 代码,直接输出 script end 接着检查微任务队列,发现有个 then1 微任务,执行,输出then1 再检查微任务队列,发现已经清空,则开始检查宏任务队列,执行 timeout1,输出 timeout1; 接着执行 timeout2,输出 timeout2 至此,所有的都队列都已清空,执行完毕。其输出的顺序依次是:script start, promise1, script end, then1, timeout1, timeout2setTimeout、Promise、Async/Await 的区别
-
setTimeout
settimeout的回调函数放到宏任务队列里,等到执行栈清空以后执行。
-
Promise
Promise本身是同步的立即执行函数, 当在executor中执行resolve或者reject的时候, 此时是异步操作, 会先执行then/catch等,当主栈完成后,才会去调用resolve/reject中存放的方法执行。
-
async/await
-
函数前面多了一个aync关键字。await关键字只能用在aync定义的函数内,async 函数返回一个 Promise 对象,,该promise的reosolve值就是函数return的值。可以很好地处理 then 链。当函数执行的时候,一旦遇到 await 就会先返回,等到触发的异步操作完成,再执行函数体内后面的语句。可以理解为,是让出了线程,跳出了 async 函数体。
async/await以及js中的微任务和宏任务
区别:
1)例如
async function async1() {
console.log('async1 start')
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2')
}
console.log('script start')
setTimeout(function() {
console.log('setTimeout')
}, 0)
async1();
new Promise( function( resolve ) {
console.log('promise1')
resolve();
} ).then( function() {
console.log('promise2')
} )
console.log('script end')
// async1 start => async2 => promise1 => script end =>
promise2 => async1 end => setTimeout数组遍历方法
1.for循环
使用临时变量,将长度缓存起来,避免重复获取数组长度,当数组较大时优化效果才会比较明显。
for(j = 0,len=arr.length; j < len; j++) {
}2.foreach循环
遍历数组中的每一项,没有返回值,对原数组没有影响,不支持IE
//1 没有返回值
arr.forEach((item,index,array)=>{
//执行代码
})
//参数:value数组中的当前项, index当前项的索引, array原始数组;
//数组中有几项,那么传递进去的匿名回调函数就需要执行几次;3.map循环
有返回值,可以return出来
map的回调函数中支持return返回值;return的是啥,相当于把数组中的这一项变为啥
(并不影响原来的数组,只是相当于把原数组克隆一份,把克隆的这一份的数组中的对应项改变了);
arr.map(function(value,index,array){
//do something
return XXX
})
var ary = [12,23,24,42,1];
var res = ary.map(function (item,index,ary ) {
return item*10;
})
console.log(res);//-->[120,230,240,420,10]; 原数组拷贝了一份,并进行了修改
console.log(ary);//-->[12,23,24,42,1]; 原数组并未发生变化4.forof遍历
可以正确响应break、continue和return语句
可以正确响应break、continue和return语句
for (var value of myArray) {
console.log(value);
}5.filter遍历
不会改变原始数组,返回新数组
var arr = [73,84,56, 22,100]
var newArr = arr.filter(item => item>80) //得到新数组 [84, 100]
console.log(newArr,arr)6.every遍历
every()是对数组中的每一项运行给定函数,如果该函数对每一项返回true,则返回true。
var arr = [ 1, 2, 3, 4, 5, 6 ];
console.log( arr.every( function( item, index, array ){
return item > 3;
}));
false7.some遍历
some()是对数组中每一项运行指定函数,如果该函数对任一项返回true,则返回true。
var arr = [ 1, 2, 3, 4, 5, 6 ];
console.log( arr.some( function( item, index, array ){
return item > 3;
}));
true8.reduce
reduce() 方法接收一个函数作为累加器(accumulator),数组中的每个值(从左到右)开始缩减,最终为一个值。
reduce接受一个函数,函数有四个参数,分别是:上一次的值,当前值,当前值的索引,数组
reduce还有第二个参数,我们可以把这个参数作为第一次调用callback时的第一个参数,上面这个例子因为没有第二个参数,所以直接从数组的第二项开始,如果我们给了第二个参数为5,那么结果就是这样的:
var total = [0,1,2,3,4].reduce((a, b)=>a + b); //109.reduceRight
reduceRight()方法的功能和reduce()功能是一样的,不同的是reduceRight()从数组的末尾向前将数组中的数组项做累加。
10.find
find()方法返回数组中符合测试函数条件的第一个元素。否则返回undefined
var stu = [
{
name: '张三',
gender: '男',
age: 20
},
{
name: '王小毛',
gender: '男',
age: 20
},
{
name: '李四',
gender: '男',
age: 20
}
]
stu.find((element) => (element.name == '李四'))
//返回结果为
//{name: "李四", gender: "男", age: 20}11.findIndex
对于数组中的每个元素,findIndex 方法都会调用一次回调函数(采用升序索引顺序),直到有元素返回 true。只要有一个元素返回 true,findIndex 立即返回该返回 true 的元素的索引值。如果数组中没有任何元素返回 true,则 findIndex 返回 -1
12.keys,values,entries
ES6 提供三个新的方法 —— entries(),keys()和values() —— 用于遍历数组。它们都返回一个遍历器对象,可以用for...of循环进行遍历,唯一的区别是keys()是对键名的遍历、values()是对键值的遍历,entries()是对键值对的遍历
for (let index of ['a', 'b'].keys()) {
console.log(index);
}
// 0
// 1
for (let elem of ['a', 'b'].values()) {
console.log(elem);
}
// 'a'
// 'b'
for (let [index, elem] of ['a', 'b'].entries()) {
console.log(index, elem);
}
// 0 "a"
// 1 "b"面试之前端安全问题,网络攻击XSS与CSRF
XSS(Cross Site Scripting)
XSS攻击全称跨站脚本攻击,之所以首字母是X,是为了区别于层叠样式表CSS
使用cookie,localStorage,sessionStorage时要注意是否有代码存在XSS注入的风险,攻击者在有XSS缺陷的页面会窃取用户的对应信息
事件委托
事件委托也称之为事件代理(Event Delegation)就是利用事件冒泡,“事件代理”即是把原本需要绑定在子元素的响应事件委托给父元素,让父元素担当事件监听的职务。使用事件代理的好处是可以提高性能。
用addEventListener(type,listener,useCapture)实现
- type: 必须,String类型,事件类型
- listener: 必须,函数体或者JS方法
- useCapture: 可选,boolean类型。指定事件是否发生在捕获阶段。默认为false,事件发生在冒泡阶段
事件委托的优点:
- 提高性能:每一个函数都会占用内存空间,只需添加一个事件处理程序代理所有事件,所占用的内存空间更少。
- 动态监听:使用事件委托可以自动绑定动态添加的元素,即新增的节点不需要主动添加也可以一样具有和其他元素一样的事件。
例子解析:
<script>
window.onload = function(){
let div = document.getElementById('div');
div.addEventListener('click',function(e){
console.log(e.target)
})
let div3 = document.createElement('div');
div3.setAttribute('class','div3')
div3.innerHTML = 'div3';
div.appendChild(div3)
}
</script>
<body>
<div id="div">
<div class="div1">div1</div>
<div class="div2">div2</div>
</div>
</body>
虽然没有给div1和div2添加点击事件,但是无论是点击div1还是div2,都会打印当前节点。因为其父级绑定了点击事件,点击div1后冒泡上去的时候,执行父级的事件。
分别点击div1、div2、div3
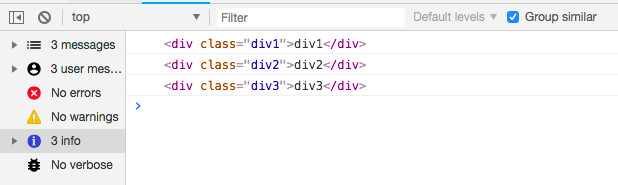
这样无论后代新增了多少个节点,一样具有这个点击事件的功能。这一个就是考察者想要听到的答案。
由一个案例来引出:
现在有一个需求:点击li添加背景颜色,并排他,点哪个哪个有背景颜色
<ul>
<li class="selected">1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
<li>6</li>
<li>7</li>
<li>8</li>
</ul>
*{
margin: 0;
padding: 0;
}
ul{
list-style: none;
width: 400px;
border: 1px solid #000;
margin: 100px auto;
}
li{
width: 100%;
height: 50px;
border-bottom: 1px solid #000;
box-sizing: border-box;
}
.selected{
background-color: red;
}
先来看一般做法,缺点是保存了多份onclick的函数
let oItems = document.querySelectorAll('li');
let currentItem = oItems[0];
for (let item of oItems){
// item.onclick = change;
item.onclick = function () {
currentItem.className = '';
this.className = 'selected';
currentItem = this;
}
}
事件委托的做法:监听ul的点击,而不是直接监听li的点击,li将事件冒泡到它的父元素ul,再通过事件对象拿到当前被点击的元素
let oUl = document.querySelector('ul');
let oLi = document.querySelector('.selected');
oUl.onclick = function (event) {
event = event || window.event;//兼容所有浏览器
oLi.className = '';
let item = event.target;//event.target为当前点击的li
item.className = 'selected';
oLi = item;
}最后一种事件委托做法利用的是事件冒泡
事件委托的好处:
1.减少事件数量,提高性能
2.预测未来元素,新添加的元素仍然可以触发该事件
3.避免内存外泄,在低版本的IE中,防止删除元素而没有移除事件而造成的内存溢出
事件捕获和事件冒泡机制:
一个事件触发后,会在子元素和父元素之间传播(propagation)。这种传播分成三个阶段。
(1)捕获阶段:从window对象传导到目标节点(上层传到底层)称为“捕获阶段”(capture phase),所有经过的节点,都会触发对应的事件;
(2)目标阶段:在目标节点上触发,称为“目标阶段”
(3)冒泡阶段:从目标节点传导回window对象(从底层传回上层),称为“冒泡阶段”(bubbling phase)。所有经过的节点,都会触发对应的事件。事件代理即是利用事件冒泡的机制把里层所需要响应的事件绑定到外层。
-
通过例子理解两个事件机制:
例子:假设有body和body节点下的div1均有绑定了一个注册事件.
效果:
当为事件捕获(useCapture:true)时,先执行body的事件,再执行div的事件
当为事件冒泡(useCapture:false)时,先执行div的事件,再执行body的事件//当useCapture为默认false时,为事件冒泡 <body> <div id="div1"></div> </body> window.onload = function(){ let body = document.querySelector('body'); let div1 = document.getElementById('div1'); body.addEventListener('click',function(){ console.log('打印body') }) div1.addEventListener('click',function(){ console.log('打印div1') }) } //结果:打印div1 打印body//当useCapture为true时,为事件捕获 <body> <div id="div1"></div> </body> window.onload = function(){ let body = document.querySelector('body'); let div1 = document.getElementById('div1'); body.addEventListener('click',function(){ console.log('打印body') },true) div1.addEventListener('click',function(){ console.log('打印div1') }) } //结果:打印body 打印div1阻止默认动作?(e.preventDefault(),return false;)
有一些html元素默认的行为,比如说a标签,点击后有跳转动作;form表单中的submit类型的input有一个默认提交跳转事件;reset类型的input有重置表单行为。
如果你想阻止这些浏览器默认行为,JavaScript为你提供了方法。
如下代码:
var $a = document.getElementsByTagName("a")[0];
$a.onclick = function(e){
alert("跳转动作被我阻止了")
e.preventDefault();
//return false;//也可以
}
默认事件没有了。既然return false 和 e.preventDefault()都是一样的效果,那它们有区别吗?当然有。
仅仅是在HTML事件属性 和 DOM0级事件处理方法中,才能通过返回 return false 的形式组织事件宿主的默认行为。阻止冒泡事件(e.stopPropagation())
function stopBubble(e){
if(e&&e.stopPropagation){//非IE
e.stopPropagation();
}
else{//IE
window.event.cancelBubble=true;
}
}














 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









