









在介绍Good-Turning Smoothing之前,我们可以先看一个有趣的例子:
假设你在钓鱼,已经抓到了18只鱼:
10条鲤鱼,3条黑鱼,2条刀鱼,1条鲨鱼,1条草鱼,1条鳗鱼…
Q1:下一个钓到的鱼是鲨鱼的概率是多少?
Q2:下一条鱼是新鱼种(之前没有出现过)的概率是多少?
Q3:既然如此,重新想一下,下一条抓到鱼为鲨鱼的概率是多少?
我们在看到Q1时,可以很简单的算出Q1结果为 1/18.
但是到了Q2,此时概率是无法计算的,所以我们便可以在此引出Good-Turning。在Good-Turning方法论中,我们会假设未出现过的鱼种的概率与出现一次的鱼种的概率相同,即N_0 = N_1 (N_k表示出现k次的元素的总数),在上面的例子中N_10=1,N_3=1,N_2=1,N_1=3。
然后我们回到Q2,此时Q2的结果也为3/18,即1/6。
然后我们继续看Q3,因为没有出现的鱼种出现的概率有1/6,所以Q1的结果,应该小于1/18。
在Good-Turning方法论中,当我们要求一个元素c出现的概率时,会先计算:
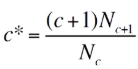
然后再通过原本的概率算出新的概率,即P(鲨鱼)=(1+1) * 1/3 * (1/18) = 1/27

接下来可以拿实际使用的场景距离,再次进行推导:
假如我们有一个长度我c的词库,每次从中抽出1个次,由训练集放入验证集中,循环c次获得了c个训练数据。

在Q1中,因为只有出现1次的单词,从训练数据集中拿出后,就不会再出现了,所以Q1的结果为 N_1/C。
同理,我们需要单词在训练集中出现K次,则拿过来的单词原本应该出现K+1次,所以Q2的结果应该是N_(K+1)(K+1)/C。
再继续,假如此时我们只需要求得其中1个单词出现K次的概率,则再Q2中,分母上乘以一个N_k就可以了,即N_(K+1)(K+1)/(CN_k)。
我们在拉普拉斯平滑中,知道平滑向是: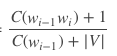
但是此时的1,是一个频次,然后我们上面算出来的是一个概率,要将概率转换为频次,即乘以一个C(词库大小)就可以了,即N_(K+1)(K+1)/*N_k,与前面得到的结果一致
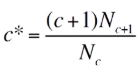
下面是一个实际的词频统计的例子:
第一列是单词出现次数,第二列是出现r次的单词的数量,第三列是我们的期望概率
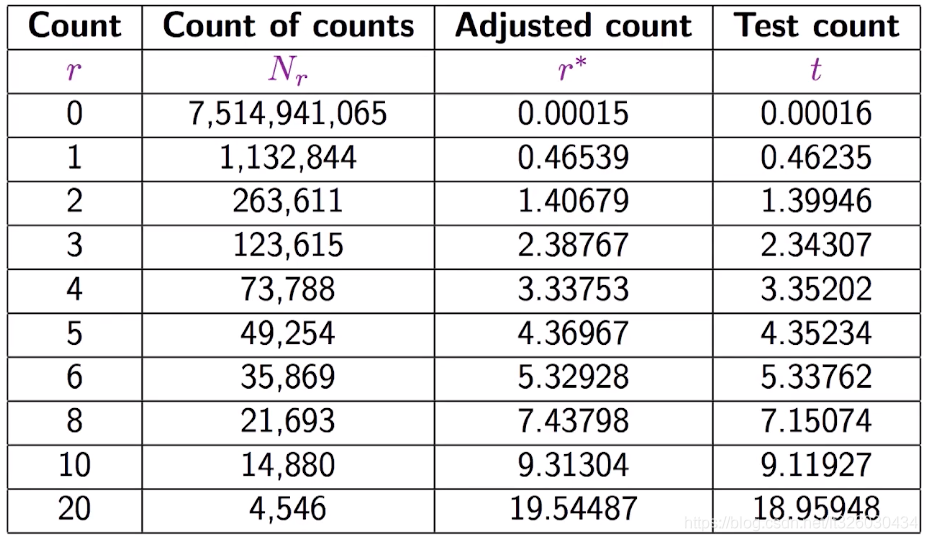
其中,第三列的期望概率就是通过上述结论计算出来的,例如:
P(1) = (1+1)*263611/1132844 = 0.46539
P(2) = (2+1)*123615/263611 = 1.40679
最后讲一下这个方法论的缺点:
从上图中也可以看出,当单词出现次数慢慢增大时,r值并不是连续性的,但是每一个P®的计算都依赖于r+1的count值。
简单的解决方案是,我们可以通过线性回归之类的方法,平滑的推断出7、9等不存在的r值的对应的count值,然后再带入上式进行计算。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









