







强化学习最主要的两种方式的融合,actor-critic的究竟是怎么回事?此处笔记根据B站课程,王树森老师的强化学习记录而来。4.深度强化学习(4_5):Actor-Critic Methods(Av374239425,P4)_哔哩哔哩_bilibili
1.Actor-critic Methods:同时训练策略网络和价值网络
| Actor | 动作学习网络,看作是一个运动员,不断地做出动作,根据裁判的打分逐渐做出高分动作。 |
| Critic | 价值学习网络,看作是一个裁判,不断的对agent的动作打分,从刚开始的随机打分,到后面的打分越来越精准。 |
 已知VΠ是QΠ的期望,其中Π是策略,QΠ评价动作价值。这两个部分都是不知道的,采用两个神经网络来学习。
已知VΠ是QΠ的期望,其中Π是策略,QΠ评价动作价值。这两个部分都是不知道的,采用两个神经网络来学习。
| Policy Network(actor) | 近似Π(a|s;θ)函数,其中θ是要学习的参数,该网络学习如何做动作。 |
| Value Network(critic) | 近似q(s,a;w)函数,其中w是要学习的参数,该网络学习给action打分,什么是好的action。 |
Actor:输入是状态s,输出是actions的概率分布。
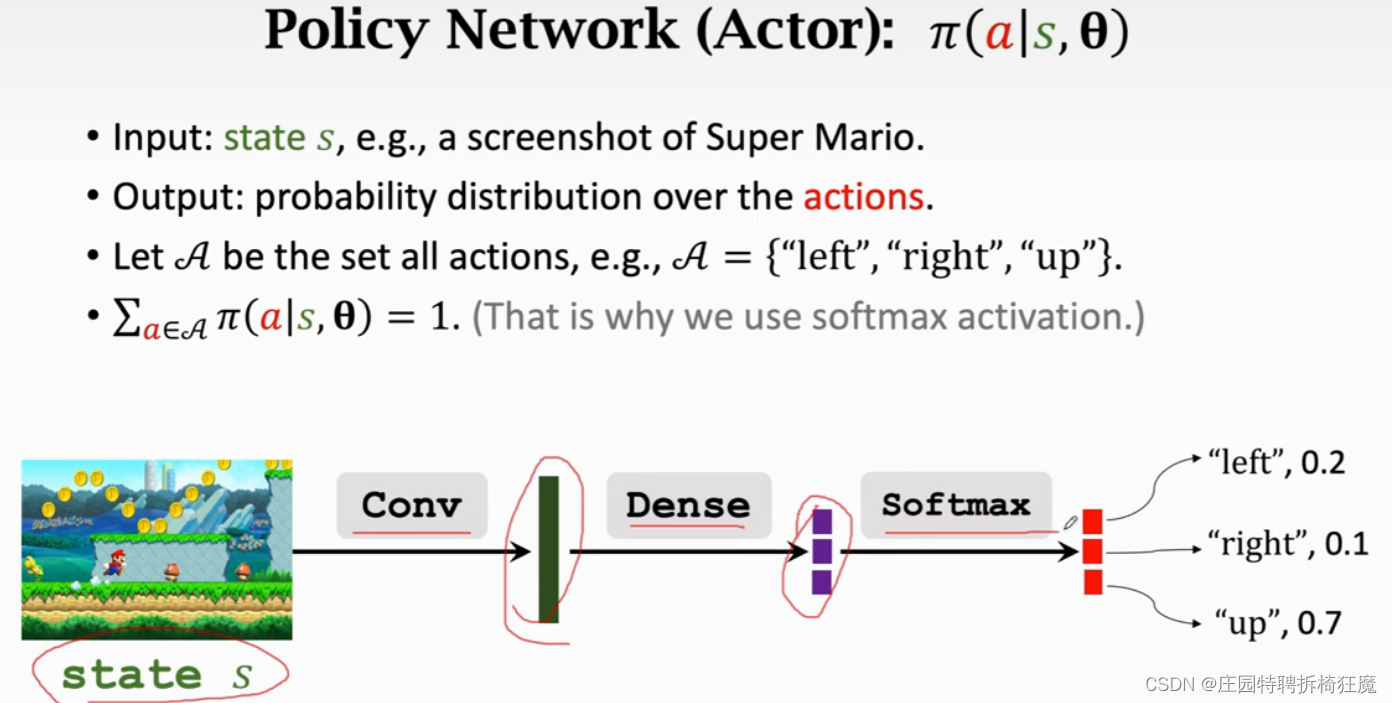
critic:输入是状态s和动作action,输出是当前状态s下,对action a 的打分,是一个数。
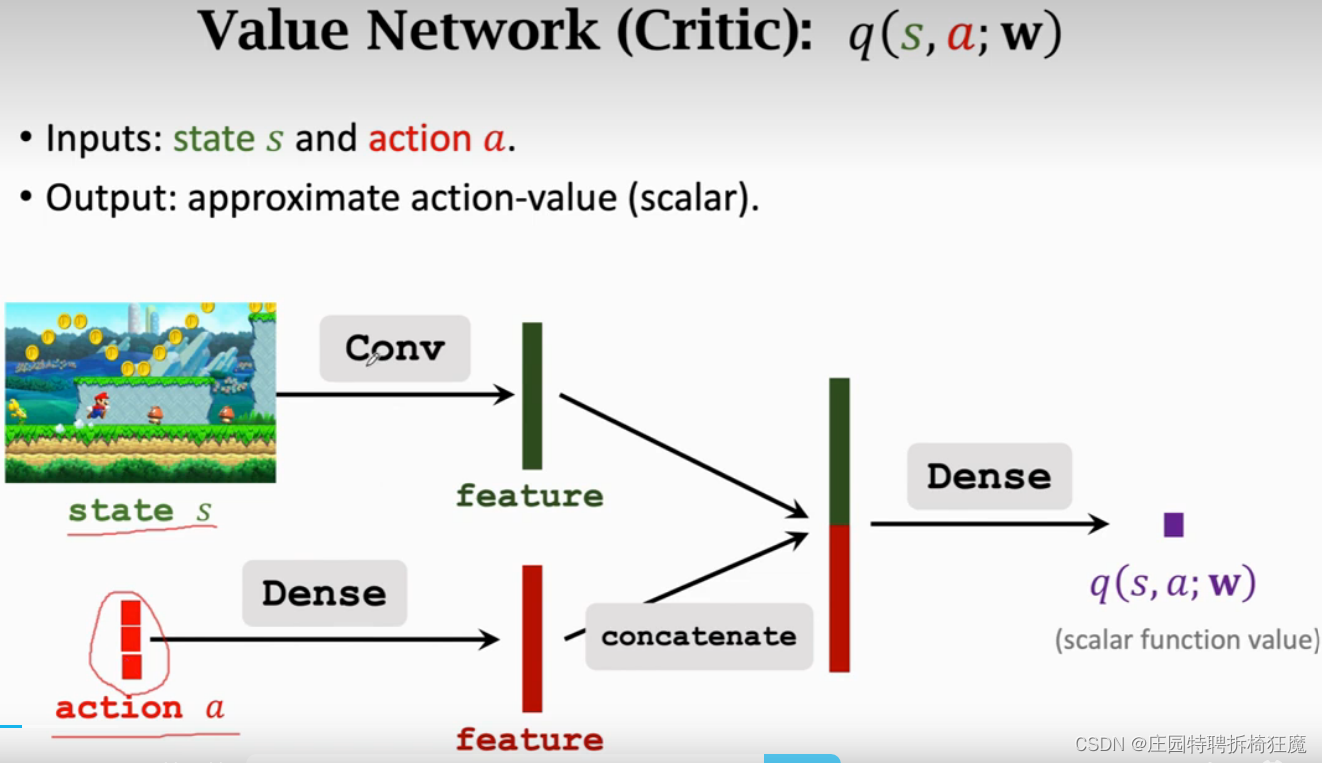
policy network控制agent的运动,value network评价agent动作的好坏。
2.Train the Net

Model V(s;θ,w),其中θ是策略网络的参数,w是价值网络的参数,这两个参数的更新目标不同:
| θ-策略网络 | θ更新的目的是使V(s;θ,w)的平均值更高,即做出得分高的动作。 |
| w-价值网络 | w更新的目的是更好的估计return,使给出的得分更加精准,靠environment的reward进行更新,使裁判打分更精准。 |
5个步骤更新net:

3.网络参数的更新
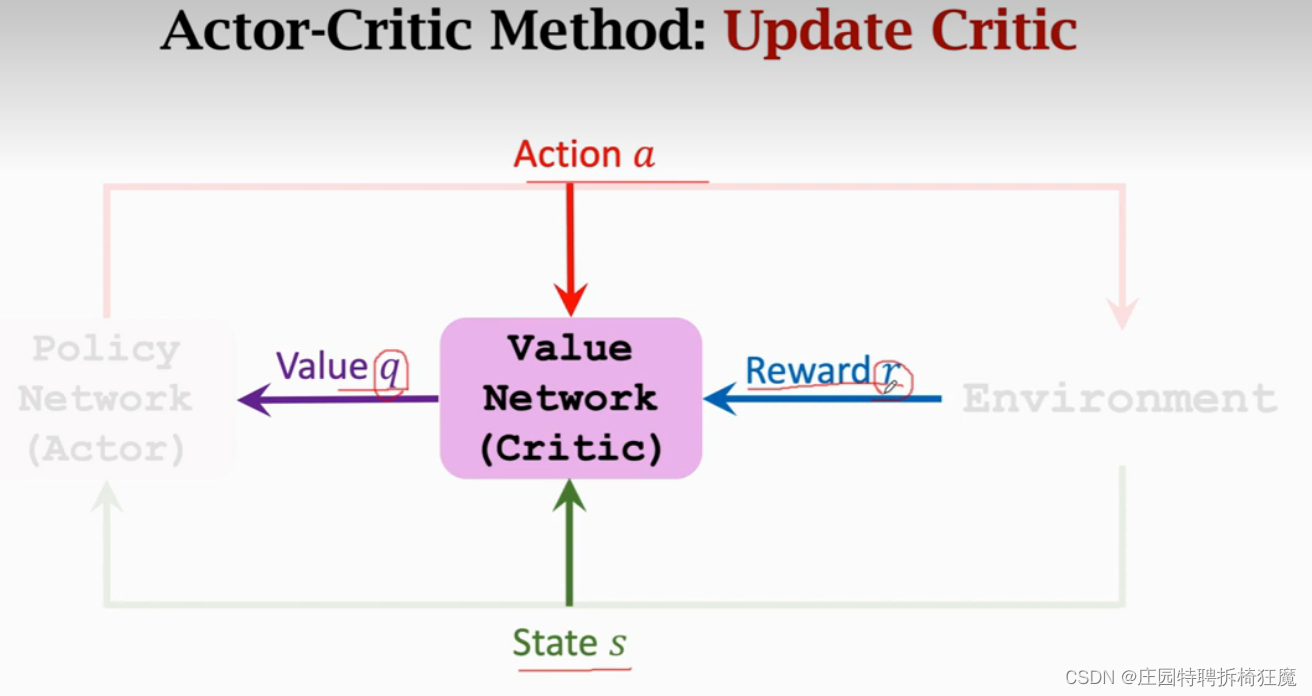
Value Network 价值网络参数更新:TD算法
已知策略转移函数q 对agent的action a(t)的打分,继续对a(t+1)打分,从而计算TD target。y(t)=奖励+系数*q对a(t+1)的打分。y(t)和q都是估计值,但是y(t)中包含部分真实的奖励,所以y(t)比q更真实。将y(t)看作使ground truth, 则loss定义为q和y(t)的平方差。使用梯度下降更新模型,使loss减小,使q逐渐接近y(t)。
通过对价值网络的更新,能够使得打分越来越精准。

Policy Network 策略网络参数更新:策略梯度
策略梯度是V对θ的导数,V对θ的导数是蒙特卡洛近似。其中g(a,θ)使无偏估计,a是根据Π(.|s(t);θ(t))随机抽样得来的,随机抽样保证了无偏性。
策略网络的训练目的是使agent的动作越来越好,agent本身不知道什么样的动作是好的,所以引入一个裁判价值网络作为监督信号,agent迎合裁判的喜好,做出得分高的动作。
但是要得到一个好的agent的动作训练,裁判需要打足够精准的分,来使agent提升自己,如何得到一个好的裁判,这里使用一个上帝打分reward,来限制裁判,使其打分更加精准。

4.整个网络的流程:

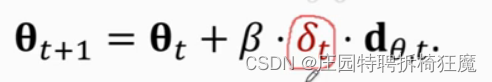
第9步的公式中的q(t)在有些论文中使用的是第五步的δ(t),q(t)是原始的公式,δ(t)是引入baseline的改进。使用q(t)还是δ(t),其期望是没有变的,所有两者的推到都是对的。
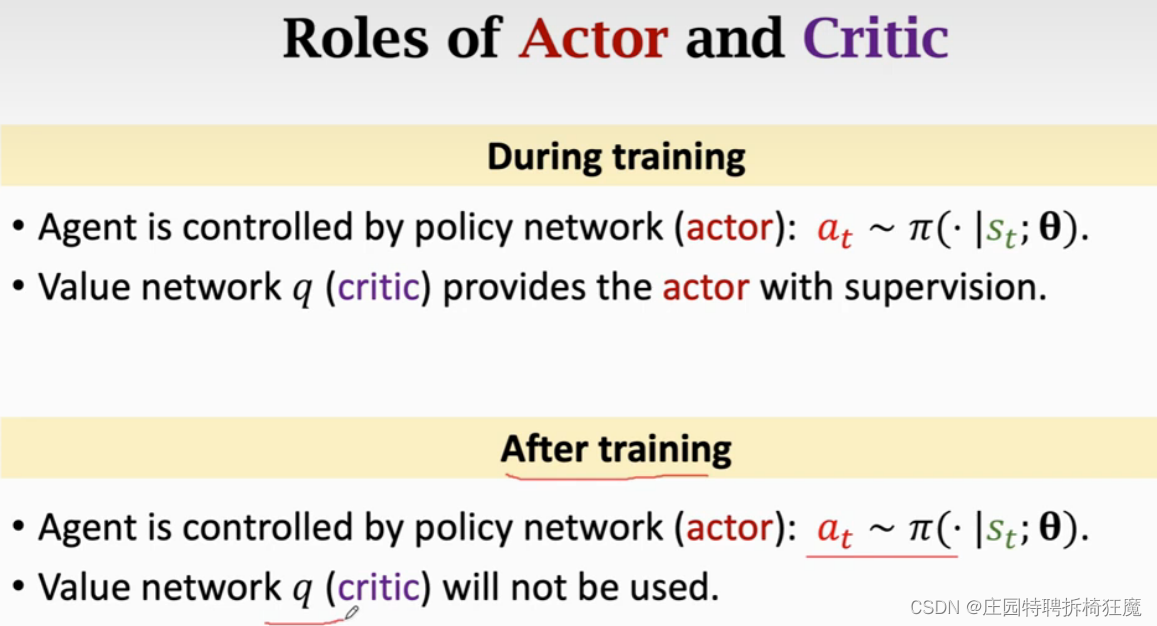
Summary:

















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









