







不仅仅是一道题,之后的某一天,它可能是破局的关键。
关于HashMap的知识点有哪些呢?分层次展示
1.基础知识:
存储键值对结构、底层数据结构、红黑树和链表
2.位运算与实现
位运算、put、get方法的实现
3.关于锁
segment锁和桶锁、线程不安全和HashTable、ConcurrentHashMap
1.关于HashMap的底层实现
HashMap的存储逻辑
HashMap的数据结构构成:数组+链表+红黑树(红黑树是jdk1.8才引入的)
JDK1.7 使用了数组+链表的方式
JDK1.8 使用了数组+链表+红黑树的方式
JDK8中HashMap引入了红黑树,同时在ConcurrentHashMap中做了相应优化。
ConcurrentHashMap是jdk1.5引入的

图摘自《HashMap的实现原理,源码深度剖析! – mikechen》
数组:transient Node<K,V>[] table 哈希桶数组
其元素类型是Node,Node是HashMap的内部类,实现了Map.Entry接口(本质是键值映射)
数组结构是Hash Table哈希表|散列表,根据key查找value : value=table[hash(key)]
数组长度总是2的n次方
核心问题:Hash冲突,Key不相同,但hash(Key)的值相同
Hash冲突的解决方法有: 地址法、链地址法,此处采用链地址法
就是在table数组本该放置元素的位置放置一个链表,把冲突的值链接在链表上,当链表过长时,将其转换为红黑树
链表转红黑树: static final int TREEIFY_THRESHOLD=8; 链表长度达到8时,转换为红黑树
红黑树转链表: static final int UNTREEIFY_THRESHOLD=6; 红黑树节点数减少到6个时,红黑树转换为链表

图摘自《HashMap和ConcurrentHashMap的区别,详解HashMap和ConcurrentHashMap数据结构-CSDN博客》
2.HashMap实现逻辑
(1).Hash函数的使用:
/** 计算key.hashCode()并将哈希值的高位数扩展(XORs)到低位数。 因为这个表使用了2的幂掩码, 在当前掩码之上只变化几比特的哈希集总是会发生冲突。 (在已知的例子中,有一组浮点键在小表中保存连续整数。)因此,我们应用一个变换,将高比特的影响向下扩散。 比特传播的速度、效用和质量之间存在权衡。 因为许多常见的哈希集已经被合理地分布(所以不会从传播中受益), 因为我们用Tree来处理箱子bins里的大量碰撞, 我们只是用最便宜的方式对一些移位的位进行异或,以减少系统损失, 以及考虑最高位的影响,否则由于表边界的原因,索引计算中永远不会使用最高位 */ static final int hash(Object key){ int h, return (key==null)?0:(h=key.hashCode())^(h>>>16); }key.hashCode() Object hashCode() 方法用于获取对象的 hash 值。——>一个32位的int值
h^(h>>16) 计算key.hashCode()并将哈希值的高位数扩展(XORs)到低位数。且高位信息被保留在了低位信息中。 ——以代价更小的方式,减少碰撞。
异或: 0^0=0 1^1=0 1^0=1 0^1=1
>>: 无符号右移
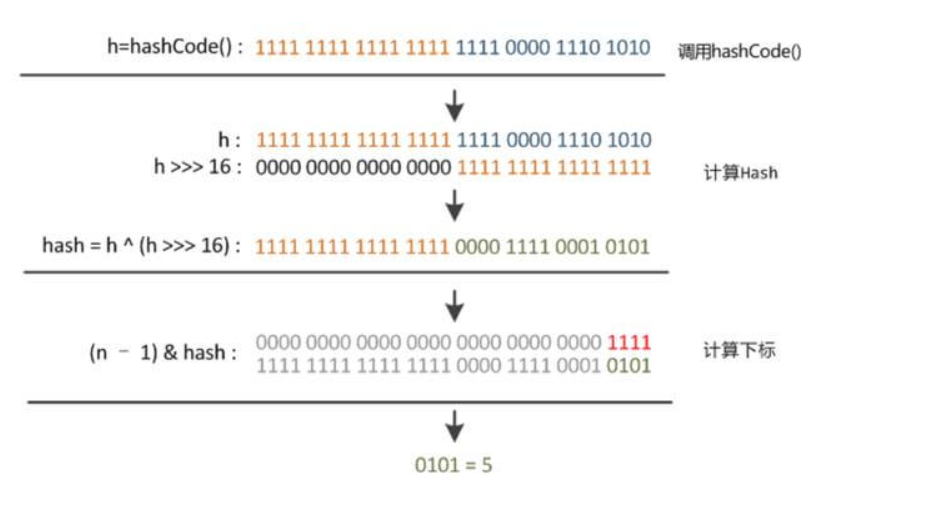
(2).数组槽位运算
(n-1)&hash本身hash计算是取模计算,但是当且仅当数组长度是2的n次方时,使用&运算替代%运算可以提高效率。&比%效率更高
(3).put方法的操作流程
1.根据key计算hashcode,hashcode=hash(key)
2.使用Hash函数计算存储位置: index=mod(hashcode),对hashMap的容量取模
3.拿着index找到HashMap结构数组中的位置。
(1)数组该位置为null或空: array[i]=null, 直接创建新节点,插入数据
(2)数组该位置不为null或空:
HashMap采用拉链法解决hash冲突
(a.)链表结构:
<8时遍历链表,创建新节点,头插法插入,
=8时遍历链表,头插法插入新节点后,将其转换为红黑树
(b.)红黑树结构:(>8)遍历红黑树,创建新节点,插入新节点
若该key值已存在hashMap结构中,则对其值进行覆盖。
节点中存储的结构为Entry: key-value键值对结构
4.插入成功后:
当前HashMap结构中的节点数为size(HashMap含有的数据量大小)
size>threshold时,进行扩容。
threshold=容量*装填因子=Capacity * LoadFactor
LoadFactor:HashMap负载因子|加载因子,为了降低哈希冲突的概率,默认当HashMap中的键值对达到数组大小的75%时,即会触发扩容。
参考《【hashmap】HashMap原理及线程不安全详解|哈希表原理-CSDN博客》
参考《HashMap的实现原理,源码深度剖析! – mikechen》
(4).get方法的操作流程
1.根据key值计算hashcode,hashcode=hash(key)
2.对hashcode取模获得index,inde =mod(hashcode)
3.根据index找到Array的指定位置,此时可能匹配1-n个节点
4.遍历链表|红黑树的节点:获得一个节点的Entry结构,比较节点的key是否为查找到key
是,返回该节点
否,继续遍历
5.若遍历完都没找到要找的节点,则返回null
getOrDefault(key,默认值),找不到时返回指定默认值
(5).HashMap扩容
- 当且仅当 数据大小>装填因子*容量,时触发扩容。
如果不扩容,hash冲突的概率会逐渐提高,影响性能。
- HashMap初始容量16,每次扩容×2,保证容量是2的幂次。
- 扩容后所有元素需要重新计算位置:rehash()。
- 这是因为:当且仅当容量是2的幂次时,mod取模操作可以替换为&操作,计算更高效。
- 其次:容量是2的幂次,如16,二进制表示为1111。
- 其余hashcode作与操作,获得index index=hashcode&1111。
index = HashCode(Key) & (Length - 1)
index总是与最后四位有关系。
- 其总是忠诚的反应后几位的值,此时:只要hashcode本身是符合均匀分布的,则index是符合均匀分布的。符合均匀分布可以减少hash冲突的次数。
3.HashMap的锁与安全机制
(1).HashMap线程不安全-扩容死链
HashMap扩容并没有作线程安全的设置,故其是线程不安全的。会发生扩容死链,具体来说,如下:
扩容的两大步骤: 扩容、rehash, 扩容死链是在rehash时发生的。
假如:HashMap初始容量为16,装填因子0.75,当且仅当大于16*0.75=12时,触发扩容。
此时,HashMap中有12个数据,再加入一个数据时,会出发扩容。
此时,线程A和B同时加入一个新数据,此时,触发扩容。
A扩容 B扩容: 创建扩容后的新数组
扩容的下一步是rehash操作,重新对数据进行分布。重新把元组加入到扩容后的数组上。
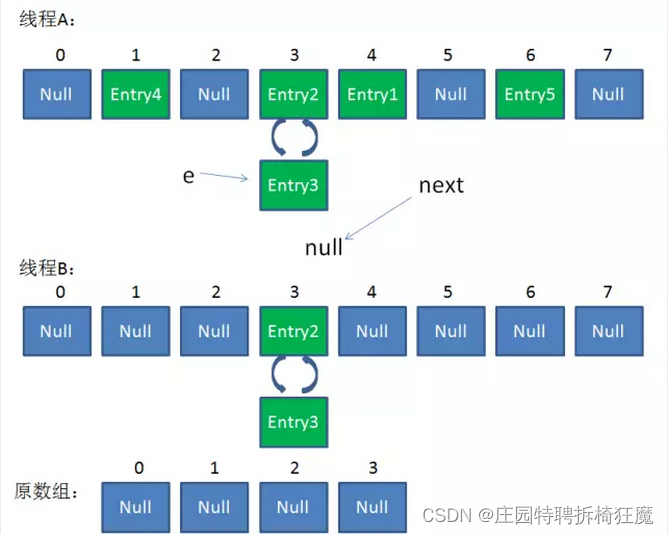
1.线程B遍历到Entry3对象,执行完语句1,线程就被挂起。
e = Entry3
next = Entry2
2.线程A畅通无阻地进行着Rehash,也执行了语句1:
e = Entry3
next = Entry2
3.次数于语句2的i=3,对于两个线程来说都是正确的。
4.此时采用头插法将元素进行插入时,有:
A线程执行:
e.next=newTable[i]: 将Entry2指向Entry3
newTable[i]=e: 将Entry2放入newTable[i],此时完成头插法
e=next: 将Entry3的值赋值给e,此时: e=Entry3 next=Entry3
B线程执行:
e.next=newTable[i]: 此时newTable[i]里是Entry2, e是Entry3,则此时Entry3指向Entry2
newTable[i]=e: 此时将Entry3再次放入newTable[i]
e=next: 此时Entry再次放入e中
由于:
Entry2指向Entry3,同时存在Entry3指向Entry2,形成环形结构,get查找指定数据时,会形成死循环。

(2)ConcurrentHashMap如何保证线程安全
- JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,主要实现原理是实现了锁分离的思路解决了多线程的安全问题
- JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本.
- JDK1.7版本的ReentrantLock+Segment+HashEntry
- JDK1.8版本中synchronized+CAS+HashEntry+红黑树
摘自《HashMap和ConcurrentHashMap的区别,详解HashMap和ConcurrentHashMap数据结构-CSDN博客》
(a).JDK1.7 ConcurrentHashMap锁分离的线程安全机制
JDK1.7 ConcurrentHashMap锁分离的线程安全机制:
其结构:一个Segment数组和多个HashEntry
ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Segment里面的Entry,然后在遍历entry链表.
即:ConcurrentHashMap经历两次Hash, 而HashMap只有一次Hash
摘自《HashMap和ConcurrentHashMap的区别,详解HashMap和ConcurrentHashMap数据结构-CSDN博客》
1.第一次hash,找到Segment对应位置
Segment数组:
将一个大的table分割成多个小的table来进行加锁——锁分离技术
每一个Segment元素存储的是HashEntry数组+链表,(和HashMap结构一致)
Segment数组如何设置:
初始化:通过位与运算来初始化,用ssize来表示, ssize也是2的幂次,
DEFAULT_CONCURRENCY_LEVEL =16,限制了Segment的大小最多65536个
Segment的大小默认16
2.第二次hash,找到对应键值对
每一个Segment元素下的HashEntry的初始化也是按照位与运算来计算,用cap来表示
HashEntry相当于HashMap结构,其容量是2的幂次(cap <<=1)
HashEntry最小的容量为2
put方法:
Segment继承了ReentrantLock ,也就带有锁的功能
1.第一次hash1(key)确定segment位置
若segment未初始化,则CAS操作赋值
2.第二次hash2(key),确定HashEntry的位置
此处的操作受Segment继承的ReentrantLock影响
线程试图获取锁:
成功获取锁: 插入数据
失败,其他线程占有锁:自旋的方式获取锁,超过指定次数挂起,等待唤醒
get方法和hashmap没有太大差别,只是经历了两次hash计算
size方法:由于并发操作,可能获取的size和真实值不一致。
解决方案: 不加锁的模式下多次获取,三局两胜,最多三次
上述不成功,则给每个Segment加上锁,计算size并返回.



(b).JDK1.8 Synchronized和CAS来操作的线程安全机制
摘自《HashMap和ConcurrentHashMap的区别,详解HashMap和ConcurrentHashMap数据结构-CSDN博客》
结构:Node数组+链表+红黑树,其实就是针对红黑树的引入进行了修改
Node数据结构很简单,就是一个链表,但是只允许对数据进行查找,不允许进行修改
TreeNode继承于Node,但是数据结构换成了二叉树结构,它是红黑树的数据的存储结构,用于红黑树中存储数据,当链表的节点数大于8时会转换成红黑树的结构
摘自《HashMap和ConcurrentHashMap的区别,详解HashMap和ConcurrentHashMap数据结构-CSDN博客》



4.知识点补充
CAS:
CAS是
Compare-And-Swap(比较并交换)的缩写,是一种轻量级的同步机制,主要用于实现多线程环境下的无锁算法和数据结构,保证了并发安全性。它可以在不使用锁(如synchronized、Lock)的情况下,对共享数据进行线程安全的操作。
自旋锁:
自旋锁是一种用于多线程编程的同步机制。它通过循环检查锁的状态来实现线程的等待和唤醒,而不是像互斥锁那样将线程阻塞。当一个线程尝试获取自旋锁时,如果锁已经被其他线程占用,该线程会一直循环检查锁的状态,直到锁被释放为止。
自旋锁的优点是在锁竞争不激烈的情况下,可以避免线程切换带来的开销,从而提高程序的性能。但是在锁竞争激烈的情况下,自旋锁可能会导致大量的空转,浪费CPU资源。
在实现上,自旋锁通常使用原子操作来实现对锁状态的操作,确保操作的原子性和线程安全性。
ReentrantLock:
ReentrantLock(可重入的独占锁)是Java中的一个线程同步机制,它提供了与synchronized关键字类似的功能,但更加灵活和可扩展。ReentrantLock实现了Lock接口,可以用于实现更复杂的线程同步需求。
ReentrantLock的特点包括:
- 可重入性:同一个线程可以多次获取同一个锁,而不会造成死锁。
- 公平性:可以选择公平锁或非公平锁。公平锁会按照线程请求的顺序来获取锁,而非公平锁则允许插队。
- 条件变量:可以使用Condition对象来实现线程间的等待和通知机制。
- 中断响应:支持线程的中断响应,即在等待锁的过程中可以响应中断信号。
使用ReentrantLock需要注意以下几点:
- 在获取锁后,必须在finally块中释放锁,以确保锁的释放。
- 可以使用tryLock()方法尝试获取锁,如果获取失败则可以进行其他操作,而不是一直等待。
- 可以使用lockInterruptibly()方法来获取锁,在等待锁的过程中可以响应中断信号。
















 1885
1885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









